Guest post originally published on the Humanitec blog by Kaspar von Grünberg
A Platform Orchestrator sits at the core of a dynamic Internal Developer Platform. It enables dynamic configuration management and developer self-service, allowing for low cognitive load on engineers. It drives standardization by design and has a vastly positive impact on the productivity and health of engineering organizations.
Introduction
A Platform Orchestrator is the centerpiece of a dynamic Internal Developer Platform (IDP). Whenever an adjacent CI pipeline notifies the orchestrator of a new build, the orchestrator reads the Declarative Application Model, generates a representation of the application together with its dependent resources and deploys it.
This enables dynamic configuration management and developer self-service, while driving standardization by design. The impact on the productivity and health of engineering organizations is massive.
In this article we want to analyze in detail what Platform Orchestrators are, where they fit in, how they work and what the benefits are.
Why you need a “baking machine”
To derive why we need a Platform Orchestrator we’ll need to take a step back and understand the shortcomings of the YAML-CI-CD workflow that you are likely familiar with today. The setup you are almost certainly running today is what we call a “static” setup. “Static” because of the applied approach of configuring app and infrastructure statically on an environment to environment basis using YAML files and IaC files that are manually “localized” to the context (the environment for instance).
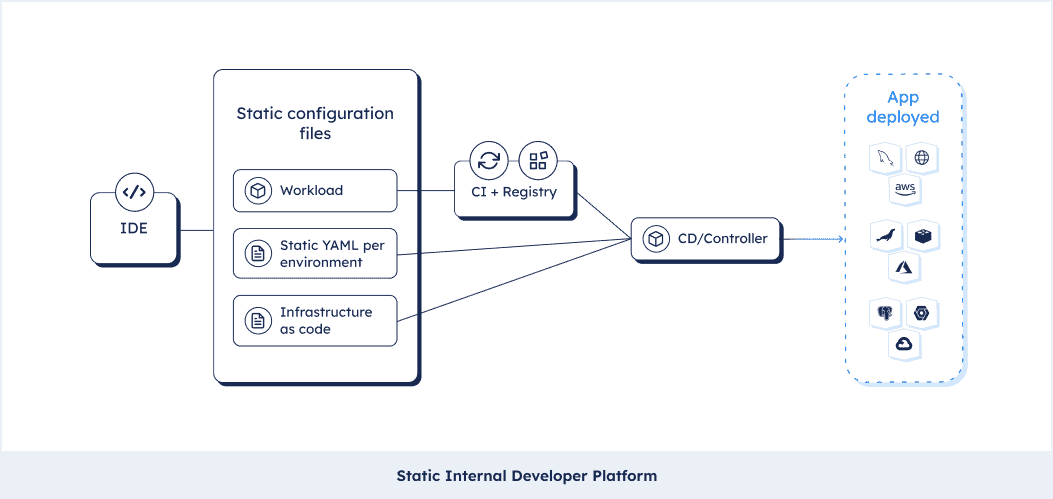
This setup is optimized on the action of updating an image into an architecture that’s already existing. It assumes that things that go beyond the simple update of an image (roll back, changes to the architecture, a new environment, etc.) are neglectable edge cases. That’s actually not true and such a static approach often drives config drift between environments, it is hard to maintain and makes standardization nearly impossible. This article dissects the approach in all detail.
To make the problem more digestible, picture the journey of baking a cake. A cake with clotted cream, strawberries and lots of other nice stuff. We need to deliver at least one cake really well so we bake a dev cake, a staging cake and the final production cake. It worked well, the cake is nice and shiny, we can update the strawberries as improved versions come along and everybody’s happy.

A day later our user calls us and tells us she has a severe strawberry allergy. So you and your team go to each cake and start picking out the strawberries and ship the production cake to your user. Now you hold your breath and pray you didn’t miss a berry.

Apart from your cake looking really ugly after this procedure, that’s a great example of what’s wrong with static config management. To resolve this against the real world, our cake is an application running in different environments. Its components are kept together by config files (YAML, or IaC such as Terraform, etc.) that are manually written for the context of the application in the respective environment. Everything is mingled together with little structure or consistency, in different places, by different people. That has a number of downsides:
- It’s hard to maintain
- It’s hard to standardize across teams
- It’s driving higher change failure rate
- It’s hard to operate and digest by a single person, as the tangled components make it hard to understand what fits together, in what way.
And while it’s fine if you bake a cake with a small team, if you have dozens of developers baking cakes it’s getting really hard to make sure you find the last strawberry.
The alternate approach is called dynamic configuration management. To stay with our baking analogy: rather than baking many cakes and searching for the strawberry, we just write a baking recipe and we add a description on how the cake varies between environments. We then bake the cake with every deployment from the ground up. This job is done by a baking machine and this baking machine in the context of cloud native is called a Platform Orchestrator.
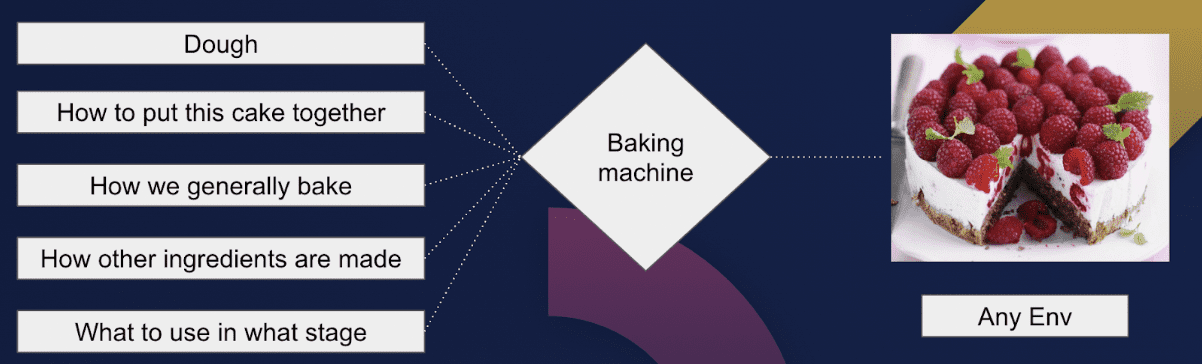
The baking recipe is what we call a Declarative Application Model. It basically pulls apart the environment agnostic from the environment specific elements of your configurations and ties app configs to infrastructure configs. If you haven’t had the chance to use it yet, this article goes into detail about it.
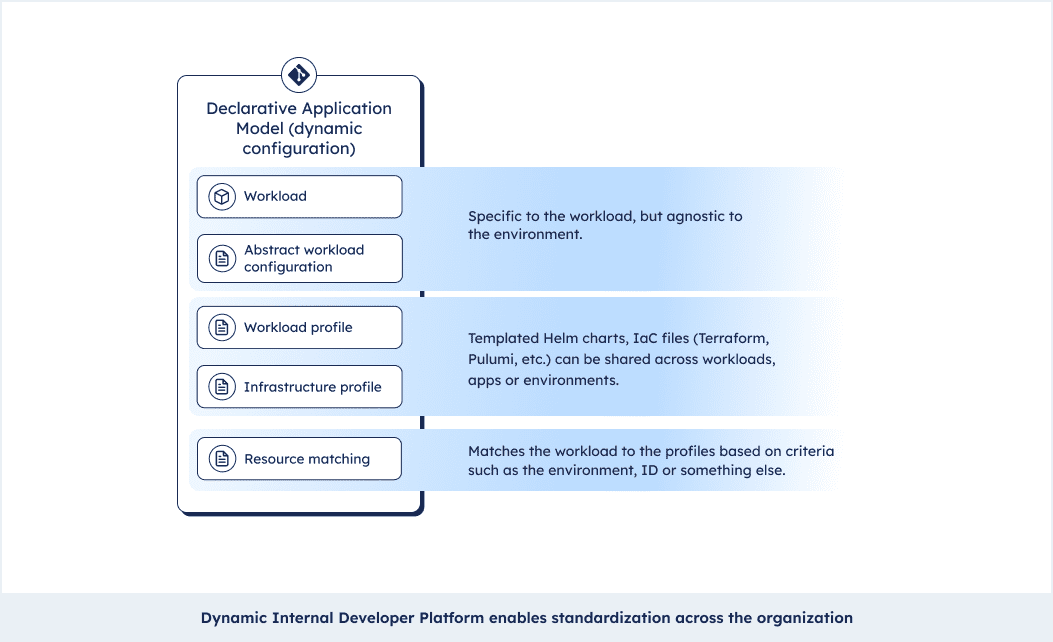
The Platform Orchestrator reads our baking recipe, the Declarative Application Model and bakes the cake, our application. This has lots of positives:
- As a developer you now don’t have to deal with every single part of the setup, you can just focus on the workload and the environment agnostic configurations (using open specifications such as paws.sh). This allows you to build applications from idea to production without depending on others.
