















By Chris Aniszczyk (CNCF), Adam Korczynski (Ada Logics), David Korczynski (Ada Logics)
In this blog post we present an overview of the state of fuzzing across CNCF projects. This is based on efforts and work that CNCF has carried out in recent years in order to improve security and reliability of CNCF projects. The blog post will begin with a brief introduction to fuzzing and then proceed to highlight the CNCF projects being fuzzed, describe the fuzzing audits that have taken place, detail the results and impact of the work and, finally, discuss future work and conclude.
This blog post follows up on a talk recently presented at Cloud Native SecurityCon, Europe. Slides to this talk are available here and a recording of the talk is available here. Additionally, more details about CNCF fuzzing can be found in the CNCF-Fuzzing repository here.
Fuzzing introduction
In this section we will give a brief introduction to fuzzing. This is not meant to be an exhaustive or detailed description, but rather just enough to understand the key technical attributes of fuzzing, and in particular a brief argument as to why it works so well. The section also discusses how to perform continuous fuzzing of open source software by way of OSS-Fuzz.
Background
Fuzzing is a technique for testing software, whereby seemingly random data is passed onto a target application. During the fuzzing process, the target application is observed for crashes. The data being passed is often referred to as “random data”, although this is a bit misleading as the algorithms underlying fuzzing have elements of randomness but also a significant amount of structured reasoning, and the fuzzing algorithms are more accurately described as genetic mutational algorithms in contrast to random testing.
In the context of CNCF projects, the majority of fuzzing used is called coverage guided fuzzing. Coverage-guided fuzzing will execute a given target code over and over again for an arbitrary number of times. The code being tested is instrumented in a way that enables the fuzzer to observe whether a given input – which we call “a seed” – exercises new code paths of the application being tested. As such, the fuzzer will iteratively execute the target code and for each iteration will check if the seed exercises new code paths in the target code, and if so save the given seed. The total collection of saved seeds is called the corpus. At the beginning of each loop iteration the fuzzer will pick a random seed from its corpus and mutate it, which is where the mutations include an element of randomness. As seeds that generate new corpus are saved, the fuzzer builds up a larger and larger corpus the longer it runs. This also means, the longer the fuzzer runs, the more of the target code it will explore. We can visualise a modern coverage-guided fuzzer as shown in the following figure:
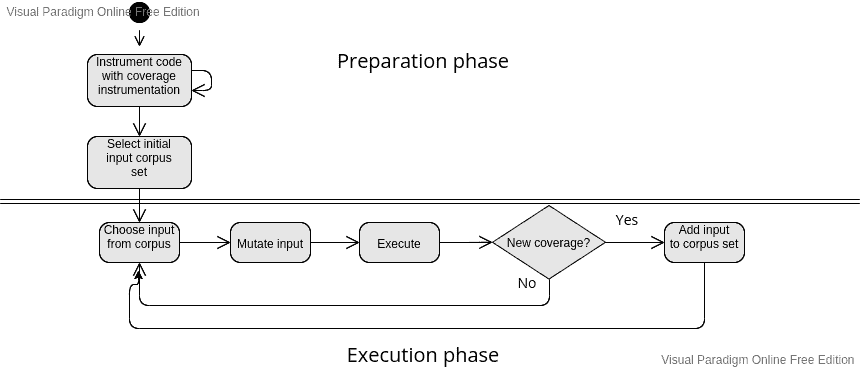
Goals of fuzzing
The goal of fuzzing is to check if any of the seeds generated by the fuzzer causes the application to behave in a buggy manner. As such, although the fundamental achievement of a fuzzer is to generate a corpus, the pragmatic goal of fuzzing is to find bugs. Some of these bugs have security implications and some are reliability bugs, and some bugs do not affect users at all, as fuzzers may be written in a way where the input is an over-approximation of what is actually possible input.
The type of bugs that can be found with fuzzing are dependent on the language in which the target application is implemented. A strong distinction is made between memory-safe and memory-unsafe languages. Memory-unsafe languages like C and C++ are often fuzzed to find memory corruption issues, and fuzzing is often combined with memory sanitizers to improve the ability to identify bugs at runtime. Memory-safe languages on the other hand are fuzzed for bugs like null-pointer dereferences, memory issues, time outs, uncaught exceptions and out of bounds issues.
Some applications are well suited for behavioural and differential fuzzing, whereby logical assertions are added as part of the fuzzer to check for unwanted behaviour in complex code. This type of fuzz-testing can be beneficial for both memory-safe and memory-unsafe languages.
Continuous fuzzing by way of OSS-Fuzz
It is a complex task to manage the infrastructure around running fuzzers. OSS-Fuzz is an open source project (https://github.com/google/oss-fuzz) that provides an automation platform for fuzzing critical open source projects. OSS-Fuzz handles the entire lifecycle of running fuzzers, reporting any issues found, deduplicating bugs, reporting when bugs are fixed and much more. Documentation on OSS-Fuzz can be found here: https://google.github.io/oss-fuzz/
CIFuzz is a sister project to OSS-Fuzz that enables fuzzing to run as part of the CI. The benefits of using CIFuzz is that the fuzzers will catch regressions before they’re merged, which is an added security technique in the workflow. Documentation on CIFuzz can be found here: https://google.github.io/oss-fuzz/getting-started/continuous-integration/
The CNCF projects we discuss in this blog post have all had the goal of integrating fuzzing by way of the OSS-Fuzz project.
Fuzzing CNCF projects
In this section we will go into details with the CNCF projects being fuzzed and related work efforts. As of June 2022, a total of 18 CNCF projects are being fuzzed continuously by OSS-Fuzz:
- Argo
- Cilium
- Cluster API
- Containerd
- CoreDNS
- CRI-O
- Distribution
- Envoy
- Etcd
- Fluent-bit
- Flux CD
- Helm
- Kubernetes
- KubeEdge
- Linkerd2 + proxy
- Prometheus
- Runc
- Vitess
These projects have had different approaches to introducing fuzz testing. For example, Prometheus was an early adopter of fuzzing in 2016 and later integrated into OSS-Fuzz in 2020. Similarly, Envoy started discussing adopting fuzzing in 2017 with a first fuzzer being added shortly thereafter. Envoy today has more than 50 fuzzers which have helped the project find hundreds of bugs.
The majority of projects being fuzzed are written in Go, but there are also several other projects written in C, C++ and Rust. In addition to these languages, OSS-Fuzz supports fuzzing of projects written in Java, Python and Swift, which leaves the door open for more CNCF projects to be fuzzed.
There is a large variety of projects being fuzzed. For example, Fluent-bit is a log processor, Envoy is a proxy, RunC is a container runtime, CRI-O is an implementation of the Kubernetes Container Runtime Interface, Argo is a declarative GitOps continuous delivery solution, and the list goes on. In essence, fuzzing has a broad audience and can be applied in many cases. For further details on what projects are suitable for fuzzing see more details on cncf-fuzzing.
Fuzzing audits
CNCF has commissioned more than ten security audits in recent years where the overall goal of these audits has been to improve continuous fuzzing of the given CNCF project. The way this goal was implemented for each audit differed, however, the most common approach is for projects that have had no prior fuzzing work done, where the goal has been:
- Set up the initial infrastructure for fuzzing
- Implement a number of fuzzers for the project
- Integrate the project with OSS-Fuzz
A report is written for each audit that documents the engagement, and a summary for several of these audits is given in the following:
Fluent-Bit
CNCFs logs and metrics processor is written in C. In its fuzzing audit, 16 fuzzers were written and more than 30 bugs were found of which 20 had security relevance. The project was integrated into OSS-Fuzz and the fuzzers still run continuously.
Full audit report: https://github.com/fluent/fluent-bit/blob/master/doc-reports/cncf-fuzzing-audit.pdf
runC and Umoci
The low level container runtime runC and the Umoci project underwent a fuzzing audit. 17 fuzzers were written. runC was integrated into OSS-Fuzz. Umoci did not qualify for integration. No bugs were found during this audit.
Full audit report: https://opencontainers.org/documents/Umoci_and_RunC_fuzzing_report.pdf
Linkerd2-proxy
In this audit, the goal was to add fuzz coverage of Linkerd2-Proxy and its most critical dependencies. The work resulted in 8 projects being integrated into OSS-Fuzz. 14 fuzzers were written, 7 of these covered Linkerd2-Proxy and the remaining covered dependencies. 2 bugs were found in Linkerd2-Proxy and several were found in the audited dependencies.
Full audit report: https://github.com/linkerd/linkerd2-proxy/blob/main/docs/reports/linkerd2-proxy-fuzzing-report.pdf
Envoy
The focus on Envoys fuzzing audit was to improve the existing and already mature fuzzing suite.
Full audit report: https://github.com/envoyproxy/envoy/blob/main/docs/security/audit_fuzzer_adalogics_2021.pdf
Vitess
The audit for Vitess resulted in the project being integrated into OSS-Fuzz with 10 fuzzers. 5 bugs were found during the audit itself, and since the audit has completed, dozens of other bugs have been found and reported by OSS-Fuzz.
Full audit report:: https://github.com/vitessio/vitess/blob/main/doc/VIT-02-report-fuzzing-audit.pdf
FluxCD
Fuzzing was introduced to FluxCD as part of its security audit. The fuzzing part of the audit found two bugs, and the fuzzers were integrated to run continuously on OSS-Fuzz.
Full audit report:: https://fluxcd.io/FluxFinalReport-v1.1.pdf
Argo
An audit was carried out to introduce fuzzing to the Argo eco system. Fuzzers were added for Argo Workflows, ArgoCD, Argo Events, Argo Rollouts and Gitops Engine. In total, 41 fuzzers were written and were set up to run continuously by way of OSS-Fuzz. These fuzzers found 10 bugs. In Argos subsequent security audit another 10 were added to the test suite, and several other bugs were found by these.
Full audit report:: https://github.com/argoproj/argoproj/blob/master/docs/audit_fuzzer_adalogics_2022.pdf
etcd
A fuzzing audit was carried out for etcd that plays an important role for all users of Kubernetes. etcd was integrated into OSS-Fuzz, 18 fuzzers were written, and 8 bugs were found and fixed.
Full audit report:: https://github.com/etcd-io/etcd/blob/main/security/FUZZING_AUDIT_2022.PDF
CRI-O
CRI-O adopted fuzzing as part of its security audit. A bug was found as a result of this in the SpecAddDevices API, where CRI-O would traverse all files recursively, but a user could specify the path “/” which would make CRI-O traverse the entire file system. If the filesystem was large, CRI-O would spend tens of seconds on this single call.
Full audit report:: https://github.com/cri-o/cri-o/blob/main/security/2022_security_audit_adalogics.pdf
In addition to this there are several audits concluding as of this writing, including Helm, Kubernetes, Cluster-API and KubeEdge. Follow along on the CNCF fuzzing repository to see when these are published.
Results from fuzzing CNCF projects
In this section we detail the results from the fuzzing work. The results include both quantitative data on bug count and also data on more qualitative results in the form of maintainer experience feedback.
Bugs found by fuzzing
In almost all of the projects that have been fuzzed at least one issue was found, and in most cases more than one issue is found. The bugs found by OSS-Fuzz are transparent in that they are published on a bug-tracker with limited information about each bug (following a disclosure deadline). In the following we use this bug tracker to extract data to perform analysis and extract high-level understanding about the impact from the fuzzing.
All of the issues from OSS-Fuzz are available on the following bug tracker: https://bugs.chromium.org/p/oss-fuzz/issues/list
We can use specific search queries to filter and sort the data in the bug tracker. For example, in order to search for all issues related to Kubernetes when can simply use the query “proj=kubernetes” while also selecting “All issues” in the drop-down menu. This gives us to the entire history of issues found by fuzzers integrated into the Kubernetes OSS-Fuzz project, including those that are open. Notice that OSS-Fuzz has a 90 day disclosure deadline, which means not all data is up-to-date for public viewing.
To collect data about the CNCF projects we will use the following two search queries on the bug tracker and use the drop-down for all issues on the projects:
- “proj=PROJ_NAME Type=Bug-Security label:Reproducible”
- “proj=PROJ_NAME Type=Bug-Security,Bug label:Reproducible”
We use query (1) for projects in memory-unsafe languages (projects in C and C++) and query (2) for projects in memory safe languages (Go, Rust). The reason we use two distinct queries is that the “Type” feature is better supported for C/C++ whereas the labelling of bug-type is not working properly for memory safe languages. We add the “Reproducible” label to ensure we only count bugs that are reproducible by OSS-Fuzz. Notice, however, that several non-reproducible bugs are indeed true bugs and this is particular the case for when projects in Go detect issues in Golang itself, as these will often be non-reproducible within the context of OSS-Fuzz’s definition of reproducibility. An example URL is the following for Kubernetes: https://bugs.chromium.org/p/oss-fuzz/issues/list?q=proj%3DKubernetes%20Type%3DBug%2CBug-Security%20label%3AReproducible&can=1
The following table shows the data based on the above queries. The table also includes the project languages as well as the date a given project was integrated into OSS-Fuzz. Finally, to replicate the query you have to use the OSS-Fuzz project name, which is provided in the second column in the table.
