


Guest post originally published on the Elastisys blog by the Elastisys team
We increasingly meet CTOs and cloud architects in need of a secure platform that can run on multiple clouds or on-premise to meet customer requirements. A mature platform must not only “run code”, but also outsource application state in databases, message queues and in-memory caches.
So what are the options of your platform team?
In this post, we’ll share how we built a portable, secure platform that standardises on Kubernetes. We hope that our article will inspire and bring confidence to anyone embarking on the same journey.
Multiple Proprietary Platforms or a Single Open One?
As recently highlighted by the Millennium Tower in San Francisco, even the most luxurious apartment is worthless without a solid foundation. Similarly, the security and uptime of your application requires a solid infrastructure. Unfortunately, infrastructure is complex and messy, and requires specialised skills to orchestrate it. (Raise your hand if you are both a full-stack developer and a BGP anycast wizard.)
To increase time-to-market and make engineering teams more productive, many companies have chosen to essentially outsource infrastructure engineering. Indeed, big cloud providers, such as AWS, Azure and Google, essentially hide all infrastructure complexity and offer a Platform-as-a-Service fueled by a proprietary control plane. This is great, because your team can focus their effort on your “magic source”, which is pushing high impact application features faster. This makes a lot of sense, since you can tremendously accelerate both application development, and dealing with security and compliance requirements by using configuration specific to the proprietary platform. When you are a start-up, onboarding the first free customers is the priority.
However, eventually you will scale up and bump into one of those big budget customers. Being more demanding about their data location, you’ll need to start running on their on-premise infrastructure or a different public cloud. Sadly, you’ll have to redo much of that investment that went into making the platform secure and compliant. Furthermore, you’ll likely need to update your processes and train your team. In the end, you are still left with dealing with significant differences between the two platforms.
Will you port your application to a second proprietary platform or will you build an open source, portable platform this time?
The architectural decision to standardise on Kubernetes
Being big fans of Kubernetes, we build and run the open source project Elastisys Compliant Kubernetes, a Kubernetes distribution focused on security and compliance. While we were definitely onto something, application teams were saying: “Cool! But, I need a platform, not just stateless container hosting. At the very least, I need the following additional services: primary database, in-memory low-latency cache and message queue.”
Upon hearing this, we went back to the whiteboard and brainstormed what our options are to run additional services on any cloud infrastructure, with security and compliance in mind. We saw two options:
- Build provider-specific support for each additional service.
- Build on top of Kubernetes.
One of my greatest nightmares: It’s easy to keep engineers busy writing code. But are they writing the right code? Hence, before implementing yet another proprietary platform control plane, we analysed what security and compliance requirements Kubernetes could fulfil as the engine for our platform. Here are the highlights:
- Capacity management: Running out of capacity is a major source of downtime. Furthermore, additional services may require special hardware, such as Nodes with SSD for databases and Nodes with large memory for in-memory caches.
In Kubernetes, each Pod can specify resource requests and limits – this is even enforced by default in Elastisys Compliant Kubernetes – to ensure both that Nodes have sufficient capacity, but also that misbehaving Pods don’t take the whole platform down. Furthermore, Kubernetes allows fine-tuned scheduling via taints and tolerations. Hence, it is easy to, e.g., run database containers on Nodes with SSD. - Private (in-cluster) network a.k.a. “VPC”: Additional services are not meant to be exposed on the Internet. In fact, low-latency in-memory caches like Redis assume a trusted network. With proprietary cloud control planes, one would put all additional services in a private network, also called a VPC, which includes firewalls, internal load-balancers and private DNS.
The exact same can be achieved via Kubernetes networking. NetworkPolicies act as firewalls – their usage is enforced by default in Elastisys Compliant Kubernetes – while Services take the place of internal load-balancers. Kubernetes even creates private DNS entries for Services.
Public network traffic usually passes via an Ingress Controller, which is configured to take care of encryption via HTTPS and automatic certificate rotation. - Strongly consistent, distributed key-value store: Some additional services follow a primary-secondary model. This requires leader election and primary fail-over.
Instead of implementing these algorithms for each additional service, one may use ConfigMaps to exploit the etcd database which fuels each Kubernetes control plane.
Projects integrating with Kubernetes can further bring the following benefits:
- Metrics collection, metrics-based alerting via Prometheus: Additional services will need monitoring, to detect symptoms before they become problems. For example, if detected early, a database replication lag can be quickly fixed by adding more capacity, instead of being surprised by broken replication and eventually data loss.
Additional services only need to implement a rather minimal metrics exporter and Prometheus will do the heavy lifting. - Log collection, log-based alerting via Fluentd: Additional services will need logging – especially audit logging – both for incident management and periodic log review, as required to detect “unknown unknowns”, i.e., signs of a pending attack or hidden malfunction.
Additional services only need to log on stdout or stderr. Kubernetes and Fluentd will handle the rest: Collecting logs and rotating logs, shipping them to a short-term full-text search engine like OpenSearch for convenience, as well as shipping them to long-term object storage for regulatory compliance.
Kubernetes: Not only an Engine, but also an API Standard
I hope the previous section convinced you that, while building your proprietary control plane for each additional service sounds fun, you can significantly accelerate development of your platform by building on top of Kubernetes. But Kubernetes can do even more! Behold, the Operator Pattern. The Kubernetes API can be extended via CustomResourceDefinitions. Some service-specific code – called the operator – abstracts away the tedious and boring parts, such as creating and destroying the additional service, scaling it up or down, or setting up replication and disaster recovery.
In fact, there is a plethora of open-source operators already available. Our favourite ones are the Zalando PostgreSQL Operator, the Spotahome Redis Operator and the RabbitMQ Operator. They all support:
- high-availability, i.e., setting the number of replicas;
- fine-tuning of capacity management via resource requests/limits and tolerations;
- metrics exporters.
The PostgreSQL operator even includes Point-in-Time Recovery.
Let us illustrate what YAML you need to write (“boring” parts were cut off for briefness) and what additional service you get.
PostgreSQL cluster
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: main
spec:
volume:
size: 30Gi
numberOfInstances: 2
enableLogicalBackup: true
postgresql:
version: "13"
parameters:
password_encryption: "scram-sha-256"
resources:
requests:
cpu: "1"
memory: 4Gi
limits:
cpu: "1"
memory: 4Gi
tolerations:
- key: nodeType
operator: Equal
effect: NoSchedule
value: database
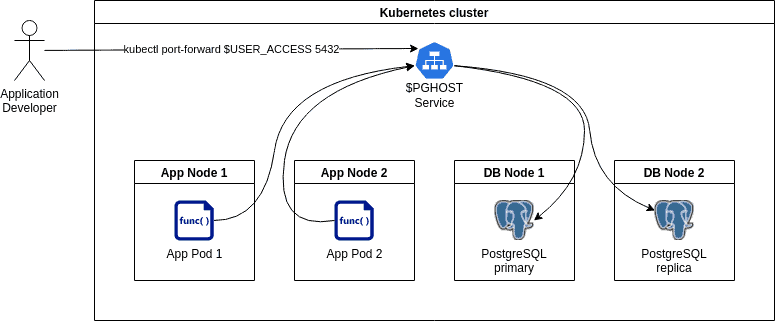
Redis cluster
apiVersion: databases.spotahome.com/v1
kind: RedisFailover
metadata:
name: redis-cluster
namespace: redis-system
spec:
sentinel:
replicas: 3
resources:
requests:
cpu: 100m
limits:
memory: 100Mi
redis:
replicas: 3
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 400m
memory: 500Mi
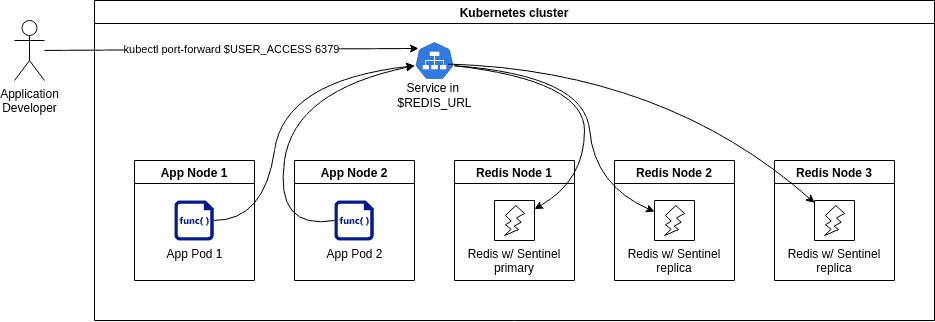
RabbitMQ cluster
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: rabbitmq-cluster
namespace: rabbitmq-system
spec:
replicas: 3
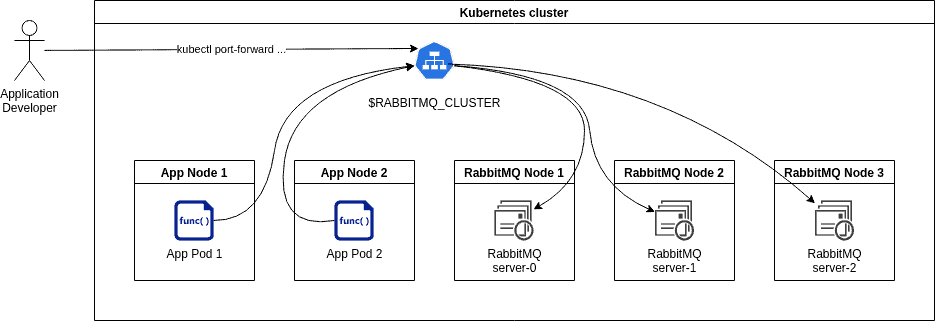
Our Experience from Standardising on Kubernetes
We run this setup in production for our customers on multiple EU cloud providers, which, as you might expect, don’t have the same set of platform services. Long story short: It works!
We found the setup a win-win: You get a platform that is future proof. Onboarding a new cloud infrastructure is easy. Migrating the application on a new cloud infrastructure is easy. Your application runs on one platform on any infrastructure.
Your platform team will love it: Administration of the platform is rather smooth, and many tedious and error-prone tasks are eliminated. Thus, your platform team can truly focus on the tricky cases, and continuously improve and secure the platform.
Afterthought: Saves time doing, but not time learning
This all sounds too good to be true. So … no downsides?
As Joel wrote it almost a decade ago, “abstractions save us time working, but they don’t save us time learning”. You cannot expect application developers to be “mystical DevOps wizards” who can be woken up at night for all issues ranging from ReactJS exceptions reported in Sentry to performance bottlenecks due to Linux futexes. There is one thing to “know” and another thing to be sufficiently current to solve issues before they become a problem, in high-stress situations.
While tech is not a silver bullet, Kubernetes can help create a natural delimitation between your application and platform teams. Furthermore, it provides shared vocabulary to foster shared understanding and smoother operations. Instead of having needless blame-games, both teams win by collaborating from their stack layer on making the application secure and stable.