
Guest post originally published on the Elastisys blog
Going live with your application and deploying it to production on Kubernetes means you are exposing it to your end users. You want this to be a successful rollout, and to feel confidence. Confidence in your capacity management, security posture, disaster recovery processes… you name it. Now, it’s for real!
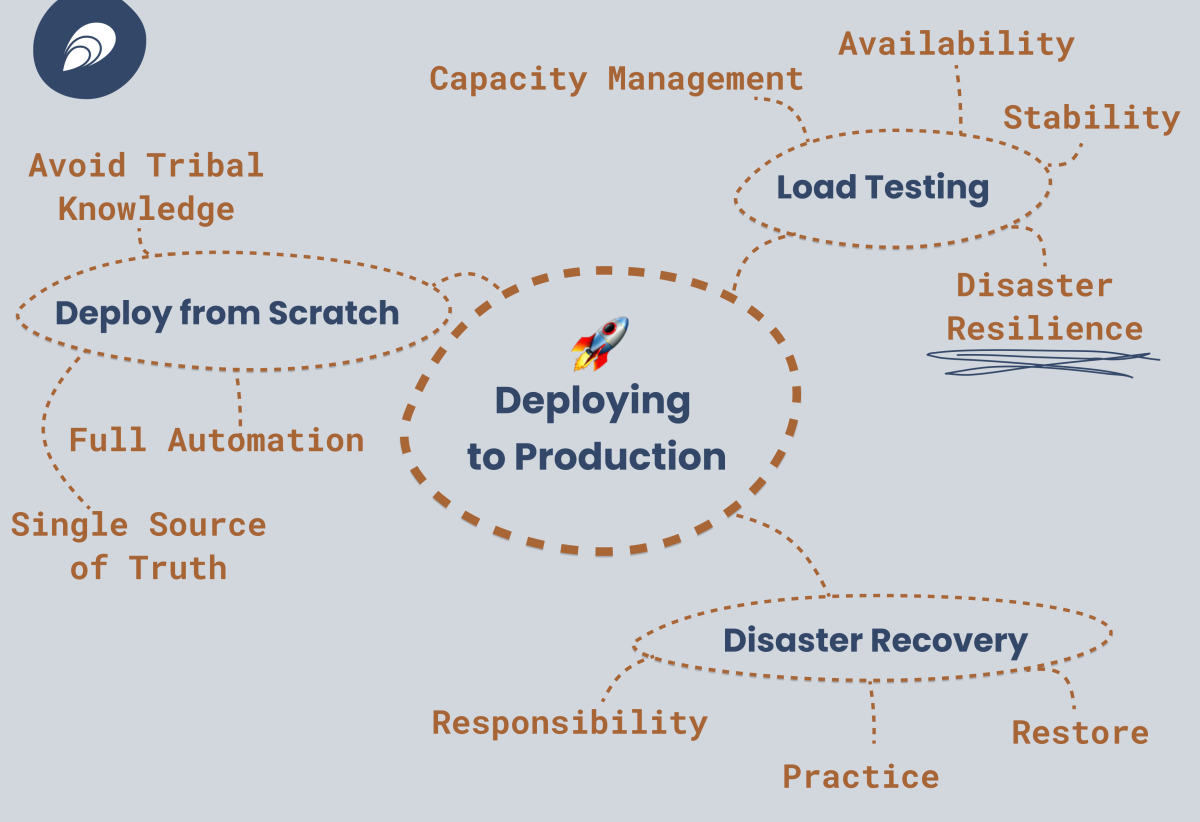
In this article, we cover the best practices that we recommend to everyone who is about to go live with their application and deploy it to production. You will learn what to do, how to do it, and why. All in the interest of you having dependable operations and being able to focus on improving your application: not firefighting when things break.
The Immense Value of Multi-Scenario Load Testing
Before going live with a new version of your application, or the initial one, you need to be able to load test it. You can either use a synthetic load generator such as JMeter or Locust or replay a recorded set of user interactions via something like Selenium.
Why would you do load testing?
Many reasons, actually! Of course capacity management is one of the reasons, but it’s certainly not the only one!
Plain Load Testing (Capacity Management)
Why? To ensure that enough capacity was allocated for the environment and application.
How? Set up a synthetic workload generator or replay a relevant workload. Ask the platform’s administrator to monitor your environment’s capacity usage. Make sure to include the performance and capacity of related components. You know, ones necessary for application logs and application metrics, for instance. All the supporting systems in your platform.