| Project | OSS-Fuzz project name | Bugs found | Project language | OSS-Fuzz integration date (dd/mm/yy) |
| Argo | argo | 29 | Go | 21-12-2021 |
| Cilium | cilium | 0 | Go | 07-12-2020 |
| Cluster API | kubernetes-cluster-api | 5 | Go | 16-02-2022 |
| Containerd | containerd | 2 | Go | 24-05-2021 |
| CoreDNS | go-coredns | 4 | Go | 06-05-2020 |
| CRI-O | cri-o | 4 | Go | 13-04-2022 |
| Distribution | distribution | 4 | Go | 05-01-2022 |
| Envoy | envoy | 82 | C++ | 02-02-2018 |
| Etcd | etcd | 16 | Go | 16-09-2021 |
| Fluent-bit | fluent-bit | 66 | C | 15-04-2020 |
| Flux CD | fluxcd | 3 | Go | 28-10-2021 |
| Helm | helm | 5 | Go | 16-02-2022 |
| KubeEdge | kubeedge | 0 | Go | 16-10-2019 |
| Kubernetes | kubernetes | 43 | Go | 26-05-2022 |
| Linkerd2 | linkerd2 | 8 | Go | 21-11-2021 |
| Linkerd2-proxy | linkerd2-proxy | 14 | Rust | 09-04-2021 |
| Prometheus | prometheus | 8 | Go | 15-05-2020 |
| Runc | runc | 0 | Go | 05-03-2021 |
| Vitess | vitess | 32 | Go | 13-05-2020 |
The sum of bugs in the above table is 325. It’s important to highlight here that this is an approximation. First, the bug count under-approximates from the perspective of not all bugs found are included as there will be bugs in the embargo process and we have not counted all types of bugs, for example bugs of type Type=Bug for C/C++ and all bugs declared unreproducible by OSS-Fuzz (which may still be true bugs). Second, the bug count over-approximates from the perspective of there can be issues in the fuzzers themselves which are reported as bugs, i.e. the bug is not a true bug in the target project, and fuzzers can be written in a way they over-approximate what is actually possible in the target project.
An interesting correlation in the above schema is the date of the OSS-Fuzz integration and the number of issues found by OSS-Fuzz. This is visualised in the following chart with issues found on the x-axis and integration date on the y-axis (leftmost has been integrated for the longest), and there are labels on each dot in the chart indicating the given project.

It’s clear that there are more bugs found for projects that have had continuous fuzzing running for a longer period of time. The idea is that continuous fuzzing reaps rewards over time as fuzzers need to be run continuously in order to build up their corpus. Additionally, and perhaps more importantly, it’s likely that the longer a project has been integrated into OSS-Fuzz the more mature the project’s fuzzing set up is, such as maintainers having devoted more time to extended the project’s fuzzing suite, devoted more efforts to fixing issues and alike.
Visualising results over time
We can plot the number of bugs found by OSS-Fuzz based on their metadata in the bugtracker. For example, an interesting plot is to observe how many issues are open versus how many issues are closed. The lifecycle of a bug reported by OSS-Fuzz is it starts as open and once it’s fixed it’s set to closed. As such, the amount of closed bugs will only ever increase and the total amount of bugs found up until a given date is the sum of the opened and closed bugs on the given date. We can visualise this data using the “chart” feature of the bug tracker. In this sense, we can track how frequent projects fix bugs and also how frequent new issues are found.
The following plot visualises this for all of the Go and Rust projects in the above table using query (2). The blue graph shows the amount of open issues for all the projects at a given date and the red graph shows the amount of issues closed on a given date.
