


Guest post originally published on Timescale’s blog by James Blackwood-Sewell

Welcome to the third and final post of our series about metrics. First, we deep-dived into the four types of Prometheus metrics; then, we examined how metrics work in OpenTelemetry; and finally, we are now putting the two together—explaining the differences, similarities, and integration between the metrics in both systems.
We decided to round off the series by comparing the metrics in both tools because we believe this is a choice you’ll need to make sooner rather than later. While Prometheus has been the current standard for monitoring your systems, OpenTelemetry is quickly gaining ground, especially in the cloud-native landscape, which was traditionally Prometheus’ stronghold. OpenTelemetry’s promise of creating a unified standard among traces, logs, and metrics with enough flexibility to model and interact with other approaches is tempting many developers.
After working with both frameworks, our goal with this blog post is to compare the two, show you how to transform one into the other, and share some thoughts on which may be more appropriate, depending on your use case.
Metrics in Prometheus vs. OpenTelemetry: Common Ground
Both systems allow you to collect and transform metrics (although Open Telemetry is much more flexible as a transformation pipeline). However, looking back at the previous articles, we need to remember an important distinction: Prometheus is an Observability tool (including collection, storage, and query) that uses a metric model designed to suit its own needs.
On the other hand, the metrics component of OpenTelemetry translates from many different data models into one single framework (providing collection with no storage or query). These core differences reflect the systems’ complexity—Prometheus is a straightforward model which is often exposed in text, while OpenTelemetry is a more intricate series of three models which uses a binary format for transmission.
Both systems also allow code instrumentation via an SDK, but OpenTelemetry also focuses on supporting automatic instrumentation, which does not add any code to applications (where possible).
So what’s the overlap between the metrics you can create? Essentially, OpenTelemetry allows the representation of all Prometheus metric types (counters, gauges, summaries, and histograms). Still, Prometheus can’t represent some configurations of OpenTelemetry metrics, including delta representations and exponential histograms (although these will be added to Prometheus soon), as well as integer values.
In other words, Prometheus metrics are a strict subset of OpenTelemetry metrics.
Main Differences
While there are some differences in how the internal models work (read on for more information), the practical differences between the two from a developer’s point of view are more to do with the ecosystem.
Prometheus provides metric collection, storage, and query. It generally gathers metrics via a simple scraping system that pulls data from hosts. The Prometheus database stores that data, which you can then query with the Prometheus query language, PromQL. The Prometheus database can handle a lot of data, but it’s not officially meant to be a long-term storage solution, so data is often sent to another storage solution—like Promscale— after some time but still read back via PromQL.
OpenTelemetry has a much smaller scope. It collects metrics (as well as traces and logs) using a consolidated API via push or pull, potentially transforms them, and sends them onward to other systems for storage or query. By only focusing on the parts of Observability which applications interact with, OpenTelemetry is decoupling the creation of signals from the operational concerns of storing them and querying them. Ironically, this means OpenTelemetry metrics often end up back in Prometheus or a Prometheus-compatible system.
When we are looking at actual metric types, there are several differences:
- OpenTelemetry can represent metrics as deltas rather than as cumulative, storing the difference between each data point rather than the cumulative sum. Prometheus does not allow this by design (although you can calculate the values at query time). This isn’t the default in OpenTelemetry and would mainly be used for metrics that would only ever be expressed as rates.
- OpenTelemetry also allows metric values to be integers rather than floating-point numbers, which Prometheus can not express.
- OpenTelemetry can attach some extra metadata to histograms, allowing you to track the maximum and minimum values.
- Finally, OpenTelemetry has an exponential histogram aggregation type (which uses a formula and a scale to calculate bucket sizings). Prometheus can not represent this today, but does have a fully compatible metric type in the works!
Choosing Between the Two
If you don’t already have an investment in one of the two technologies, the choice between Prometheus and OpenTelemetry might boil down to four questions:
- Are you planning on capturing traces, logs, and metrics? If so, OpenTelemetry will allow you to use the same libraries to instrument across all three signal types, which is a significant benefit. You can even send all three signals to the same backend and use a single language to query across them (for example, Promscale and SQL).