What? A plain and simple load test, performed for capacity management reasons. Note response times. Produce statistics on the average, median, 90th and 95th percentile response times.
Desired outcome: Allocated capacity is found to be sufficient.
Possible resolution: (Application developers) ensure the application has proper resource requests and limits. (Platform operators) ensure Kubernetes platform components and underlying cluster have sufficient capacity.
While Updating the Application (Availability)
Why? To ensure that the application can be updated without downtime, giving the proper availability guarantees one expects.
How? Make a trivial change to your application, e.g., add “Lorem ipsum” in the output of some API, and redeploy.
What? A load test that is performed while the application is running and subjected to load. Make sure to record any failures in your load testing tool.
Desired outcome: Measured downtime is acceptable (whatever that means for you).
Possible resolutions: Make sure you have the right deployment strategy. Prefer RollingUpdate over Recreate. Ensure other parameters of the deployment strategy are tuned as needed.
While Updating the Cluster (Availability, Stability)
Why? Node failure may cause application downtime. Said downtime can be large if it happens at night, when administrators need to wake up before they can respond. Also, administrators need some extra capacity for performing critical security updates on the base operating system of the Nodes.
How? Like a plain vanilla load test, but now ask the administrator to perform a rolling reboot of all Kubernetes cluster Nodes.
What? A load test that is performed while the application is running and subjected to load. Make sure to record any failures in your load testing tool. Ideally, there should be none.
Desired outcome: The measured downtime (due to Pod migration) during Node failure or drain is acceptable. Capacity is sufficient to tolerate one Node failure or drain.
Possible resolutions:
- Ensure the application has proper resource requests and limits.
- Ensure the application has at least two replicas, in combination with
- ensuring the application has topologySpreadConstraints such that Pods do not end up on the same Node.
The two latter ones will make it so that both replicas of the deployed application component are not both subject to downtime simultaneously.
While Taking Down a Cloud Region (Disaster Resilience)
Why? If you are deploying across multiple regions, your additional resilience must be tested. Otherwise, regional failure may cause application downtime.
How? As above, but now ask the administrator to take down an entire region.
What?
Desired outcome: The measured downtime (due to Pod migration) during region failure is acceptable. Capacity is sufficient to tolerate one region failure.
Possible resolutions:
- Ensure the application has proper resource requests and limits.
- Ensure the application has at least two replicas, and
- ensure the application has topologySpreadConstraints to ensure Pods do not end up in the same region.
The two latter ones will make it so that both replicas of the deployed application component are not both subject to regional failure simultaneously. You should also make sure that they do not wind up on the same Node, as per the previous test.
Disaster Recovery: Establishing a Plan and Executing it
Why? This ensures that the application and platform team agree on who is responsible for what and who backs up what. This is much better than ending up thinking that “backing up this thingy” is the other team’s problem.
How? Ask the administrator to destroy the environment and restore from off-site backups. Check if your application is back up and its data is restored as expected.
Desired outcome: Measured recovery point and recovery time is acceptable.
Possible resolution: Ensure you store application data either in PersistentVolumes or in a (managed) database. For Compliant Kubernetes users, you may note that PersistentVolumes are backed up by default in Compliant Kubernetes using Velero. (Elastisys Managed PostgreSQL customers have backups and point-in-time recovery by default, as per the terms of service.)
Redeployment from Scratch to Ensure Automation
Why? This ensures that no tribal knowledge exists and your Git repository is truly the only source of truth. This is key: if not everything is written down in code and fully automated, you will have to find that one or two engineers that happen to know exactly what to do. Doing that is stressful enough in normal times. If they are on vacation, sick, or have left the company, it’s considerably worse.
How? Ask your administrator to “reset” the environment, i.e., remove all container images, remove all cached container images, remove all Kubernetes resources, etc. Redeploy your application.
Desired outcome: Measured setup time is acceptable.
Possible resolutions: Make sure to add all code and Kubernetes manifests to your Git repository. Make sure that relevant documentation exists.
Summary
This article has shown the many uses of load testing in getting your application ready for production and going live in front of your end users. We know this process works, and we know it provides tremendous value to perform.
How often should you do it? In a microservices world, you’re releasing new versions “all the time”. Your answer depends on your processes. Dedicate time to this, because in our experience, you will find problems that need to be addressed. More the first few times, fewer as time goes on.
By following these best practices, you are in a much better position. You can deploy with confidence, and your applications is ready to take the world by storm.