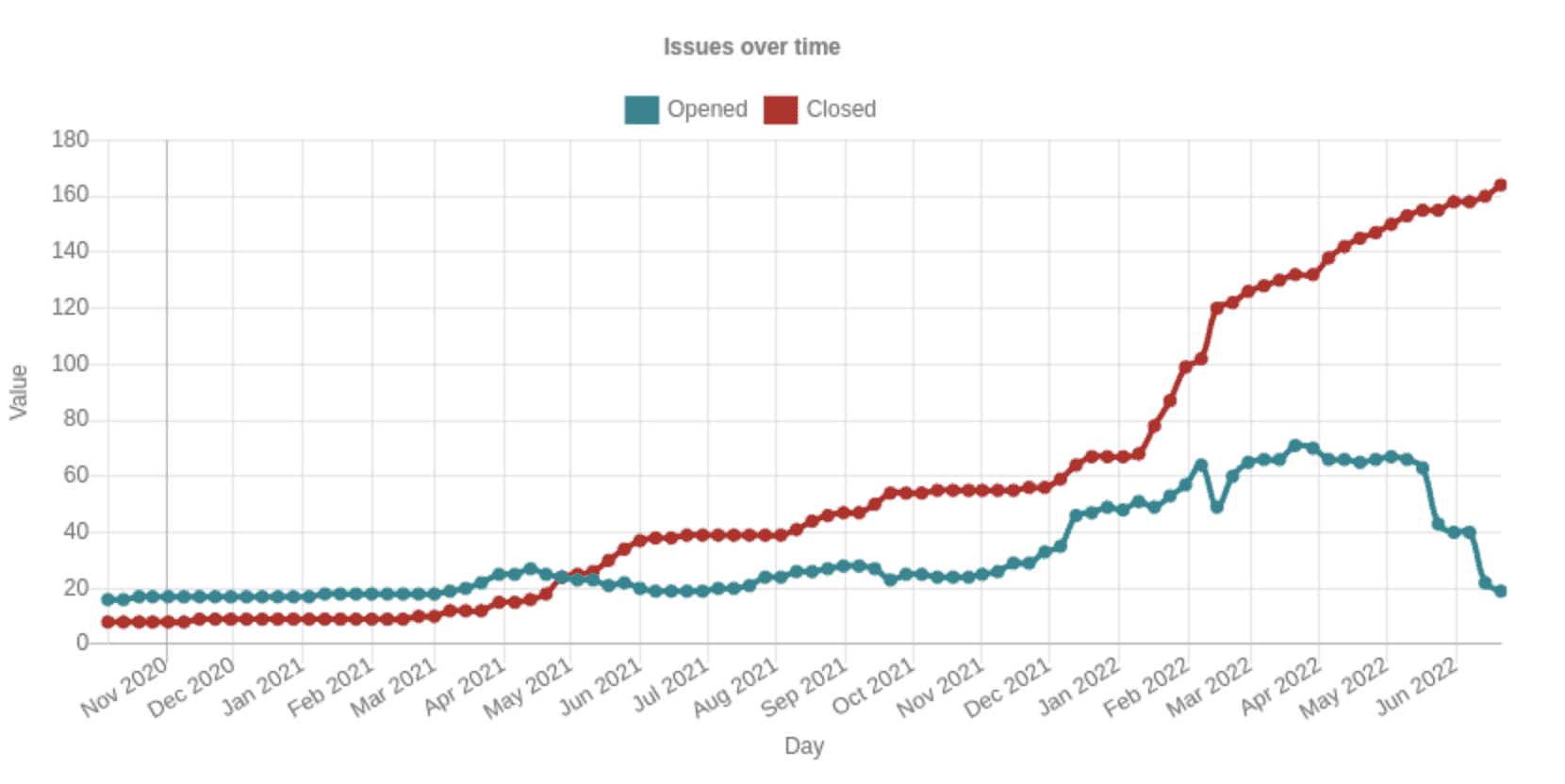
The plot also shows that the fuzzing effort produces results. The fuzzing audits started around March of 2021, and since then we see a continuously increasing amount of issues being closed, meaning more and more issues are found and fixed. An interesting observation is that the number of issues closed is somewhat constantly increasing. This is an indication that bugs continue to be found and fixed, which shows the value of continuity in the efforts. Even after fuzzing audits complete, the fuzzers continue to explore code and will also explore new code whenever it’s added to a given project.
Another interesting observation is that when bugs are closed more bugs are opened. For example, in August 2021 there is a slight increase in both opened and closed bugs. The reason for this is that once a bug is found by a fuzzer, it can be difficult for the fuzzer to continue exploring a piece of code since it will be running into the same issue over and over again. However, once the bug is fixed, the fuzzer can continue its exploration, which often leads to finding new bugs. As such, when one bug is fixed, and thus closed, new bugs are found and thus opened.
We can plot the same figure as above but also include C/C++ projects from the table. Notice here that we use query (2) for the C/C++ projects (which is different to the data in the table where we used query (1)) which has more bugs reported than those in the table for C/C++ projects where we used query 1. The following table visualises data:
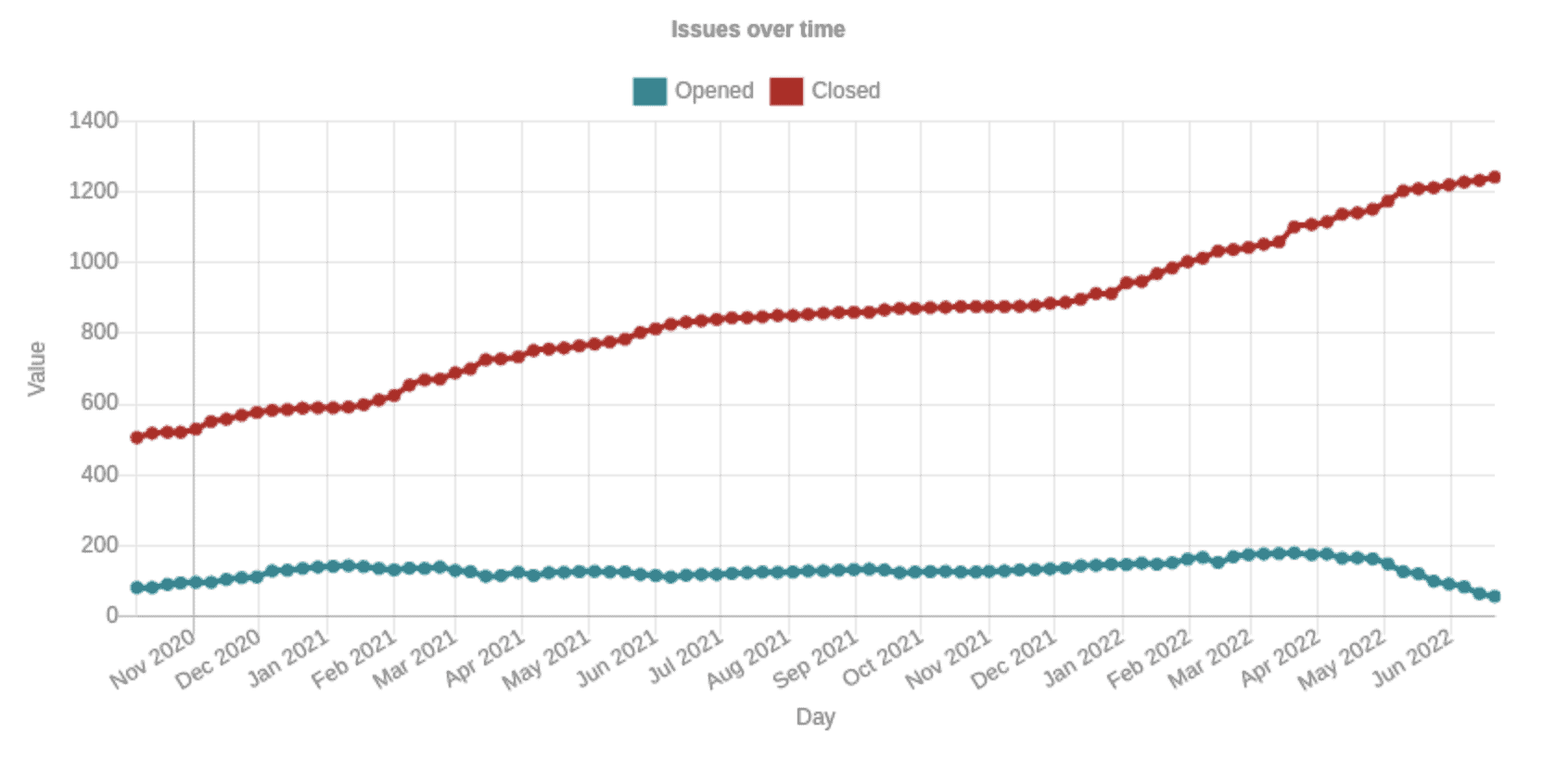
The total number of issues is dramatically higher. This is to a large extent because Envoy and Fluent Bit (the C/C++ projects added to the data collection) have likely the two most mature fuzzing set ups of all the projects and were amongst the first CNCF projects to integrate into OSS-Fuzz. They will, therefore, have explored more of their codebases using fuzzing. Another reason is that they are written in memory unsafe languages where fuzzing will find many more types of issues.
The observation on continuity continues similarly to the previous chart. In particular, the number of closed issues continues to increase which indicates bugs are found and fixed on a regular basis. Another observation is also the amount of dedication it has taken from the projects to maintain the fuzzing set ups. A total of around 1200 issues have been closed, which means around 1200 issues have been inspected by maintainers who will have submitted patches to fix the issues. This is a significant work effort.
Maintainer response
We asked the maintainers of various of the CNCF projects we discuss in this blog post to provide insights on their experiences with fuzzing. The idea is to provide more qualitative insights into the fuzzing process from the developers of the projects themselves. The quantitative data gives insights about issues found but lacks data on how the maintainers view the issues reported or the workload that comes along with maintaining a fuzzing set up. The following is a list of quotes from maintainers and their thoughts on fuzzing:
Harvey Tuch, Envoy Proxy: “Fuzzing is foundational to Envoy’s security and reliability posture – we have invested heavily in developing and improving dozens of fuzzers across the data and control plane. We have realized the benefits via proactive discovery of CVEs and many non-security related improvements that harden the reliability of Envoy. Fuzzing is not a write-once exercise for Envoy, with continual monitoring of the performance and effectiveness of fuzzers.”
Jann Fischer, ArgoCD: “The fuzzing initiative with Ada Logics was a really valuable experience for the Argo CD team. Not only did the fuzzers find quite a few hard to catch and serious bugs in our code base. We also learned a lot from analyzing and fixing these bugs, especially that the assumptions we make while writing code are not always correct, even if we think there is proper unit testing in place. We really embrace the idea of fuzzing in addition to ordinary unit tests, because fuzzing will feed your code paths with input one could never have thought of, and therefore is able to discover assumptions that turn out to be invalid.”
Sahdev Zala, etcd “The etcd team is thankful to CNCF and Chris Aniszczyk for providing the opportunity to work with Ada Logics to develop new fuzzers for etcd. The fuzzing findings and fixes are valuable add-ons to the previous conclusions of the security audit. The newly developed fuzzers have provided significant value to the project.”
Eduardo Silva, Fluent Bit: “Fuzzing techniques have taken the Fluent Bit project to the next level. With the help of Ada Logics, we now have the majority of our code base covered with custom fuzzers running on OSS-Fuzz. As a result, many bugs were found and, importantly, found ahead of time so the impact of these bugs on the users was nearly zero. In addition, the team helped to provide fixes in a timely manner.
Continuous Fuzzing is the way to go, so our maintainers, contributors, and users can feel covered.”
Kazuyoshi Kato, Containerd: “containerd is designed to be robust and secure. OSS-Fuzz’s continuous fuzzing effort helped us to make sure that our implementation is meeting the design goals. We are now integrating most fuzzers to containerd’s repository itself and running them on every PR.”
Vincent Lin, KubeEdge: KubeEdge extends native containerized application orchestration capabilities to hosts at the edge and has been widely adopted in industries including Transportation, Energy, CDN, Manufacturing, Smart Campus, etc. This means that users have more stringent security demands on KubeEdge. Because of this, the KubeEdge team spent recent years dedicated to improving our test coverage and security posture to help find lurking bugs, and prevent new ones from popping up.
Fuzzing fits perfectly in that journey. KubeEdge was integrated into OSS-Fuzz and CIFuzz, 10 fuzzers are written and these fuzzers were set up to run in the CI for pull requests. The work was done in collaboration with the Ada Logics Team.
Fuzzing has the immediate benefits of finding bugs in a highly autonomous manner and it can continue to look for bugs for a long time without much manual interference. We believe that Fuzzing will play a great role in the security reinforcement of KubeEdge.”
William Morgan, Linkerd: “Organizations around the world rely on Linkerd to provide critical security guarantees for their applications, and Linkerd must provide these guarantees in the face of arbitrary or even malicious network data. Fuzz testing is a critical component of Linkerd’s comprehensive set of security controls, and has allowed us to catch tricky and subtle issues that otherwise would have gone undetected.”
Martin Hickey, Helm: “Reliability and security are paramount to Helm and fuzzing provides a consistent integrated way of testing.”
Future work
In this section we outline future work efforts.
Integrate fuzzing into more CNCF projects
A clear goal is to extend on the existing fuzzing efforts and integrate fuzzing into more CNCF projects. Ideally fuzzing should be part of each project’s workflow, although a full integration into OSS-Fuzz is not necessarily the ideal situation for each project.
Enabling continuous and sustainable fuzzing maintenance
Many of the projects that currently have fuzzing do not necessarily fuzz their entire codebase or lack a systematic continuous effort in maintaining and extending their fuzzing suite. The ideal fuzzing integration is fuzzing that covers all areas of a given codebase and this is the long-term goal for these efforts. A problem orthogonal to this is making it easier and more sustainable for developers to maintain a continuous support on their fuzzing infrastructure.
In the event you’re a maintainer of a project and interested in getting fuzzing integrated but may seek help, we welcome questions and queries by way of Github issues on cncf fuzzing: https://github.com/cncf/cncf-fuzzing/issues
Maintainer involvement
A significant portion of fuzzing work on CNCF projects is carried out by the CNCF sponsored fuzzing audits and much of the work is carried out by way of the dedicate CNCF-Fuzzing repository https://github.com/cncf/cncf-fuzzing. However, there is a major benefit to having maintainers of the projects assist or completely take over the fuzzing of the projects, as maintainers understand much more about the intricacies of the software being analysed. One of the CNCF goals is to enable this and improve support for maintainers to take over the fuzzing.
Several projects have done this already and taken on the effort of managing and extending the fuzzing suite. Most recently, Containerd are migrating their fuzzers from the go-fuzz engine to the Go 1.18 engine. Likewise, the FluxCD team did a great job at rewriting all fuzzers made from their security audit to fit better into their overall test infrastructure. The Linkerd team has similarly taken efforts into migrating fuzzers from the CNCF-Fuzzing repository into their own repositories. However, this is double-edged. Some projects have done the opposite and migrated fuzzers into the CNCF-Fuzzing repository to clear-up their upstream repositories and CI workflows, e.g. Vitess https://github.com/vitessio/vitess/pull/9477
An interesting future work is offering multiple ways in which maintainers can be involved with fuzzing their projects. From our experiences there is no one-way fits all and the resources available vary between projects a lot. One of the peculiar trade-offs in this context is that security-minded folks will often know a lot about fuzzing but less about the projects they target, whereas developers will know a lot about projects but less about how to apply fuzzing. A particular effort worth mentioning in this context is fuzz-introspector from OSSF https://github.com/ossf/fuzz-introspector which aims to improve introspection capabilities into fuzzing set ups with the goal of assessing areas of potential improvements. OSS-Fuzz integrates fuzz-introspector which means projects in OSS-Fuzz will benefit from this, however, Fuzz Introspector is limited to C/C++ support at this moment in time (additional languages support is in development).
We’re happy to receive feedback from maintainers and what could be done to make it easier for them to maintain fuzzing efforts.
New bug oracles for memory safe languages
Fuzzing of memory safe languages is new compared to fuzzing memory unsafe languages. Several vulnerabilities have been found in some of the projects that have been found, often through dedicated CNCF security audits. For example, a security audit of CRI-O, where a Denial-of-Service vulnerability was found through manual auditing in the ExecSync API. A similar vulnerability was found in Containerd, and both projects patched the vulnerabilities collaboratively. More about this work can be found here: https://www.cncf.io/blog/2022/06/06/ostifs-audit-of-cri-o-is-complete-high-severity-issues-found-and-fixed. We want to find such vulnerabilities and many others automatically, and for that we will need different bug-detectors that specifically look for these kinds of issues during fuzz runs.
New bug-detectors will be developed over the coming years and will be applied to fuzzing in a general manner, ie., in a way where the same fuzz harness can use all bug-detectors without being customised for each. When such bug detectors are developed and open sourced, the CNCF landscape will be able to utilize these without much, or perhaps any, modifications. The existing fuzzers will utilize new bug detection capabilities.
Conclusions
CNCF has been investing in security audits and fuzzing over the last handful of years to the tune of over a million dollars. Fuzzing is a proven technique for finding security and reliability issues in software and the investments have enabled fuzzing integration into more than fifteen CNCF projects through a series of dedicated fuzzing audits. In total, depending on how count, about 325 bugs have been found through fuzzing of CNCF projects. The fuzzing efforts of CNCF has focused on enabling continuous fuzzing of projects to ensure continued security analysis, which is done by way of the open source fuzzing project OSS-Fuzz.
CNCF continues work in this space and will further increase investment to improve security across its projects and community. The focus for future work is integrating fuzzing into more projects, enabling sustainable fuzzer maintenance, increasing maintainer involvement and enabling fuzzing to find more vulnerabilities in memory safe languages. Maintainers who are interested in getting fuzzing integrated into their projects or have questions about fuzzing are encouraged to visit the dedicated cncf-fuzzing repository https://github.com/cncf/cncf-fuzzing where questions and queries are welcome.