- Do you value stability and battle-tested systems? If so, Prometheus might be the correct answer for a few more years as OpenTelemetry gets production exposure.
- Would you like to use a multi-step routing and transformation pipeline? If so, perhaps OpenTelemetry might be worth a look.
- Do you want to be able to stay as flexible as possible? Then OpenTelemetry is for you, as it doesn’t implement any storage or query, giving you maximum flexibility.
Most organizations will likely mix both standards: Prometheus for infrastructure monitoring, making use of the much more mature ecosystem of integration to extract metrics from hundreds of components, and OpenTelemetry for services that have been developed. Many engineers will probably use Prometheus as a backend to store both Prometheus and OpenTelemetry metrics, and will need to ensure the OpenTelemetry metrics they produce are compatible with Prometheus.
In practice, this means opting for the cumulative aggregation temporality and only using OpenTelemetry metric types supported by Prometheus (leaving aside OpenTelemetry exponential histograms until Prometheus adds support for these).
Converting Between Prometheus and OpenTelemetry
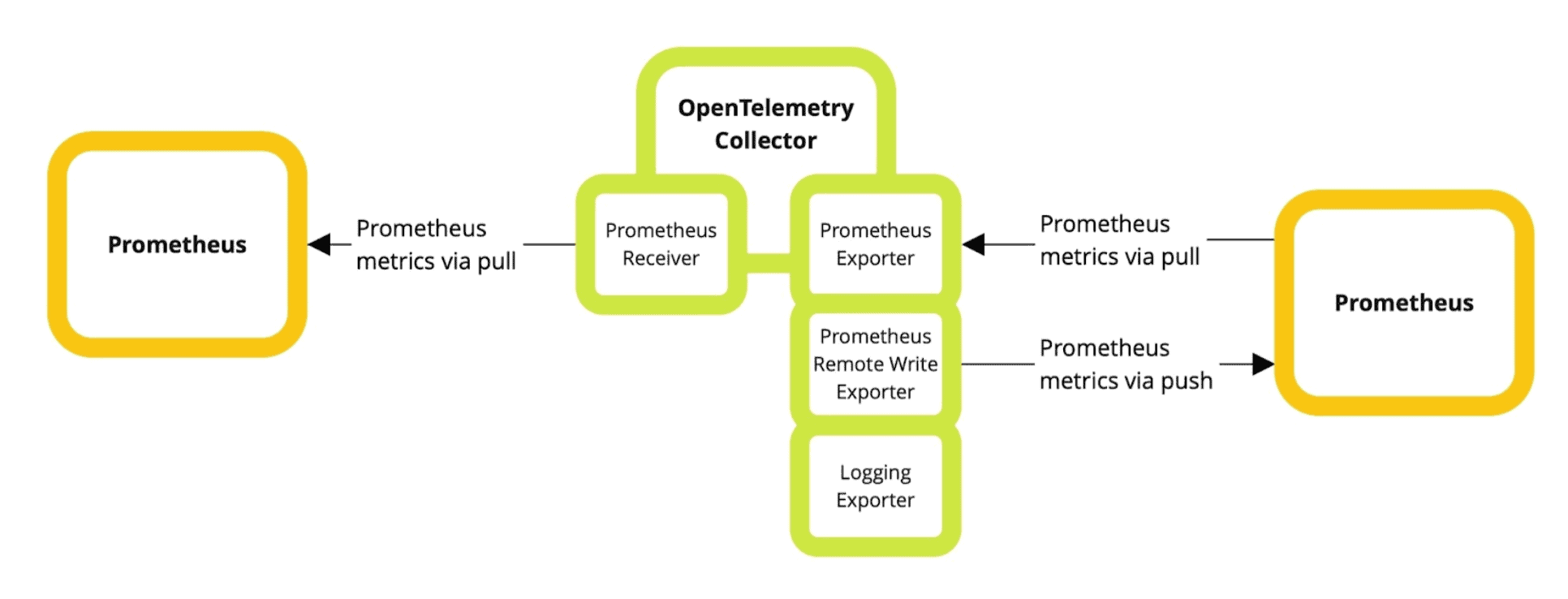
If you want to mix and match the standards, then the good news is that OpenTelemetry provides the OpenTelemetry Collector, which can help with moving in both directions (even casting between types if needed in some cases).
