
Guest post originally published on the Nethopper blog by Chris Munford

Like many people, I managed my first cluster using the kubernetes cli (aka kubectl). I deployed a handful of ‘objects’ such as deployments, secrets, configmaps, and services by directly applying yaml files, such as:

With much trial and error, I finally got my local yaml files perfect, and could issue these commands and produce a working app almost every time.
Then, I added another few clusters for staging and production… and the number of commands tripled.
Then, I added another app… and the number of files and commands doubled again.
Then, I needed to upgrade my apps… and I had to change all the files and reissue all the commands again, for every upgrade.
Of course, as a human being, I made mistakes. Many of them caused my apps and/or certain features, and/or users to break. So, in order to troubleshoot my broken apps, I needed to learn and issue a whole lot of other kubectl commands, such as:

There had to be a better way. How could I automate this and remove the human error and overhead? Being an engineer and having written some diagnostic scripts in the past, I was seriously considering writing a set of scripts to automate these procedures, so I (and my future team) would stop making avoidable mistakes. After all, scripts would make ‘pushing’ a large number of commands to my ‘kubectl’ terminal easier. I also considered helm and Kustomize, but this didn’t solve the problem, as it still required that I push updates to various charts in addition to the kubectl terminals.
One day, I read an article about ArgoCD focused on the difference between ‘pushing’ and ‘pulling’ configuration, and the lightbulb went off for me. I should not be ‘pushing’ commands, or scripts, or chart updates. These approaches will always require human action in every cluster, for every app, all monitoring, and every upgrade.
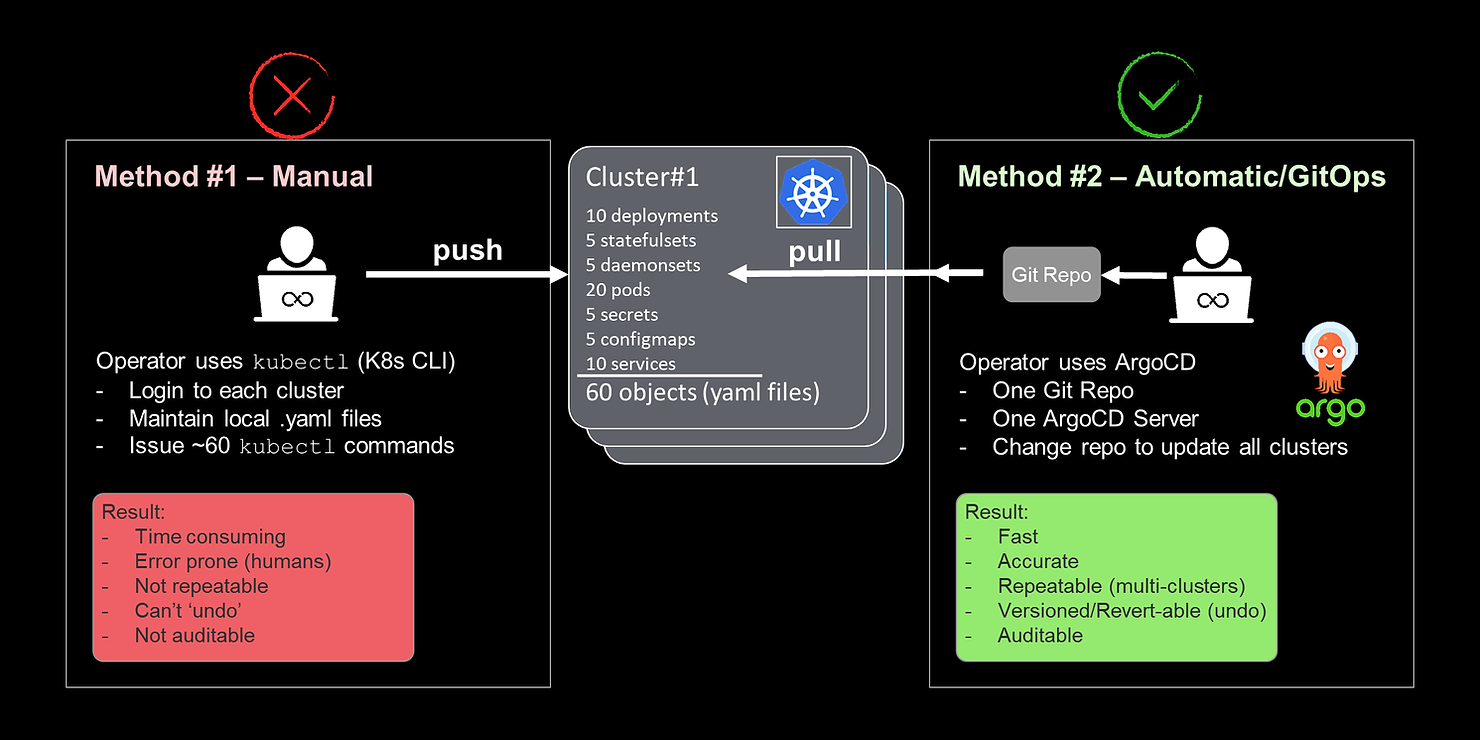
Instead, I should be ‘pulling’ information from a single source of truth to the K8s clusters. In other words, create an agent in the cluster that listens to the source of truth (desired state of the application) and issues the commands robotically. Robots are much better at pushing commands then humans. With the pull approach, all my apps and all my clusters will behave exactly as I expect, with no further human error. When daily or weekly upgrades occur, I simply had to upgrade the desired state in one place, and all apps in all clusters would update automatically. This was the automation tool that I was searching for. As I read on, and eventually became an ArgoCD user, I realized that ArgoCD is the perfect robot for K8s app. ArgoCD takes this approach even further by putting that source of truth under source control, so I have an ‘undo’ button, and can audit the complete history of changes to my apps and clusters. GitOps is a much more robust, efficient and scalable model than any of the push models using kubectl.
So, if you are ‘pushing’ files, commands and/or charts to Kubernetes using the CLI, then you are probably doing it wrong. It’s fine to start with kubectl commands, but mission critical apps should be managed with GitOps.
There’s a better way, called ArgoCD, and it is ready for you to use, right now. So, join the GitOps revolution.
CTA: If you want to get started quickly, Nethopper will give you an ArgoCD server in seconds, just by signing up for a free account at mynethopper.com. Read more about it and the Documents at nethopper.io. We’ll help you attach your minikube(s), OpenShift, EKS, other clusters securely, so you can spend more time developing your apps, and less time operating them.