

Guest post originally published on the Gemini Open Cloud blog by Patrick Fu, CEO of Gemini Open Cloud
The default scheduler is a very matured component of Kubernetes cluster management. It is working quite well for most of the cases. However, there are still some use cases that the Kube scheduler is not designed for. For example:
- The default Kube scheduler is a Task scheduler, not a Job scheduler. The default scheduler schedules one POD at a time based on the scheduler policy. But if you have a job that requires multiple tasks (PODs) to coordinate with each other, there is no control on when the tasks will be completed. This can lead to unnecessary waiting and overall decrease in performance for the job.
- A lot of modern computing tasks (e.g. Machine Learning) requires accelerators, such as GPU or FPGA. However, the default scheduler only considers worker node resources such as CPU core, memory, network, and disk. So the scheduler may end up selecting a sub-optimal worker node for a POD.
Kubernetes does allow users to extend the default scheduler. In fact, Kubernetes allows multiple schedulers to co-exist in a cluster, so you can still run the default scheduler for most of the pods, but run your own custom scheduler for some special pods. There are a couple of ways to customize the default scheduler.
Custom Resource Definition (CRD)
CRD is a mechanism in Kubernetes to allow users to define their own controller for custom objects. The idea of this approach is to implement your own scheduler for special type of K8S POD resources.
The advantage of the CRD approach is that it is entirely isolated. Such scheduler change is applied only to custom resources. It will not impact the system behavior on existing object. Also, the CRD controller is independent of the default controller. The only touchpoint is via the API server. W hen Kubernetes has to be upgraded, it does not require extra code modification and testing of the CRD controller.
The disadvantage of the CRD approach is that it required the application to modify its POD specification to use the special custom defined resources. Also, the CRD scheduler co-exist with the default Kube scheduler. Although they are independent processes, the co-existence of multiple schedulers might have more problems than it sounds like, such as a distributed lock and cache synchronization.
Scheduler Extender
The other approach to customize Kube scheduler is via the Scheduler Extender. The mechanism here is a webhook. A webhook is a method of augmenting or altering the behavior of a web application with custom callbacks. The scheduler extender approach is the most viable solution at this moment to extend scheduler with minimal efforts and is also compatible with the upstream scheduler. The phrase “scheduler extender” simply means configurable webhooks, which corresponds to the two major phases (“Predicates” and “Priorities”) in a scheduling cycle.
But there are disadvantages to the extender approach as well. First, the scheduler extender only accommodates for limited extension points. It can only involve at the end of the Filtering and Scoring phase, so it may not provide enough flexibility for customization.
The other drawback is communications cost. For webhook, the data is transferred in HTTP between the default scheduler and the extender. The IPC cost may impact the overall performance of the Kube scheduler. We will describe the new scheduler Framework in the next section. The scheduler framework employs Plugins instead of webhooks. The Plugins are compiled into the same binary as the scheduler, so there is no overhead in inter-process communications.
K8S scheduler framework
In 1.19, Kubernetes introduced the new Scheduler Framework. This is a framework to allow the user to extend the behavior of Kube scheduler at much finer granularity (known as Stages) than the previous versions. Users can customize scheduler Profiles for specific POD kinds. Each stage is exposed as an Extension Point. Plugins provide scheduler customizations by implementing one or more of these extension points. Users define profile through the kube-scheduler configuration. Each profile configuration is separated into two parts:
- A list of enabled plugins for each extension point and the order they should run. If one of the extension points list is omitted, the default list will be used.
- An optional set of custom plugin arguments for each plugin. Omitting config args for a plugin is equivalent to using the default config for that plugin.
The Scheduling and Binding cycle are composed of stages that are executed sequentially to calculate the pod placement. The native scheduling behavior is implemented using the Plugin pattern as well, in the same way as the custom extensions, making the core of the kube-scheduler lightweight as the main scheduling logic is placed in the plugins.
Figure 3 shows an instance where the user specifies 2 profiles for the same scheduler. As you can see, the new scheduler framework allows users to defined plugins for 10 different extension points. A brief description of the extension points follows:
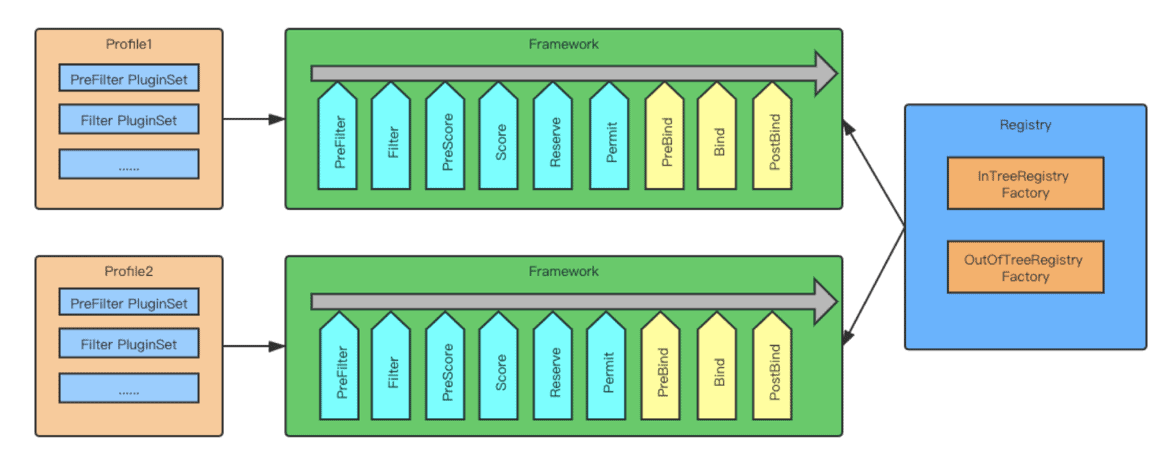
Extension points & plugin’s
- QueueSort — allows users to define the order of which PODs in the queue should be processed first.
- PreFilter — usually for users to exclude some specific worker nodes to be considered before scheduling a POD.
- Filter — before processing the filtering predicates in the scheduler policy, this plugin will be called.
- PostFilter — this plugin will be called if there’s not candidate worker nodes can accommodate the current POD being scheduled.
- PreScore — the list of worker nodes may be long. This extension point is intended to allow users to retrieve the status of the candidates and cached it in memory to increase the scoring performance.
- Score — allows users to adjust the relative weight and the scoring of the working nodes.
- Reserve/Unreserve — The binding of a POD to a worker node can take some time. To avoid racing condition, this plugin allows users to reserve a node, so no other POD can be considered for this node until the binding is completed.
- Permit — Allows users to call the permit extension to “approve” a binding. This is for some cases, where the user wants to revoke the bind under certain conditions.
- Prebind — allows the user to perform some actions (e.g. mount a volume) before the actual binding of the POD to this worker node.
- PostBind — for Cleanup operations after the bind is completed.
We also customized k8s scheduler to fit machine learning environment. Please refer to out next article to understand how to leverage it.
Gemini Open Cloud is a CNCF member and a CNCF-certified Kubernetes service provider. With more than ten years of experience in cloud technology, Gemini Open Cloud is an early leader in cloud technology in Taiwan.
We are currently a national-level AI cloud software and Kubernetes technology and service provider. We are also the best partner for many enterprises to import and management container platforms.
Except for the existing products “Gemini AI Console” and “GOC API Gateway”, Gemini Open Cloud also provides enterprises consulting and importing cloud native and Kubernetes-related technical services. Help enterprises embrace Cloud Native and achieve the goal of digital transformation.