
Guest post from IBM
Authors:
- Vishal Anand – Chief Technologist, Cloud Migrations and OpenShift PaaS – IBM Consulting
- Utpal Mangla – Industry EDGE Cloud – IBM Cloud Platform
- Atul Gupta – Lead Data Architect – IBM
- Luca Marchi – Industry EDGE and Distribute Cloud – IBM Cloud Platform
Kubernetes-native could be any object, resource, custom resource, application, middleware, workload, image, tool, interface etc. which is designed to run on Kubernetes platform, and it runs with its own or shared YAML file. This is the simplest definition.
Kubernetes-native technologies and environments are meant to provide true portability and interoperability.
So, what is Kubernetes-native Target Operating Model (KTOM)?
It is firmly believed that KTOM is fundamentally different from the traditional Cloud-native operating model, but some aspects can be the same as well. This varies in certain conditions or use cases or specific transformational journeys. Kubernetes-native is a specialization of Cloud-native.
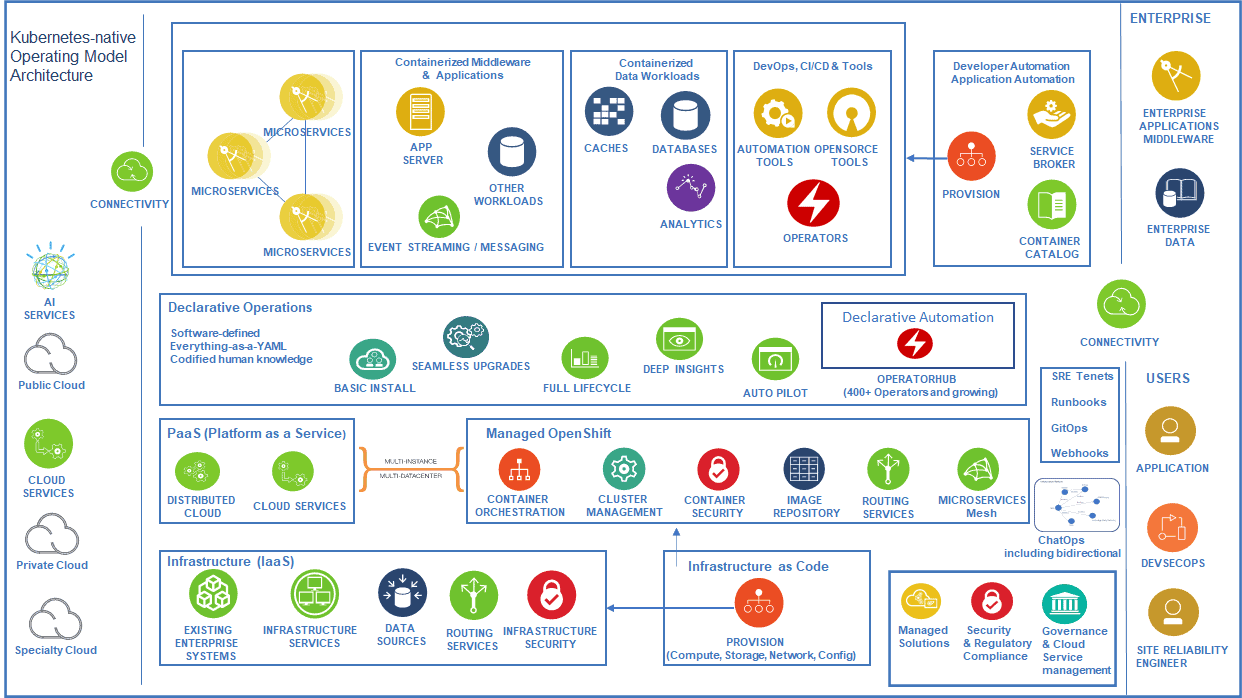
Figure 1: Kubernetes-native Target Operating Model (KTOM) Architecture Framework
A simple Kubernetes is a cluster with a bunch of worker or compute nodes running containerized workloads or applications.
Then, let’s explore some scenarios.
Scenario 1: Think of an operating model where a node (without an expensive HA solution) goes down which usually would trigger a priority severity incident and ticket is assigned to an administrator and the node issue is resolved within the expected time bound by the service level agreement or objective. Further, imagine a database or an application going down due to an underlying compute node problem which waits for humans with expertise to intervene, resolve the issue and bring them up. In this scenario, traditionally, there would be relevant events /alerts following which human help desk gets involved, a human system admin gets involved, a human database admin or application admin gets involved and so on. This scenario heavily relies on a combination of tooling, resources, process, skills, humans, responses, human behaviour, timing etc.
Scenario 2: Now, let us look at another scenario. A worker node of Kubernetes cluster goes down which is leveraging underlying IaaS. Assume the billing is on an hourly basis for the IaaS here (almost all cloud providers have that), operators are not going to spend time in resolving node down issue if it is not quick. Simply, throw the node out of the cluster and add a new one. Kubernetes is smart enough to schedule / re-schedule the pods across the nodes. Of course, it is assumed (rightly so) that the sizing and design aspects are proper. Even the configuration can include eviction behaviour, scheduling behaviour, placement rules etc. (for failure scenarios), and auto-scalability aspects to take care of the scaling and load balancing within the cluster.
Scenario 3: Requirements, with consideration of certain set of tools or patches must be installed on compute machines. Traditionally, they are installed either by humans manually or sure by imperative automation (i.e. automation with frequent human intervention in simple terms).
Scenario 4: Same above requirements like tools installations and more like patching, upgrades, observability, auto-pilot, runbooks execution etc. get performed in a declarative automated manner (human knowledge codified) using Kubernetes Operators — a few consistent easy buttons to be pushed.
Scenarios 2 and 4 here are great examples of Kubernetes-native target operating model (KTOM).
While operating models and their definitions may broaden depending upon the type of digital transformation journeys clients take — it can include new ways of working or a simple declarative automation or immutability or culture or consumption or agility or adoption or process re-engineering or innovation — or a simple mindset change and so on.
Kubernetes-native target operating model (KTOM) must enable innovation, speed, must be insights-driven, enable collaboration by design, blur (or minimize) the boundaries between Devs & Ops & Apps & Sec (DevSecAppOps) at the least, leverage declarative automation, be fault-tolerant by design, leverage native continuous integration / delivery, be codified (at infrastructure or application level), embrace resilience engineering integrating human factors, leverage bots & operators, leverage immutability where possible, provide interoperability, support natively pluggable integrations with external ecosystem, provide circuit breakers, adjust blast radius, withstand chaos, leverage API economy, not wait for humans, provide observability, provide services consistency, provide user consistency, provide consumption consistency and so on. It is obvious that it must use (or integrate with or extend) Kubernetes API and other components (e.g., controller, scheduler, YAMLs etc.).
It further propels the power of operating model of Kubernetes-native platform. So, in a nutshell, when human architects think of designing a Kubernetes-native solution, they must think of designing a system where heavy lifting should be mostly (or always) done by the Kubernetes and its containerized or containerization enabled ecosystem. Containers and Kubernetes based systems (or services) work well when they hand-shake with (or interface with like-minded developed or engineered system) modern technologies, modern processes, modern thinking, and relevantly skilled resources — when this happens, it results into a Kubernetes-native operating model.
In the current era of digital transformation, it must complete its cycle gracefully. The configurations are becoming complex, dynamic and demand is increasing to withstand the transformation capabilities. Kubernetes-native operating model should be at its core.