





Guest post originally published on the Weaveworks blog by Darryl Weaver, Solution Architect, and David Stauffer, Product Manager
In this blog, we explain how to build a self-service Kubernetes platform with Helm, GitOps, and Cluster API. Profile layer models are the foundation for deploying whole clusters on demand and building platforms for developers with all the components they need. As a result, developer iterations make it into production faster.
Kubernetes is the de facto cloud-native platform for applications and operational teams. Provisioning fully functional Kubernetes clusters is still a challenge, however, as they require more than just their bare-bone skeleton. To be operational, they require numerous additional components covering ingress and/or service mesh (Nginx, Linkerd, Istio), metrics and observability (Prometheus, Grafana), and continuous delivery (Flux).
To illustrate the number of possible cluster components available, this is what the current CNCF landscape looks like:
In recent years, the customer success team at Weaveworks has helped a great many customers and users to declaratively provision and manage their clusters with tailored configuration and components that meet their business needs.
Why Profiles?
Profiles are declaratively described via GitOps and offer the capability to define a Kubernetes cluster that is tailored to the needs of your platform and application team.
They let you bootstrap essential components in areas such as observability (for example, Prometheus and Grafana) and configure them as part of the cluster provisioning process through GitOps (meaning that all components and configuration files are read from source control) using Flux.
The reason we created profiles was, in short, ease of use. The definition of the profile itself is done through tooling that is already widely adopted. For example, at Weaveworks we use simple Helm charts to implement our profiles.
Integration with Cluster API
For users that already use Cluster API, we provide the capability to define profiles as part of your cluster templates (Annotation). This gives platform teams a single artefact (Cluster template) that defines the whole stack. The key benefit here is simpler provisioning of clusters, which allows operation teams to build a consistent platform.
Why not Use Helm Chart Dependencies?
Although you can declare dependencies for helm charts, when Helm installs those charts it renders all the chart objects, sorts all the Kubernetes objects by Kind, and then installs each Kind according to the following list Here
In other words, all the Namespaces, then all the NetworkPolicy, and so on. This can prevent collections of charts from installing cleanly, as some charts might depend on previously installed charts with all their Kinds running.
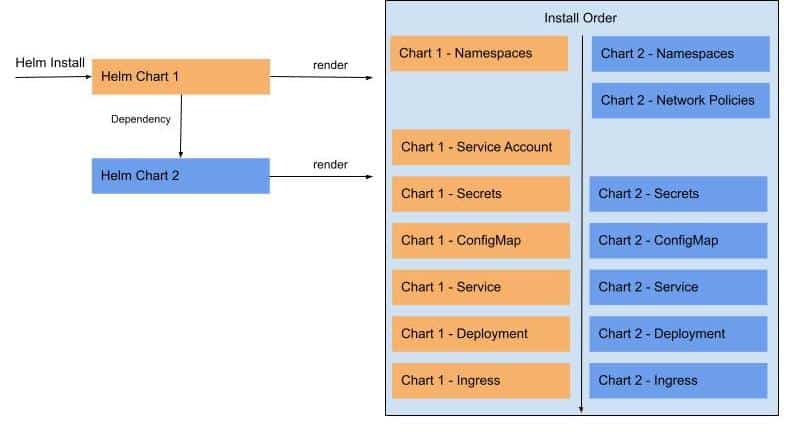
For example, to install Linkerd, we need to install cert-manager and get it running before the installation can finish.
Basically, dependencies in Helm don’t have the sufficient ordering. Now you could rely on retry mechanisms to resolve this conflict and, in some cases, this might work fine. There are dangers, however, that the retries will be exhausted before they can be resolved and eventually an error occurs.
Instead, we recommend an additional ordering hint from Helm charts that actually implements the required ordering, allowing for a clean install of the collection of Helm charts.
We don’t encounter this problem often as in typical continuous deployment pipelines a collection of commands is run in an imperative way which includes ordering.
For example, in order to achieve the correct install order of all components without having to retry, you could:
- Helm install cert-manager
- Wait for it to finish and then Helm install Linkerd
- And after that, Helm install Flagger.
If we want to use GitOps, we need a declarative version that defines the entire cluster in a Git repository. Only there’s a problem. Declaring a list of Helm charts will not prompt the installs in the right sequence, as the ordering information has been lost. All installs would happen in parallel.
In order to retain the ordering information, we have found a way to sequence Helm charts, by layering Helm charts into profiles.
A profile is simply a Helm chart with annotations that declares it to be a profile. We are giving it a name, allocating a profile category, and declaring which layer the Helm chart should be deployed with.
For example:
annotations:"weave.works/profile": cert-manager"weave.works/category": Certificate"weave.works/layer": layer-1
This approach lets you host a collection of Kubernetes platform components in a Helm repository. The Helm repo can now be used in the Kubernetes cluster build process to deploy all your platform components. It also allows the ordering to be controlled by the layers specified in the annotation.
For example, we can store a cert-manager profile in our Helm repo and add an annotation for it to be deployed in layer 1. Then we can declare that Linkerd must be deployed in layer 2 and finally install Flagger in layer 3.
Why We Use a Flux’ Helm Controller?
In combining this profile layering with a Helm controller, you can deploy Helm charts with full lifecycle management and ordering. Many other solutions don’t have a Helm controller. They render Helm charts using the Helm template command instead of installing with Helm – this results in missing hooks that run during the life cycle, i.e. install, update, and deletion. Hooks being run can cause changes to be missed which can lead to critical issues when the hooks contain necessary updates, such as updating the database schema in line with a new version of an application.