- At the same time you as the developer have all the context you need. Platform teams can set profiles and matching criteria but you can see the underlying infrastructure as code. You can even send a pull request and change it!
- Setting profiles and sharing them across workloads and teams allows you to standardize practices across the organization, without aggressively enforcing them. Teams could, for instance, make sure labels and annotations for their APM suite make their way into all workloads. Or Hashicorp Vault should be starting up as a side car for every new workload. We call this standardization by design.
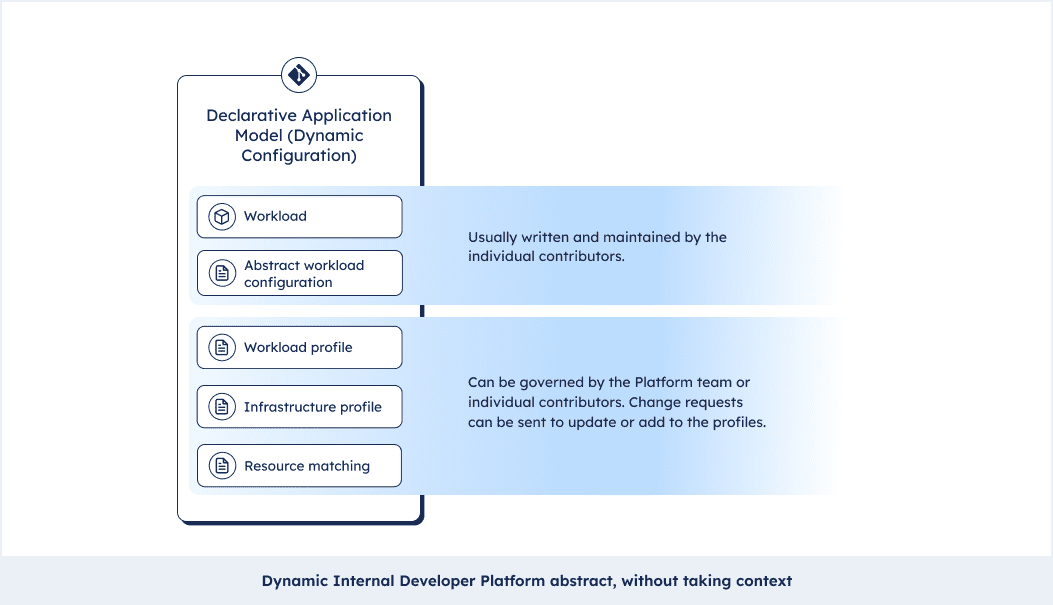
This also unleashes a wide array of features that were hard or impossible to get with a static setup. Things like:
- Rolling back to previous deployments with a single command
- Spinning up completely configured environments with a single command
- Applying architectural changes such as adding/removing a new service or resource or other dependencies and rolling them out to all environments fast
- Modeling applications and dependencies through a CLI, API, UI or code based
- Updating infrastructure and workload profiles in one place and rolling them out across the organization
- Packaging default services and resources as “Platform as Code” and getting your developers a lightning fast experience in spinning up new services + standard dependent resources with one command
- Using the central position of the orchestrator in the toolchain to aggregate data/logs etc. in one place
- Applying fine grained Role Based Access Control (RBAC) to various stages of the delivery cycle
What happens (in detail) if you deploy with a Platform Orchestrator?
We learned that the orchestrator takes the Declarative Application Model and bakes the cake. But let’s follow the trail in detail. Note that this differs from orchestrator to orchestrator, but the example we’re taking is pretty common (taken from the growing but still small amount of dynamic Internal Developer Platforms out there). Let’s assume we are deploying a workload into an EKS cluster that connects to a Postgres with RDS and is exposed through DNS to the public internet. We will now deploy this application against an environment of type “development”. Let’s also assume this is the first deployment in this environment, so the resources do not exist yet. This is what will happen:
- The CI pipeline builds an image and pushes it to an image registry (say ECR). The build notification from the pipeline informs the orchestrator that it’s time to bake and deploy.
- The orchestrator reads the latest changes to the Declarative Application Model creates manifests.
- It uses the manifests and runs them against kubectl to configure Kubernetes.
- Next it looks up what infrastructure profile to use for the environment context, which in our case is “development”.
- In our case the infrastructure profile is using Terraform to create a database in an existing Postgres instance, a new namespace in EKS and a new DNS with Route53.
- It will receive the credentials from the resources and inject them into the containers as secrets at run-time.
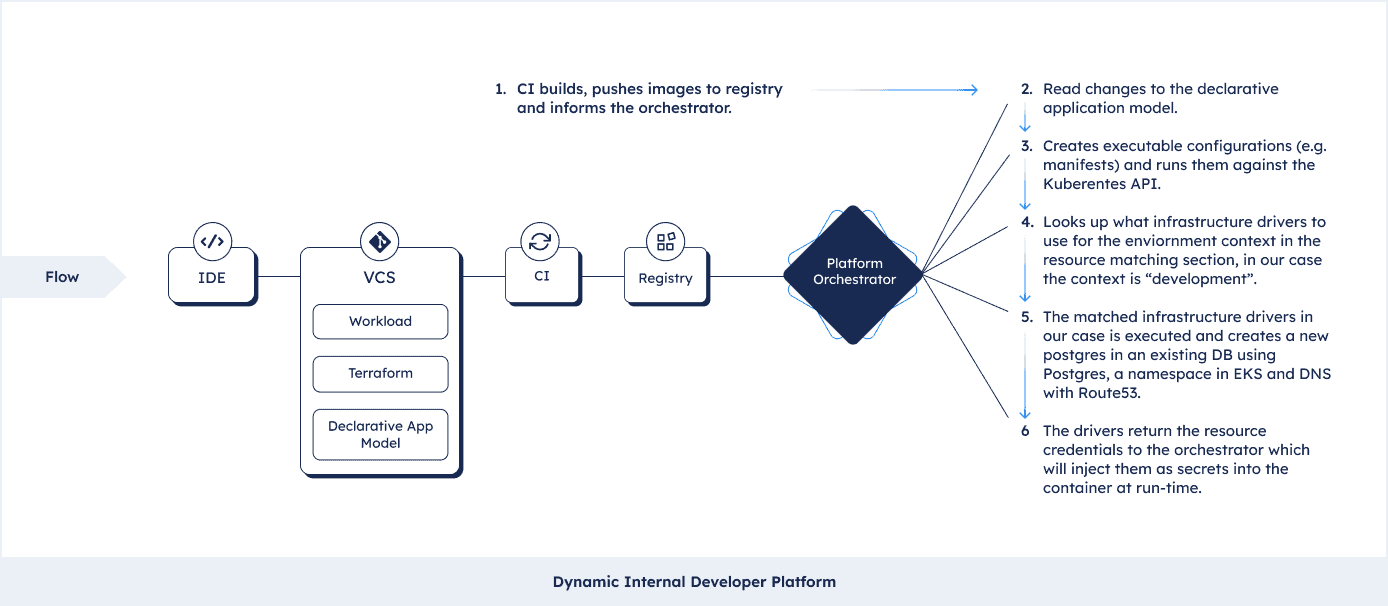
And that’s it, the new representation (the executable configuration like manifests and IaC modules) of your application is created and the app is deployed.
