An introduction to OPAL – an open-source administration layer for Open Policy Agent (OPA) that allows you to easily keep your authorization layer up-to-date in real-time
Guest post originally published on the Permit.io blog by Daniel Bass

TL;DR
OPAL is an open-source administration layer for Open Policy Agent (OPA) that allows you to easily keep your authorization layer up-to-date in real-time. OPAL detects changes to both policy and policy data and pushes live updates to your agents – bringing open policy up to the speed needed by live applications.
As your application state changes (whether it’s via your APIs, DBs, git, S3, or 3rd-party SaaS services), OPAL will make sure your services are always in sync with the authorization data and policy they need.
The challenge of building authorization
Cloud-native / microservice-based products can be quite complicated, and so is building access control and managing permissions for them. Distributed applications and microservices require a lot of authorization points by design and the ever-changing requirements and regulations from various departments constantly challenge every authorization solution. Moreover, even the simplest miscalculation in the authorization layer can lead to devastating consequences for your application in the form of security vulnerabilities and privacy/compliance issues.
There are several best practices for building an authorization layer correctly (and avoiding the need to constantly rebuild it) – the first of which is decoupling policy and code. In short – Having the code of the authorization layer mixed in with the code of your application can result in trouble upgrading, adding capabilities, and monitoring the code as it is replicated between different microservices. Each change would require us to refactor large areas of code that constantly continue to drift further from one another as these microservices develop.
To avoid this, we recommend creating a separate microservice for authorization that will be used by the other services in order to fulfill their authorization needs. Open Policy Agent (OPA), which is the default policy engine for OPAL, allows you to do just that. You can read more about OPA here.
Another best practice, which OPA alone does not fulfill, is making your authorization layer event-driven.
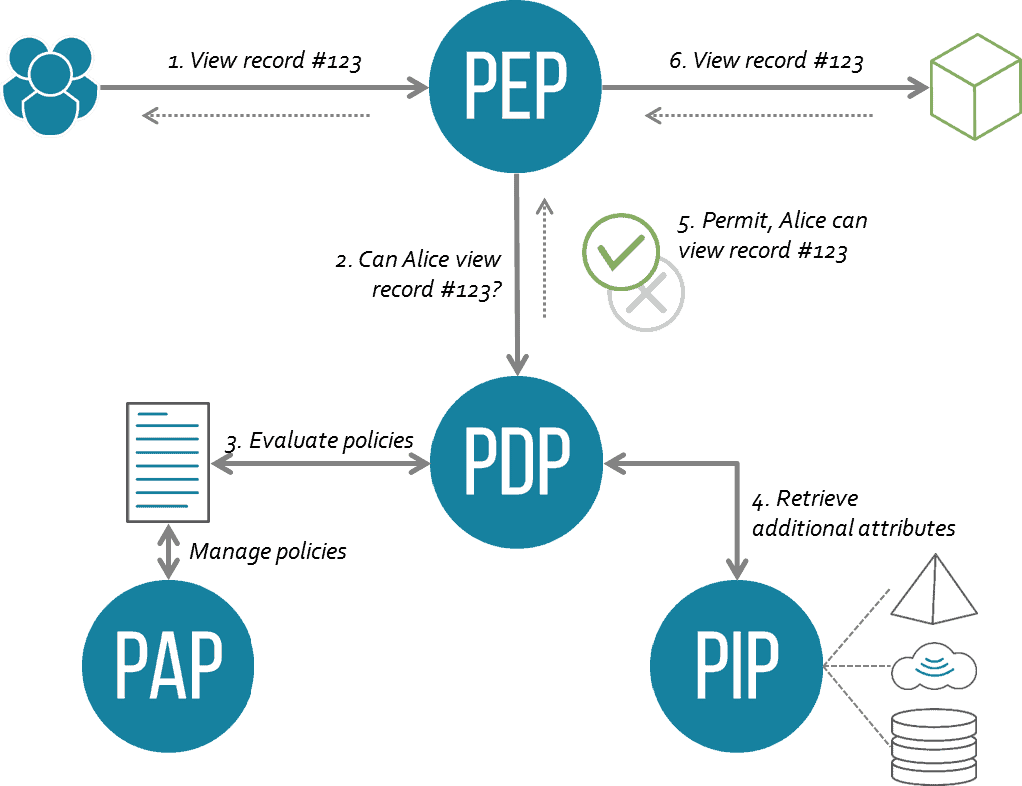
Why event-driven?