The OpenTelemetry Collector is pluggable, allowing both receivers and exporter components to be enabled using a config file at runtime. We will be using the contrib package that includes many receivers and exporters. You can download the appropriate binary from the GitHub Release pages. Alternatively, if you’re running the collector in production, you can also compile a version containing just the components you need using the OpenTelemetry Collector Builder.
For the examples in the following sections, we are running the collector with the following config file which is saved as config.yaml:
receivers:
prometheus:
config:
scrape_configs:
- job_name: demo
scrape_interval: 15s
static_configs:
- targets: ['localhost:9090']
exporters:
prometheus:
endpoint: "0.0.0.0:1234"
logging:
loglevel: debug
service:
telemetry:
logs:
level: debug
pipelines:
metrics:
receivers: [prometheus]
processors: []
exporters: [logging,prometheus]
Then we start the collector with:
otelcol –config config.yaml
The collector will use the Prometheus receiver to try to scrape a Prometheus service at http://localhost:9100. If you need something to test with, you could start a local node_exporter that uses this port. As data is scraped from this service, you will see it show up as log output from the collector, and it will also be available from the Prometheus exporter endpoint, which the collector will run on http://localhost:1234.
The Prometheus Remote Write Exporter is also an option, but it’s more limited in scope at this stage, only being able to handle cumulative counters and gauges.
If we look back to our previous post on Prometheus metrics, we covered the four main metric types: counters, gauges, histograms, and summaries. In the Prometheus context, a counter is monotonic (continuously increasing), whereas a gauge is not (it can go up and down).
If you’re really on point, you’ll also remember that the difference between a histogram and a summary is that a summary reports quantiles and doesn’t require as much client computation. A histogram, on the other hand, is more flexible, providing the raw bucket widths and counts.
OpenTelemetry, in contrast, has five metric types: sums, gauges, summaries, histograms, and exponential histograms. If you’ve been following along with the how metrics work in OpenTelemetry post, you will have a question at this stage—are these different types from what we have previously seen? The answer to this question lies in the three OpenTelemetry models.
If you are a developer creating OpenTelemetry metrics, you deal with the Event model, which is then translated (for transmission) to the OpenTelemetry Protocol (OTLP) Stream Model by the OpenTelemetry SDK. The types we are referencing here are part of this model, which the Prometheus receiver translates directly into.
Luckily, these new metric types are self-explanatory and map directly onto the Prometheus metric types (summary is implemented only for Prometheus compatibility, and you won’t see it used elsewhere). The exception is the exponential histogram, which can’t be converted to Prometheus today (but will be able to be converted in the future). The diagram below describes how the mappings work in each direction.
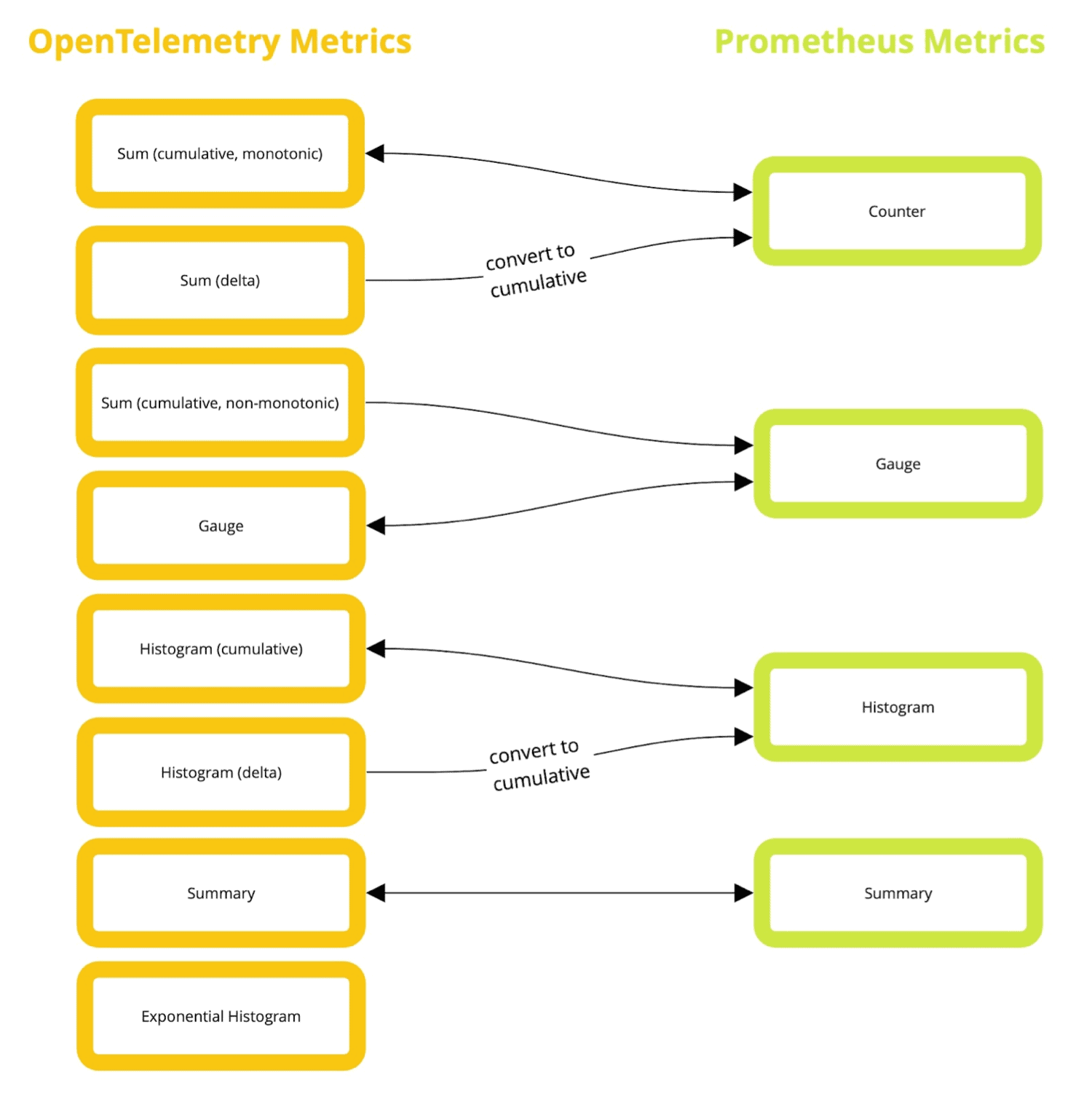
OpenTelemetry promises lossless conversions to and from Prometheus metrics, giving users the ability to convert as they need without worrying about data loss.
Converting From Prometheus to OpenTelemetry
Let’s explore how the Prometheus to OpenTelemetry conversions work by looking at examples of Prometheus scrapes and OpenTelemetry metrics. While OpenTelemetry doesn’t have a text representation like Prometheus, we can use the Logging Exporter to emit a text dump of the metrics captured.
OpenTelemetry will extract some information from the scrape itself and store this, producing the following output, which defines Resource labels that will be attached to all metrics.
Resource SchemaURL:
Resource labels:
-> service.name: STRING(node-exporter)
-> service.instance.id: STRING(127.0.0.1:9100)
-> net.host.port: STRING(9100)
-> http.scheme: STRING(http)
Counters
If we take the following Prometheus scrape data and point the collector at it:
# HELP http_requests_total Total HTTP requests served
# TYPE http_requests_total counter
http_requests_total{method="post",code="200"} 1028
http_requests_total{method="post",code="400"} 5
Then the collector would output the following metric from the Logging Exporter.
Metric #0
Descriptor:
-> Name: http_requests_total
-> Description: Total HTTP requests served
-> Unit:
-> DataType: Sum
-> IsMonotonic: true
-> AggregationTemporality: AGGREGATION_TEMPORALITY_CUMULATIVE
NumberDataPoints #0
Data point attributes:
-> code: STRING(200)
-> method: STRING(post)
StartTimestamp: 2022-06-16 11:49:22.117 +0000 UTC
Timestamp: 2022-06-16 11:49:22.117 +0000 UTC
Value: 1028.000000
NumberDataPoints #1
Data point attributes:
-> code: STRING(400)
-> method: STRING(post)
StartTimestamp: 2022-06-16 11:49:22.117 +0000 UTC
Timestamp: 2022-06-16 11:49:22.117 +0000 UTC
Value: 5.000000
We can see that the metric type ( DataType) is Sum and the AggregationTemporality is Cumulative (the only aggregation that Prometheus supports). There are two timestamps per data point to track counter resets: Timestamp is the time of the recording, and StartTimestamp is either the time the first sample was received or the time of the last counter reset. There is no Unit specified. This is because Prometheus specifies units by including them as part of the textual metric name, which can’t be accurately decoded by the OpenTelemetry Collector. Interestingly, using the compatible OpenMetrics format to add a unit does not work either.
Gauges
If we take a Prometheus gauge and scrape it:
# HELP node_filesystem_avail_bytes Available bytes in filesystems
# TYPE node_filesystem_avail_bytes gauge
node_filesystem_avail_bytes{method="/data",fstype="ext4"} 250294We would see the following output from the collector.
Metric #0
Descriptor:
-> Name: node_filesystem_avail_bytes
-> Description: Available bytes in filesystems
-> Unit:
-> DataType: Gauge
NumberDataPoints #0
Data point attributes:
-> fstype: STRING(ext4)
-> method: STRING(/data)
StartTimestamp: 1970-01-01 00:00:00 +0000 UTC
Timestamp: 2022-06-23 07:42:07.117 +0000 UTC
Value: 250294.000000Here, the DataType is set to Gauge. Gauge is the default metric type OpenTelemetry will convert into, so the lack of a # TYPE line in the Prometheus scrape data will result in a gauge. Prometheus doesn’t actually use the type information itself (it doesn’t differentiate between counters and gauges internally), so some exporters will forgo the two comment lines to make the scrape more efficient. This would result in all OpenTelemetry metrics being gauges.
Histograms
A Prometheus histogram which was scraped as:
# HELP http_request_duration_seconds Histogram of latencies for HTTP requests.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{handler="/",le="0.1"} 25547
http_request_duration_seconds_bucket{handler="/",le="0.2"} 26688
http_request_duration_seconds_bucket{handler="/",le="0.4"} 27760
http_request_duration_seconds_bucket{handler="/",le="1"} 28641
http_request_duration_seconds_bucket{handler="/",le="3"} 28782
http_request_duration_seconds_bucket{handler="/",le="8"} 28844
http_request_duration_seconds_bucket{handler="/",le="20"} 28855
http_request_duration_seconds_bucket{handler="/",le="60"} 28860
http_request_duration_seconds_bucket{handler="/",le="120"} 28860
http_request_duration_seconds_bucket{handler="/",le="+Inf"} 28860
http_request_duration_seconds_sum{handler="/"} 1863.80491025699
http_request_duration_seconds_count{handler="/"} 28860Would present in OpenTelemetry through the Logging Exporter as:
Metric #0
Descriptor:
-> Name: prometheus_http_request_duration_seconds
-> Description: Histogram of latencies for HTTP requests.
-> Unit:
-> DataType: Histogram
-> AggregationTemporality: AGGREGATION_TEMPORALITY_CUMULATIVE
HistogramDataPoints #0
Data point attributes:
-> handler: STRING(/)
StartTimestamp: 2022-06-23 07:54:07.117 +0000 UTC
Timestamp: 2022-06-23 07:54:07.117 +0000 UTC
Count: 28860
Sum: 1863.804910
ExplicitBounds #0: 0.100000
ExplicitBounds #1: 0.200000
ExplicitBounds #2: 0.400000
ExplicitBounds #3: 1.000000
ExplicitBounds #4: 3.000000
ExplicitBounds #5: 8.000000
ExplicitBounds #6: 20.000000
ExplicitBounds #7: 60.000000
ExplicitBounds #8: 120.000000
Buckets #0, Count: 25547
Buckets #1, Count: 1141
Buckets #2, Count: 1072
Buckets #3, Count: 881
Buckets #4, Count: 141
Buckets #5, Count: 62
Buckets #6, Count: 11
Buckets #7, Count: 5
Buckets #8, Count: 0
Buckets #9, Count: 0We can see a histogram is created in OpenTelemetry, but one thing we can’t do is include minimum and maximum values (which OpenTelemetry supports, but Prometheus doesn’t).