Interfaces into your Platform Orchestrator
One of the powerful features of a Platform Orchestrator is that it acts as an API layer that can hook into almost all parts of the delivery chain. In the end both application and infrastructure configurations go through the orchestrator, which means it has a pretty unique view into a lot of things. This means there are a number of interfaces organizations use in combination with a Platform Orchestrator to visualize the process and help developers in setting up and operating applications.
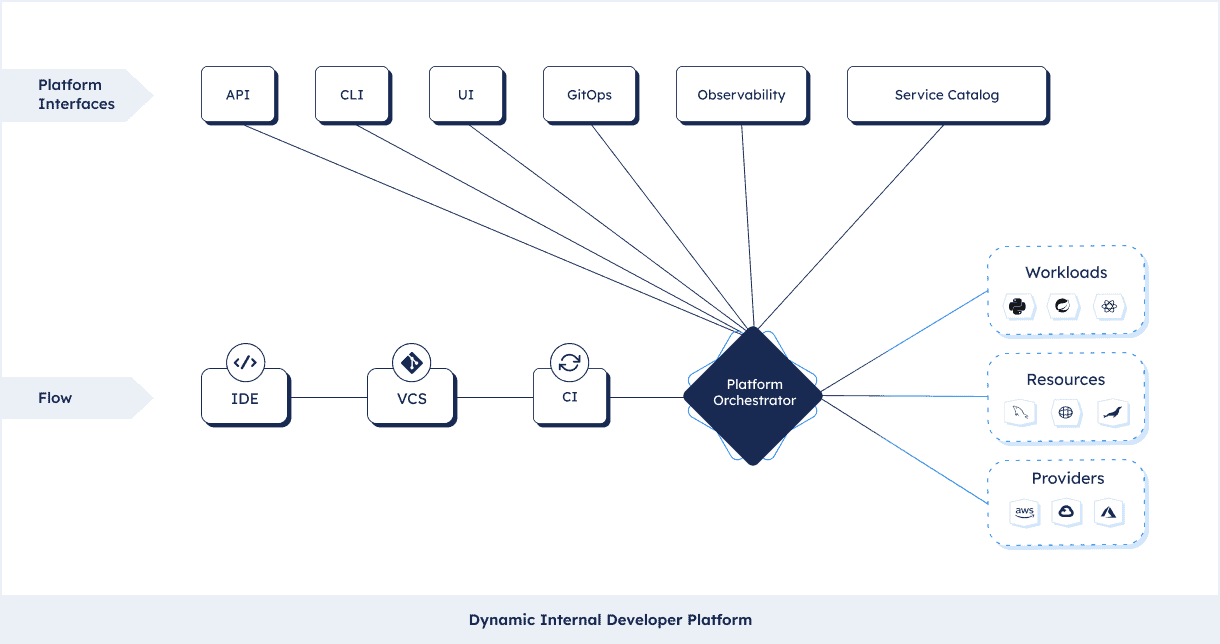
Interfaces can be API based or fully code-based, following the GitOps methodology. Some orchestrators interface with dedicated CLIs and some UIs to visualize and run your application operations. The orchestrator can be wired up with your APM suite and service catalogs to visualize and log your services, link the repository and much more. Backstage, a prominent open source project in the service catalog space is often used in combination with a Platform Orchestrator.
Summary
Platform Orchestrators are the pulsating heart of any dyamic Internal Developer Platform. They are the core engine that allows engineering organizations to manage application and infrastructure configurations dynamically. This enables developer self-service, without creating extra cognitve load on teams.
Using a Platform Orchestrator, organizations move away from static setups and can now orchestrate deployments and infrastructure provisioning in harmony. Configuration baselines let them drive standardization by design, abstracting complexity away from developers, yet without removing the necessary context in their delivery workflows.
If you’d like to explore this further, Humanitec’s Platform Orchestrator can be easily set up for your engineering organization in the matter of hours. Talk to our engineers to learn more.