Almost all modern applications rely on abilities such as user invites, role assignment, or the usage of 3rd party data sources. All of these abilities have one thing in common: They have to be managed in a real-time fashion. Every time an event that affects authorization happens, we need it to be pushed into our authorization layer ASAP so it can stay in sync with the application, any relevant 3rd party data service, or changes in policy.
Here’s an example – Say you want to control who has access to a specific feature in your application based on a user’s payment status. If the user paid for the feature – they have access. This scenario creates three main challenges:
- The data about the payment status of users (As well as various other types of data relevant to making authorization decisions) often resides in a database external to your organization, or a 3rd party service like Stripe or PayPal. You need your authorization layer to be aware of any relevant changes in these databases and make decisions based on the most up-to-date information available. To achieve this, we’d need something that listens to changes in the data sources relevant to us, and pulls them into our authorization layer so it can make the most accurate, relevant, and up-to-date decisions.
- Delays in updates to the authorization snapshot can create consistency problems. Consider this example – a request is being handled by two microservices in the same chain. The first microservice can consider the request in one state (e.g. This user is not a paying user), while the following microservice considers the request in another state. This can cause the overall request to fall into an undefined state.
- Different microservices need different subsets of policy and data, just keeping track of the needs of each one can be challenging without an event stream to guide us.
Being a common problem, large organizations such as Netflix and Pinterest who rely on OPA as their policy engine were required to create their own solutions, building multiple administration layers on top of OPA. Manish Mehta, a senior security officer from Netflix, shared Netflix’s permissions design in a talk at KubeCon. Unfortunately, these giants haven’t open-sourced their solutions; but their work did inspire the creation of OPAL.
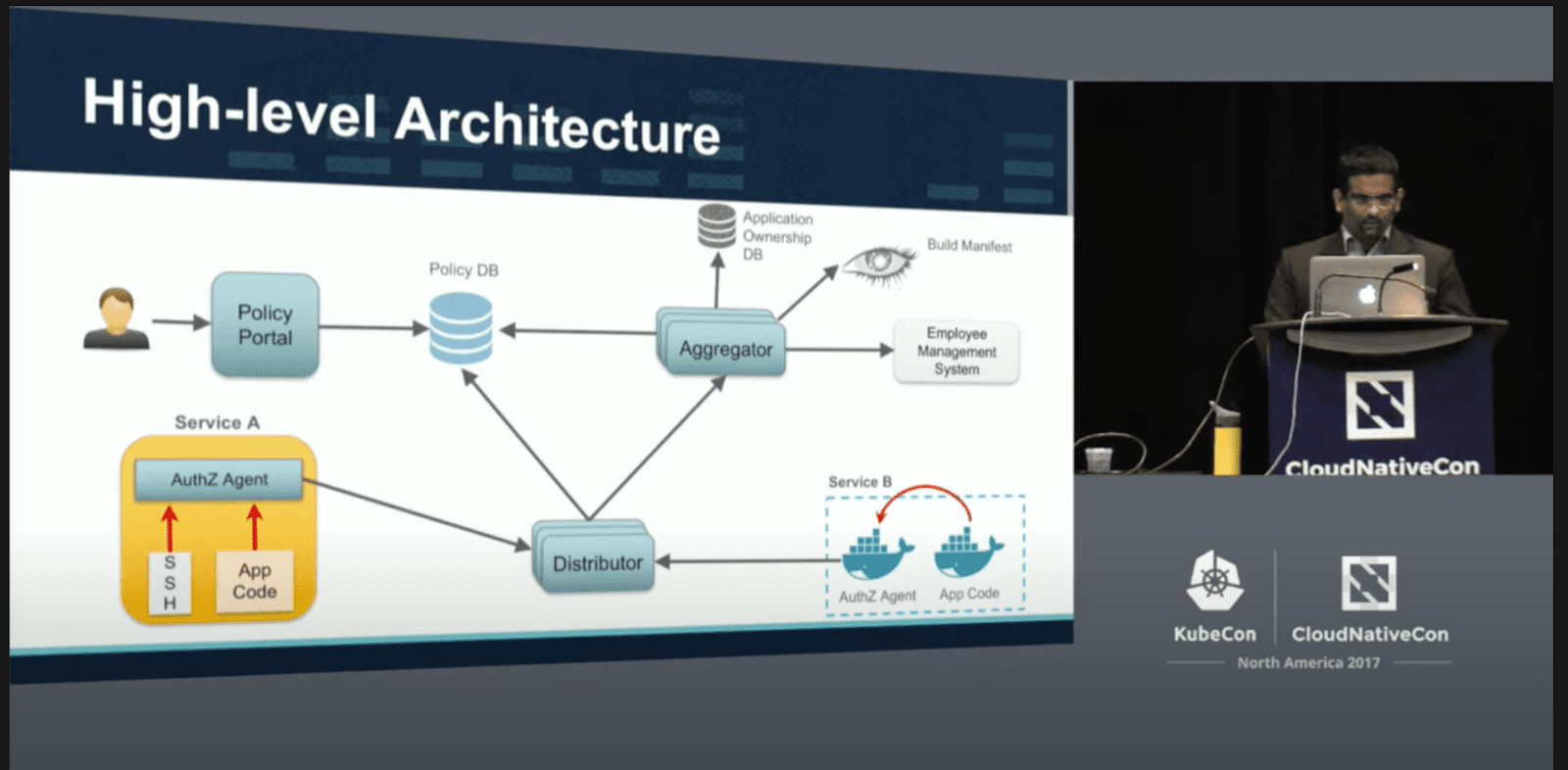
How Netflix uses OPA in permissions enforcement talk at KubeCon, 2017.
How OPAL helps solve these challenges:
OPAL is an open-source solution that helps us solve these two challenges by providing two significant features:
- The ability to track a designated policy repository (Such as GitHub, GitLab, Bitbucket) for changes (by either setting a webhook or web polling every X seconds), thus serving as a PAP (Policy Administration Point) and propagating these changes into OPA (The PDP – Policy Decision Point in this case) thus always keeping it up to date.
- The ability to track any relevant data source (API, Database, external service) for updates via REST API, and fetch up-to-date data back into OPA.
These two features make sure that OPA is always up to date with both the latest policy information and the latest data – allowing it to always make the most accurate and relevant authorization decisions.
OPAL’s ability to solve these challenges led to its adoption by a number of leading organizations such as Tesla, Zapier, and Accenture.
How does it work? A little deep dive into OPAL’s architecture:
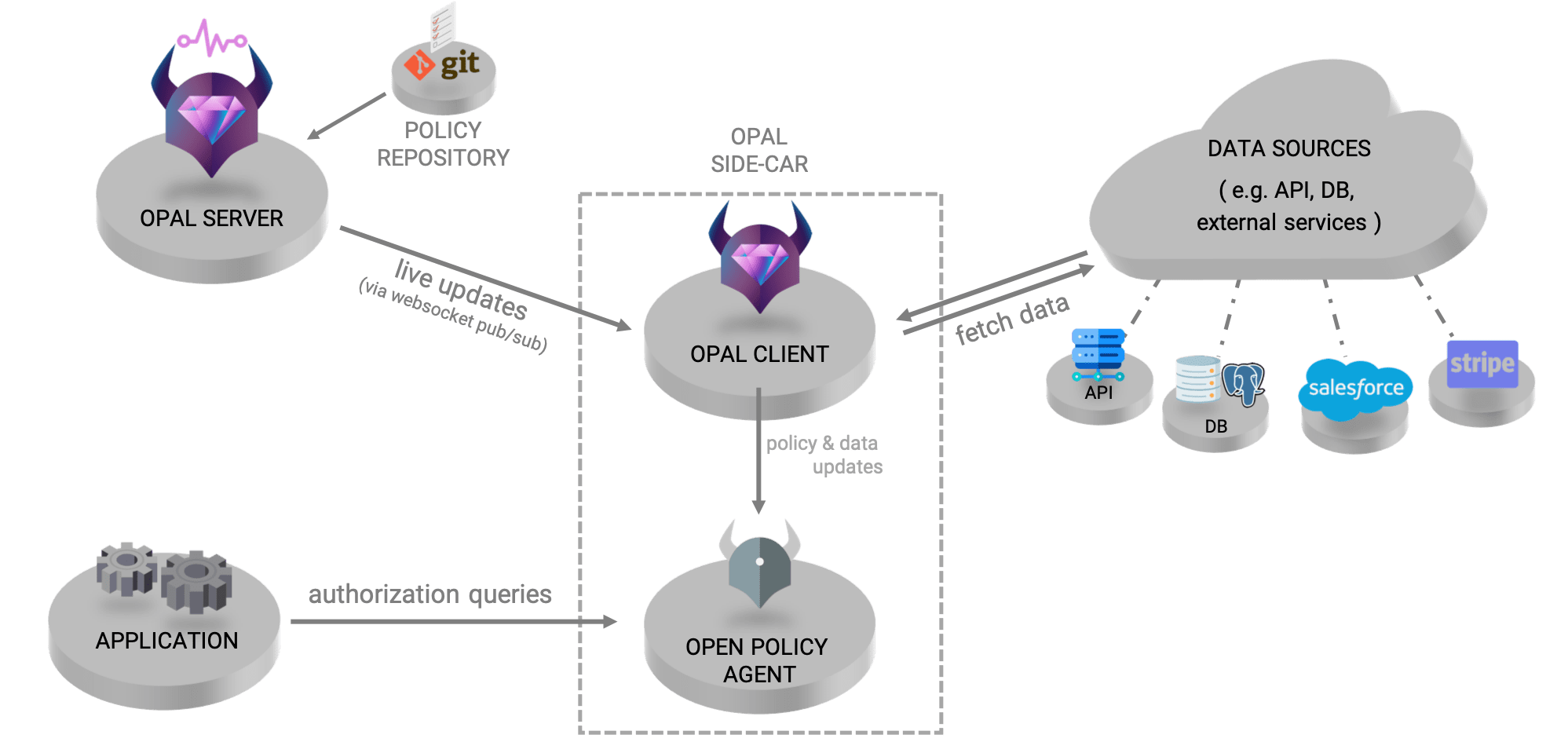
OPAL consists of two main components: the OPAL Server and the OPAL Client.
The OPAL Server is responsible for two things:
- It tracks a designated policy repository for changes via webhook or polling for policy updates and pushes these changes to the OPAL Client.
- It tracks all relevant data sources for changes via webhook, signals the OPAL Client about any changes via WebSocket, and provides it with information on where the data is located.
In both of these cases, the OPAL server creates a pub/sub channel that the OPAL client(s) can subscribe to with topics they need to track. As soon as there’s a change, the OPAL server notifies the subscribed clients.
The OPAL client is deployed alongside OPA and provides real-time updates of all relevant data and policy from the OPAL Server to OPA, so it also has a dual function:
- Policy changes: Whenever there is a relevant policy update in the policy repository, it is pulled by the client from the server, and propagated into OPA.
- Data updates: Whenever there’s a relevant data update in a topic that the OPAL client is registered to, the OPAL server will push an update to the OPAL client with information on where to pull the newly updated data from. The client will then reach out to fetch the latest relevant data with the help of OPAL Data Fetchers.
OPAL Data Fetchers are configured to grab updates from a specific data source. A data fetcher has two main methods: `fetch()`, which is in charge of querying the data source, and `process()` to filter the data and convert it to JSON format, OPA’s format. The OPAL Data fetchers retrieve any relevant data from their designated data source and propagate it to OPA.
Another important feature of the OPAL client is its ability to only subscribe to the specific data that it needs. If your application requires large amounts of data to support authorization logic, the OPAL client can subscribe only to the specific parts needed for that specific agent – this provides benefits both in terms of security (By keeping access to data on a “need-to-know” basis) and manageability.
This way, OPA is able to make policy decisions based on the most recent policies and data. A deeper dive into OPAL’s architecture and communication flows is available in OPAL’s documentation.
Keeping OPA up to date in real-time is crucial, especially when dealing with authorization at the application level. By using OPAL we enhance OPA’s authorization capabilities with two major abilities:
- Updating our policies in real-time, and having our authorization decisions made on the most up-to-date policies available.
- Pulling relevant data from any source, thus being able to make authorization decisions based on data from any Database or service.
Help us grow –
OPAL is an ongoing open-source project which is already keeping hundreds of policy agents updated in real-time. You can join OPAL’s Slack community to chat with other devs who use OPAL for their projects, contribute to the open-source project, or follow OPAL on Twitter for the latest news and updates.