Obviously, this can result in a very poor deployment experience and production problems for developers or platform engineers when building production grade Kubernetes clusters.
By using the Helm controller to manage the full Helm lifecycle and using profile layers to control the dependency ordering of platform components in the source Helm repository, we can now provide a self-service platform for developers. The expertise from the platform team is already built into the components that developers can independently select for their clusters.
Profile Layer Models
Helm charts enable us to layer profiles as described above. We can create a model now that aids in adding layers to each profile we want to install.
Model 1 – Minimalist
The most basic model only has layers for necessary hard dependencies that must be installed in their entirety before the next layer, and are determined based on the set of platform components that you want to install together.
This is the simplest model, but also one that will likely necessitate changes when adding new components to the list.
For example:
- Layer-1 = Cluster scoped: secrets, certificates, AAA, ClusterRoles & bindings, CRDs
- Layer 2 = Cluster scoped: Platform components: storage, observability, operators, policy controls
- Layer-3 = Cluster Scoped Configurations
- Layer-4 = Namespace scoped: secrets, RBAC, CRDS, etc.
- Layer-5 = Namespace scoped: applications
Be aware that not everything will fit into this categorization and additional layers can be necessary for additional components.
Model 2 – Category Focused
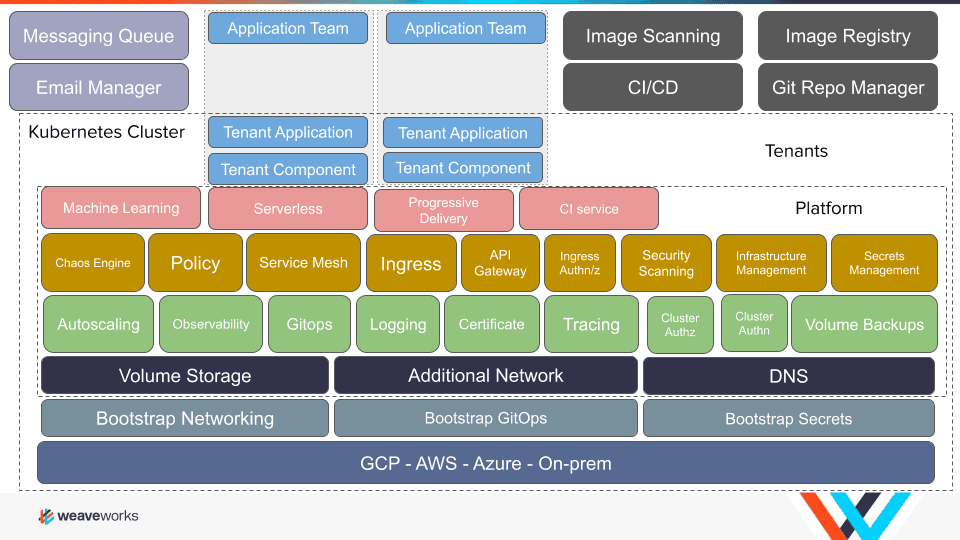
Model 2 encompasses a long list of categories of services that are one type of platform component, for example:
- Layer-01 = Certificate
- Layer-02 = Policy Controls
- Layer-03 = Secret Manager
Categories have to be agreed on for each profile and can be hard to maintain.
In order to allow for expansion and flexibility you need to allocate unique platform layer numbers and even allow for gaps in between, in case you add other dependencies at a later time.
One advantage is that every platform component already has a layer defined.
As each type of component would have the same layer numbering it would mean they can be drop-in replacements for each other.
This allows an enterprise to build components and the developers to select components to build almost any platform.
However, the list can be longer and contain a large number of categories to describe all the components needed for a complex enterprise cluster design.
Model 3 – Allocated Numbering
Lastly, model 3 has a fixed list of layer numbering allocated to platform components that have been previously agreed upon for each component and given a layer number from a master list. The allocated numbering is published and freely available for anyone to modify the layer numbers they would like for their application, in order to build a unique layer list.
The disadvantage is maintenance – however, this model can easily be updated by pull requests in a repository, and reviewed accordingly to make sure that layer numbering is unique for each platform component application.
This eventually results in quite a long list with many layers, but it has the advantage of being easy to share across multiple organizations with different requirements, as well as always being able to install components in a predetermined order.
For example:
- Layer-001 = cert-manager
- Layer-022 = Hashicorp Vault
- Layer-060 = Linkerd
- Layer-120 = Flagger
This approach is very flexible and can deal with a lot of applications. But again, it requires a large number of layers and a complex layering philosophy that needs to be maintained centrally for all Helm applications or for each helm repository. It also is more difficult to fit in custom components, as these are not registered centrally and must fit in between the registered layer numbering.
Summary
As you can see, using profile layers for Helm charts with GitOps solves the ordering problem with Helm applications – an issue that cannot be resolved with Helm alone.
The Flux Helm controller uses the entire Helm lifecycle, including running hooks built into the Helm chart on deployment, upgrade, and deletion. Consuming Helm charts becomes simpler and easier to control from the Helm repository for all clusters deploying this set of Helm charts.
If we combine these techniques with Cluster API to deploy whole clusters on demand, it gives us a way to build platforms for developers with all the components they already need in a self-service model, speeding up developer iterations into production.
The holy grail of all DevOps organizations is to speed up developers. With this Kubernetes management approach, developers do not have to know how a Kubernetes cluster is built or which components they need. They can simply consume the platform and focus on their code.
Weaveworks implements Profiles in Weave Gitops Enterprise, which is our commercial tool based on open source projects: FluxCD, Cluster API, Flagger and includes our Weave Policy Agent.
For more information, check out the CNCF projects: