

Project post originally published on the LitmusChaos blog by the LitmusChaos maintainers

In cloud native computing, the applications are expected to be resilient, loosely coupled, scalable, manageable and observable. Because of containerization, there is a proliferation of microservices and they ship quickly. Microservices environments are more dynamic. In such an environment, making applications resilient means deploying the applications in a fault tolerant manner, but it also means building the application to sustain the faults happening on dependent (i.e., upstream/downstream) services and continuing to take appropriate action against the incidence of such a failure. Similarly, quality assurance teams should cover all the fault scenarios to be covered during the CI and CD process. Eventually, Ops teams must continue testing the service for resilience in production by practicing Chaos Engineering. Continuous verification can be and should be practiced at all stages of the product life cycle.
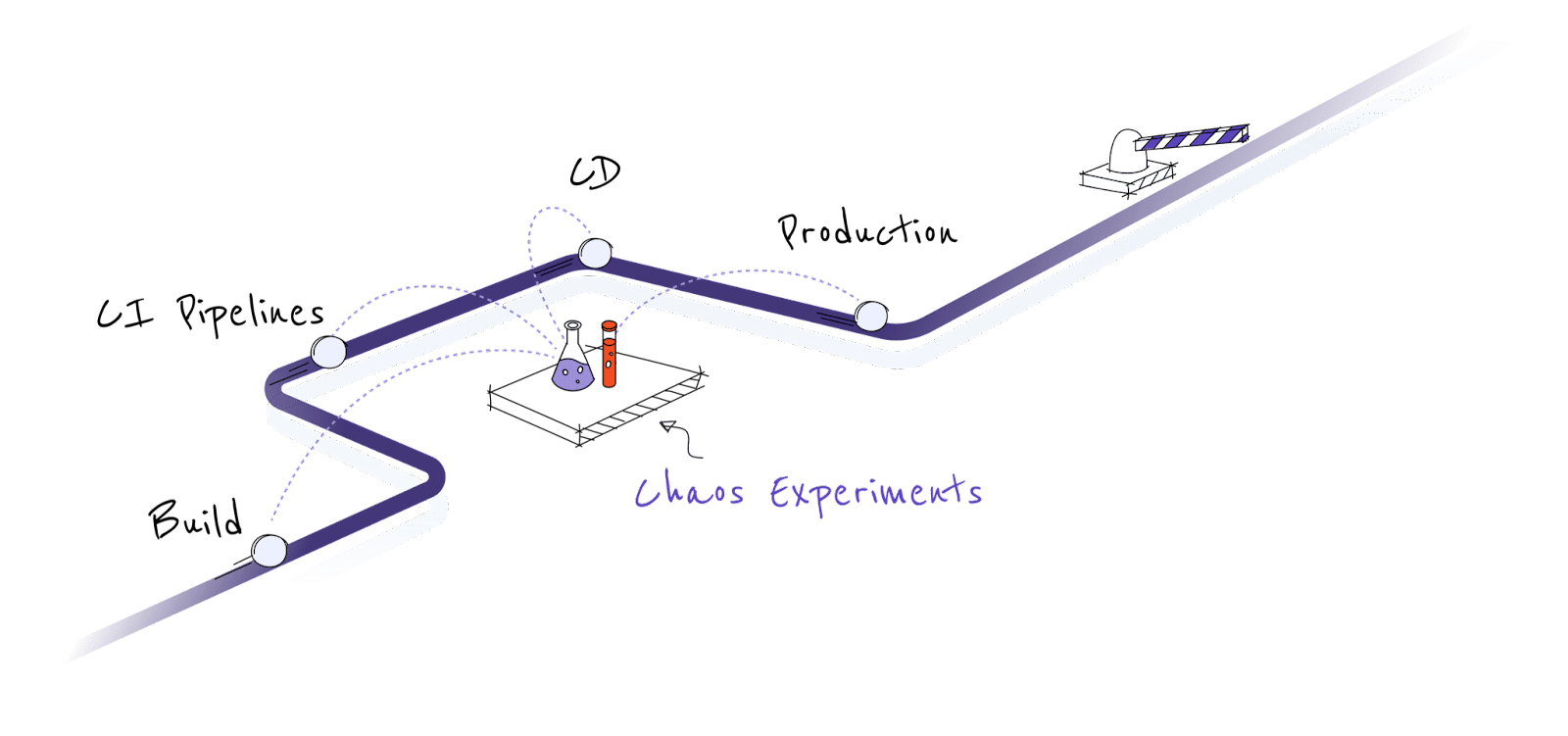
Chaos Engineering for Developers
Cloud native developers follow Curly’s law while developing microservices. This enables modularization and faster shipping of applications, but also necessitates creating a set of well defined conditions in the code to handle various microservices faults, the API responses and the underlying platform such as Kubernetes. While Kubernetes plays a major role in enabling microservices architecture, it also brings certain assumptions that developers should be aware of. For example, the frequency with which pods are evicted or moved around nodes is several times greater then, say, VMs getting moved across in an ESX cluster. In a scaled environment, pod eviction can happen at any time (depending on the load conditions and other environmental factors), but the service should continue to work just fine.
A host of chaos tests can be performed during development to build resilience against Kubernetes faults and common cloud native infrastructure application faults. LitmusChaos, which is a cloud native application, provides all the capabilities to practice end-to-end Chaos Engineering. Its chaos experiments are declarative in nature and cloud native developers can add or execute chaos experiments in a cloud native way. The core of Litmus operates on the basis of Chaos CRDs, which makes the practice of chaos for cloud native developers very natural.

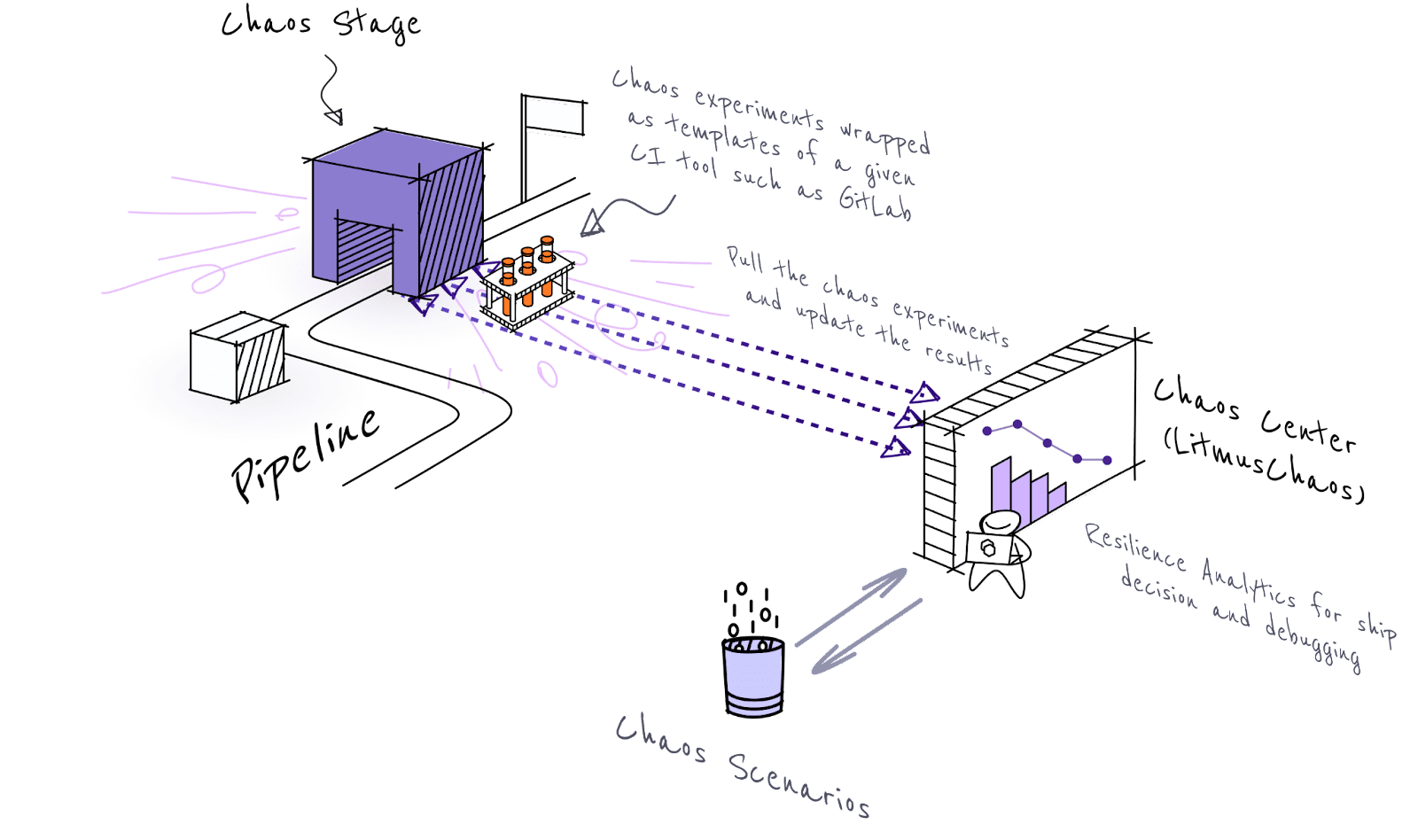
Chaos Engineering in CI
Cloud native CI/CD pipelines throw additional requirements for QA teams. They need to test the applications against various features of the cloud native platform functions such as Kubernetes. Kubernetes environments can present various faults such as pod, node and service level faults. In a chaos integrated CI pipeline, chaos experiments are designed to cover all fault scenarios of Kubernetes and other cloud native stack components, in addition to specific application faults
Apart from being able to execute chaos experiments easily for various different scenarios, quality assurance teams can measure the performance of resilience metrics of the application from build to build. Litmus is such a tool, where resilience metrics are easily compared against the chaos runs against different versions of the system under test.
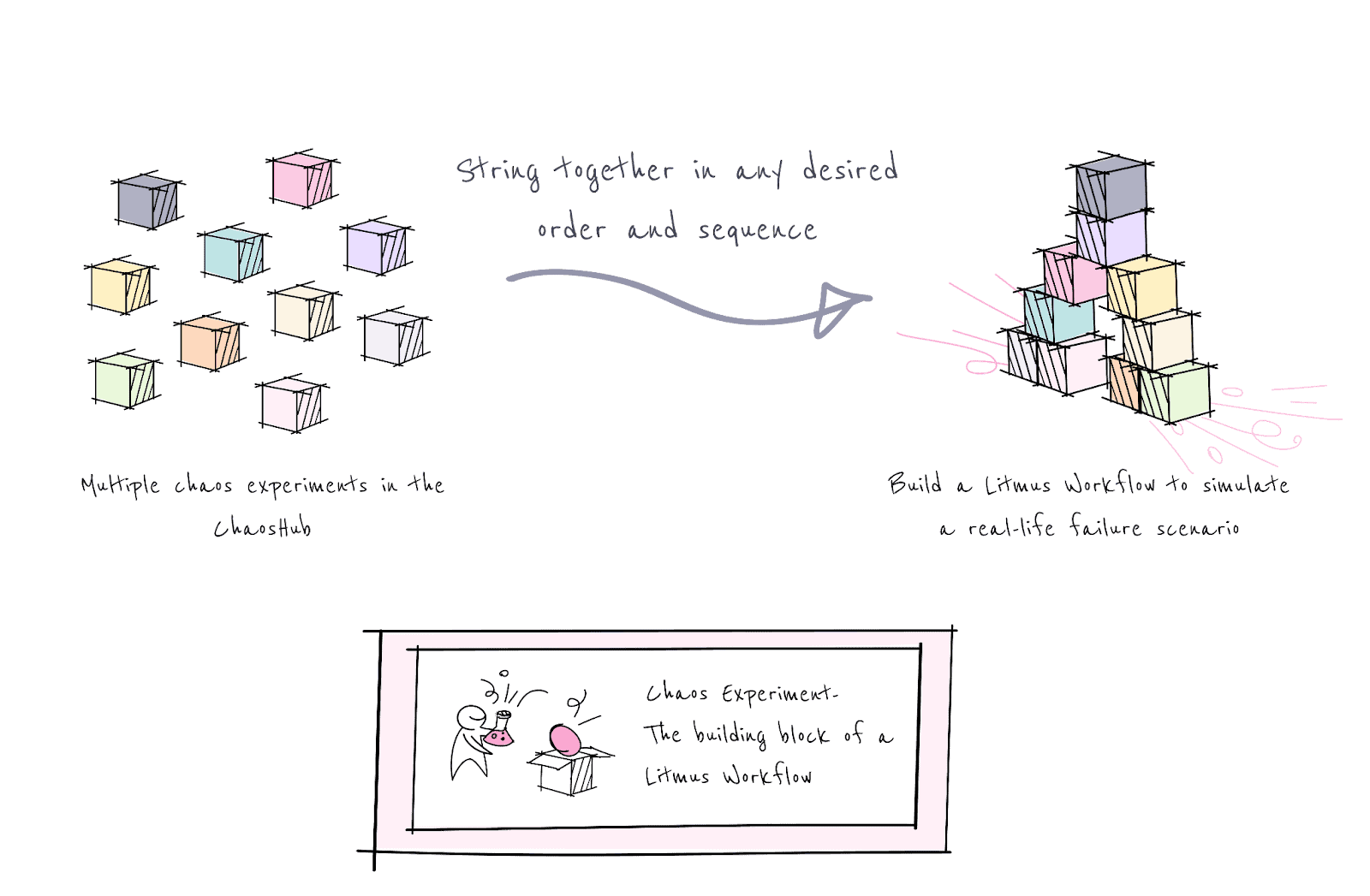
LitmusChaos workflows or scenarios
Chaos experiments serve as the building units for Chaos Workflows, which string together multiple chaos experiments in any desired order and sequence to inject failure into more than one resource. This allows for the creation of complex, real-life failure scenarios involving several different aspects of the entire application as part of a single workflow, simply using the ChaosCenter web UI. Think of Chaos Experiments as Lego blocks encapsulating failure conditions for a specific target resource. These Lego blocks can be flexibly arranged in any desired order to shape the Chaos Workflow — a conglomeration of failure scenarios tailored to validate your specific SLO requirements.
Introducing chaos tests into developer CI/CD pipelines
LitmusChaos provides the ability to create workflows through chaos center and use them in different ways. For using the workflows in CI/CD pipelines, the easiest way is to store the created chaos test in git. If you configure GitOps in Litmus, the workflows are automatically stored in Git and you can edit the test either directly on git or through the chaos center. Once the test (A YAML manifest) is in Git, you can invoke it in your CI pipeline by creating a kubernetes shell environment and executing
“kubectl apply -f http://<github.com>/your-repo/your-file.yml”
The above commands does the magic of getting your chaos experiment, setting up the execution environment, executing the chaos test and uploading the results/metrics to chaos center.
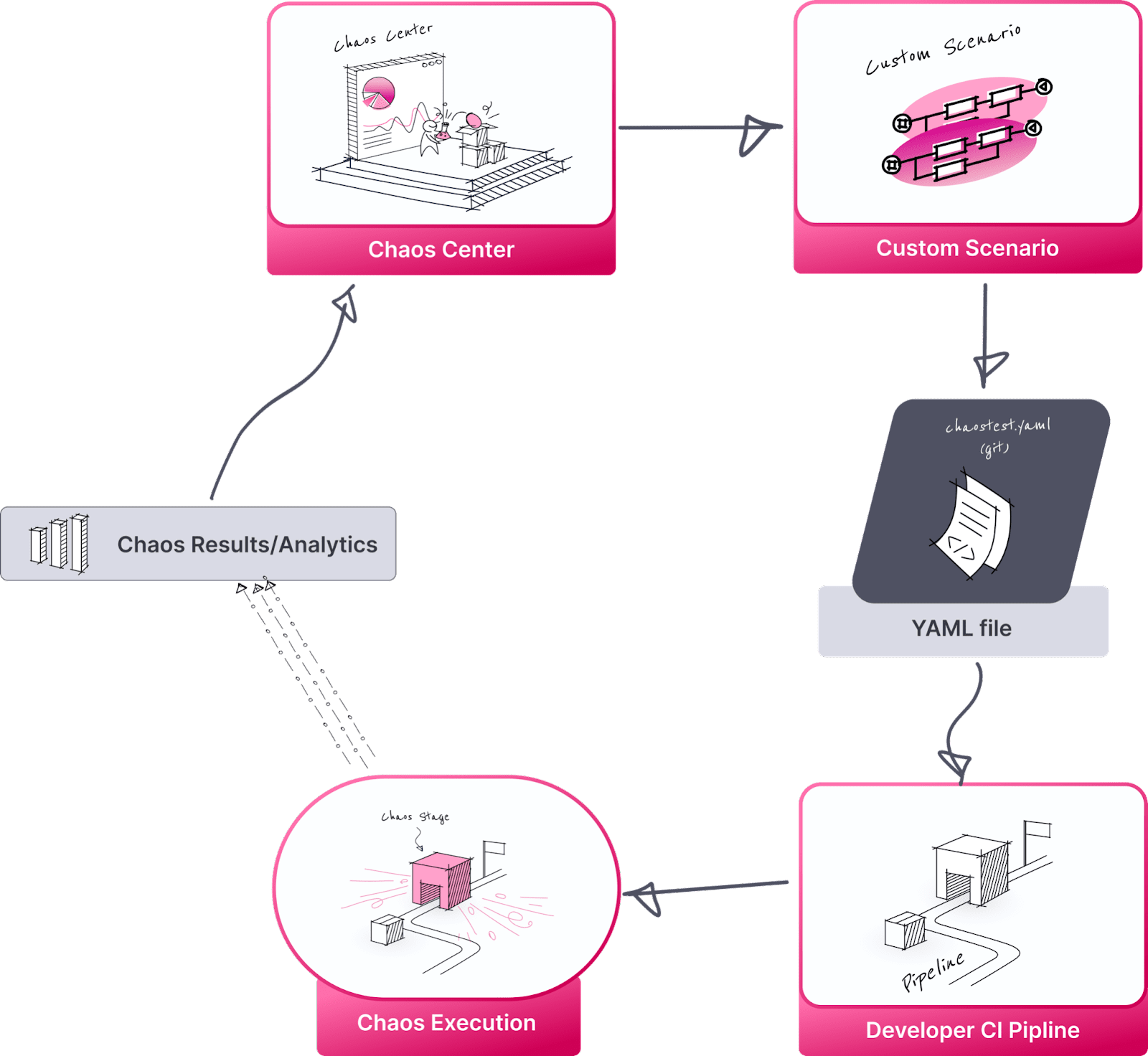
Basically, developers can construct their CI.yaml files by inserting “kubectl apply -f <chaostest.yaml> and observe the results in the chaos center. Chaos center provides analytics around historic workflow executions that help to know if the resilience of your application you are developing is increasing or intact assuming that you have provided good chaos coverage.
Here is an example of how Litmus chaos tests are used on a CI/CD platform, which in this case is Harness: https://dev.to/ksatchit/chaos-engineering-with-harness-cicd-pipelines-1dn0
One can use the Litmus chaos tests in the same way on other CI platforms such as GitLab, CircleCI etc.