Summaries
A Prometheus summary which is scraped as the following:
# HELP prometheus_rule_evaluation_duration_seconds The duration for a rule to execute.
# TYPE prometheus_rule_evaluation_duration_seconds summary
prometheus_rule_evaluation_duration_seconds{quantile="0.5"} 6.4853e-05
prometheus_rule_evaluation_duration_seconds{quantile="0.9"} 0.00010102
prometheus_rule_evaluation_duration_seconds{quantile="0.99"} 0.000177367
prometheus_rule_evaluation_duration_seconds_sum 1.623860968846092e+06
prometheus_rule_evaluation_duration_seconds_count 1.112293682e+09Would result in an OpenTelemetry metric which outputs via the Logging Exporter as:
Metric #3
Descriptor:
-> Name: prometheus_rule_evaluation_duration_seconds
-> Description: The duration for a rule to execute.
-> Unit:
-> DataType: Summary
SummaryDataPoints #0
StartTimestamp: 2022-06-23 07:50:22.117 +0000 UTC
Timestamp: 2022-06-23 07:50:22.117 +0000 UTC
Count: 1112293682
Sum: 1623860.968846
QuantileValue #0: Quantile 0.500000, Value 0.000065
QuantileValue #1: Quantile 0.900000, Value 0.000101
QuantileValue #2: Quantile 0.990000, Value 0.000177We can see that the OpenTelemetry Summary metric type has been selected here—remember that this was explicitly created for Prometheus integration and should not be used anywhere else. It’s similar to the histogram output but lists quantiles rather than explicit buckets and bucket counts. In this case, it looks like we are losing some precision, but fear not. This is just the Logging Exporter pretty-printing, as we will see in the next section.
Converting From OpenTelemetry to Prometheus
Using either the Prometheus Exporter to allow scraping or the Prometheus Remote Write Exporter to push directly to another Prometheus instance, we can transmit metrics from OpenTelemetry to Prometheus. There aren’t any surprises on this side: if the conversion is supported, it happens without any loss of precision.
One thing to remember is that there are some configurations of OpenTelemetry metrics that we can’t translate directly into Prometheus metrics because Prometheus has a much more constrained model.
Any metrics with an AggregationTemporality of DELTA will be converted back into CUMULATIVE by the Prometheus Exporter (and will be rejected by the Prometheus Remote Write Exporter). The Prometheus Remote Write Exporter will also reject summary and histogram metrics, but these are managed perfectly by the Prometheus Exporter. OpenTelemetry metrics with an integer value will be converted into float values.
For instance, a scrape from the Prometheus Exporter (when all the examples from the above sections have been ingested) would produce the following results. You will see that each value is exactly the same as the input Prometheus value from the previous sections, with no loss of fidelity.
# HELP http_request_duration_seconds Histogram of latencies for HTTP requests.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="0.1"} 25547
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="0.2"} 26688
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="0.4"} 27760
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="1"} 28641
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="3"} 28782
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="8"} 28844
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="20"} 28855
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="60"} 28860
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="120"} 28860
http_request_duration_seconds_bucket{handler="/",instance="127.0.0.1:9100",job="node-exporter",le="+Inf"} 28860
http_request_duration_seconds_sum{handler="/",instance="127.0.0.1:9100",job="node-exporter"} 1863.80491025699
http_request_duration_seconds_count{handler="/",instance="127.0.0.1:9100",job="node-exporter"} 28860
# HELP http_requests_total Total HTTP requests served
# TYPE http_requests_total counter
http_requests_total{code="200",instance="127.0.0.1:9100",job="node-exporter",method="post"} 907
http_requests_total{code="400",instance="127.0.0.1:9100",job="node-exporter",method="post"} 5
# HELP node_filesystem_avail_bytes Available bytes in filesystems
# TYPE node_filesystem_avail_bytes gauge
node_filesystem_avail_bytes{fstype="ext4",instance="127.0.0.1:9100",job="node-exporter",method="/data"} 250294
# HELP prometheus_rule_evaluation_duration_seconds The duration for a rule to execute.
# TYPE prometheus_rule_evaluation_duration_seconds summary
prometheus_rule_evaluation_duration_seconds{instance="127.0.0.1:9100",job="node-exporter",quantile="0.5"} 6.4853e-05
prometheus_rule_evaluation_duration_seconds{instance="127.0.0.1:9100",job="node-exporter",quantile="0.9"} 0.00010102
prometheus_rule_evaluation_duration_seconds{instance="127.0.0.1:9100",job="node-exporter",quantile="0.99"} 0.000177367
prometheus_rule_evaluation_duration_seconds_sum{instance="127.0.0.1:9100",job="node-exporter"} 1.623860968846092e+06
prometheus_rule_evaluation_duration_seconds_count{instance="127.0.0.1:9100",job="node-exporter"} 1.112293682e+09
# HELP scrape_duration_seconds Duration of the scrape
# TYPE scrape_duration_seconds gauge
scrape_duration_seconds{instance="127.0.0.1:9100",job="node-exporter"} 0.003231334
# HELP scrape_samples_post_metric_relabeling The number of samples remaining after metric relabeling was applied
# TYPE scrape_samples_post_metric_relabeling gauge
scrape_samples_post_metric_relabeling{instance="127.0.0.1:9100",job="node-exporter"} 20
# HELP scrape_samples_scraped The number of samples the target exposed
# TYPE scrape_samples_scraped gauge
scrape_samples_scraped{instance="127.0.0.1:9100",job="node-exporter"} 20
# HELP scrape_series_added The approximate number of new series in this scrape
# TYPE scrape_series_added gauge
scrape_series_added{instance="127.0.0.1:9100",job="node-exporter"} 20
# HELP up The scraping was successful
# TYPE up gauge
up{instance="127.0.0.1:9100",job="node-exporter"} 1When converting to Prometheus, keep in mind that we only have two options currently: one is using the Prometheus Exporter, which will mean all our data is exposed as a single scrape that won’t scale well if you have a large volume of series. The second option is using the Prometheus Remote Write Exporter, which we expect to scale better but is limited to counters and gauges and won’t perform DELTA to CUMULATIVE conversions (it will drop these metrics).
Decision Time
Summing up, Prometheus and OpenTelemetry provide metrics implementations with slightly different angles. While Prometheus is the de facto standard, covering metrics creation, storage, and query, OpenTelemetry is newer, covering only the generation of metrics. Still, it also supports traces and logs with the same SDK.
You can mainly convert between the two without any loss of precision—but it pays to know that some metric types will change slightly. For example, all OpenTelemetry DELTA metrics will be converted to CUMULATIVE before export as Prometheus metrics, and Prometheus cannot represent OpenTelemetry exponential histograms until they add support (which will hopefully be soon).
Most organizations will likely mix standards, but if you’re wondering which one to adopt, we recommend you weigh your priorities: do you value stability or flexibility? Are you planning to capture traces, logs, and metrics, or are you okay with metrics only?
Prometheus will give you a battle-tested system. OpenTelemetry, a more expansive and flexible standard. The final decision depends only on you, but we hope this blog post has given you some helpful clues.
And if you are looking for a long-term store for your Prometheus metrics, check out Promscale, the observability backend built on PostgreSQL and TimescaleDB. It seamlessly integrates with Prometheus, with 100% PromQL compliance, multitenancy, and OpenMetrics exemplars support.
- Promscale is an open-source project, and you can use it for free. Check out our docs for install instructions in Kubernetes, Docker, or your virtual machine.