





Guest post originally published on Eficode’s blog by Michael Vittrup Larsen
Kubernetes is ubiquitous in container orchestration, and its popularity has yet to weaken. This does, however, not mean that evolution in the container orchestration space is at a stand-still. This blog will put forward some arguments for why Kubernetes users, and developers, in particular, should look beyond the traditional Kubernetes we have learned over the past few years to paradigms that may be better suited for cloud-native applications.
The rise of Kubernetes
Part of the reason why Kubernetes has become so popular is that it was built on top of Docker. Containers have a long history in Linux and BSD variants; however, Docker made containers extremely popular by focusing on the user experience and made building and running containers very easy. Kubernetes built on the popularity of containers and made running (aka. orchestrating) containers on a cluster of compute nodes easy.
Another reason for Kubernetes’ popularity and extensive adoption is that it didn’t change the model for running software too much. It was reasonably easy to envision a path from how we ran software before Kubernetes to how we could run software on Kubernetes.
You can’t teach old paradigms new tricks
Building container images to freeze dependencies and a ‘run everywhere’ experience combined with Kubernetes Deployment resource specifications to manage the orchestration of container replicas is very powerful. However, it’s not radically different from how we operated VMs before Docker and Kubernetes. The small mental leap made it easy to adopt Kubernetes, but it is also why we should look beyond the ‘traditional’ Kubernetes we know today.
This blog will look at the future of Kubernetes as seen from the developer’s perspective. Generally, the Kubernetes we know today will disappear, and developers will not care. This is not to say that we will not have Kubernetes in our stack, but we will improve the way we build and operate applications using new abstractions, which are themselves built on top of Kubernetes. Applications will be built using platforms built on the Kubernetes platform:
Interestingly, Linux was the platform upon which we built everything a decade or more ago. Linux is still ubiquitous, and part of our stack, but few developers care much about it because we have since added a few abstractions on top. It’s the same that will happen to the traditional Kubernetes we know today.
New paradigms sweep clean(er)
Security: OIDC is better than secrets
Kubernetes provides a Secret resource to specify static secrets such as API keys, passwords, etc. Developers should not use the Kubernetes Secret resources.
Explicit secrets encoded in Secret resources can be leaked and are troublesome to rotate and revoke. With GitOps workflows, secrets also need special attention to avoid being stored in clear-text. Applications should instead apply a role-based approach to authentication and authorization. This means that instead of ‘things you know’ (passwords, API keys), application authentication and authorization should be based on ‘who we are’.
Strong identities are the foundation for all security. It does not make sense to encrypt network traffic if you are not sure about the identity of the server you communicate with. This is what certificates and Certificate Authorities do for HTTPS traffic, which generally secures the internet.
Kubernetes has a system for strong workload identity. All workloads are associated with service accounts, and they have short-lived OpenID-Connect (OIDC) identity-tokens issued by Kubernetes. The Kubernetes API server signs these OIDC tokens, and other workloads can validate tokens through the Kubernetes API server. This provides strong identities for workloads running on Kubernetes and can be used as a foundation for role-based authentication and authorization.
Instead of using Kubernetes Secrets, developers should base authentication and authorization on OIDC tokens. This means that instead of, e.g., storing a database password in a Secret resource, we should ensure that our database only accepts requests when presented with a valid, unexpired token.
Examples of OIDC token usage to integrate with external systems are AWS IAM roles for service accounts and Hashicorp Vault Kubernetes auth.
Networking: Ingress does not cut the mustard
Kubernetes provides an Ingress resource to specify how to route HTTP traffic into workloads. As Tim Hockin (Kubernetes co-founder) acknowledges, there is a lot wrong with the Ingress resource. The primary problem is that it only lets us manage the very basics of HTTP traffic routing. Allowing developers to use Ingress resources will be a headache for infrastructure and Site Reliability Engineering (SRE) teams that need to interconnect an extensive infrastructure and make it run reliably. The Ingress resource is too simple, and developers should not use it to configure networking.
The need for more control and programmability of the Kubernetes network can be seen in the rise of service meshes (see our training course on Istio service mesh, Kiali and Jaeger). They divide the Ingress resource into multiple resources for a better separation of duties and provide additional functionality in routing, observability, security, and fault tolerance.
More and more abstractions built on top of Kubernetes assume a programmable network beyond what is possible with Ingress (Knative, Kubeflow, continuous-deployment tools like Argo Rollouts, etc.). This emphasizes that a more robust network model in Kubernetes is already a de-facto standard.
The Kubernetes community has evolved an ‘Ingress v2’ – the gateway-API. While this addresses some of the concerns of Ingress, it only covers a small subset of the functionalities that most service meshes support.
Kubernetes supports ACLs for limiting which workloads can communicate through the NetworkPolicy resource. This resource is implemented in the Kubernetes network plugins and often translates into Linux iptables filtering rules, i.e., an IP address-based solution much like firewalls – again, an old paradigm. Some service meshes extend the strong Kubernetes OIDC-based workload identities to implement mutual TLS between workloads. This brings confidentiality and authenticity to Kubernetes network communication based on stronger principles than IP addresses.
In Kubernetes application packaging, there is some divergence in how to include network configuration. Many Helm charts come with Ingress resource templates. However, as we move to more advanced network models, those definitions cannot be used. Looking forward, application deployments like Helm charts should consider network configuration an orthogonal concern that should be left out of the application deployment artifact. There may not be a one-size-fits-all solution regarding application network configuration, and organizations most likely want to develop their own ‘routing-for-applications’ deployment artifacts.
Kubernetes made networking easy by creating a homogeneous network across all nodes in the cluster. If your application is multi-cluster or multi-cloud, it may similarly benefit from a homogeneous network across clusters or clouds. The Kubernetes network model does not do this, and you need something more capable like a service mesh.
Thus, from an organizational and architectural perspective, there are several reasons why developers should not program the network with Ingress resources. It is essential to consider the options with an overall organizational view to ensure a manageable and long-term viable approach to network configuration and management.
Workload definition: To the point
At the core of practically all Kubernetes applications is a Deployment resource. A Deployment is a resource that defines how our workload, in the form of containers inside Pods, should be executed. Deployment scaling can be controlled with a HorizontalPodAutoscaler (HPA) resource to account for varying capacity demand. HPAs often use container CPU load as a measure for adding or removing Pods, and due to the HPA algorithm often with a target utilization in the area of 70%. This means we are designing for a waste of 30%. Another reason for using conservative target utilizations is that the HPA often works with a response time of a minute or more. To handle varying capacity demand, we need some spare capacity while the HPA adds more Pods.
Managing workloads with Deployments and HPAs works well if our application sees slowly varying capacity demand. However, with the shift towards microservices, event-driven driven architectures, and functions (which handle one or possibly a few events/requests and then terminate), this form of workload management is far from ideal.
The Kubernetes Event-Driven Autocaler (KEDA) can improve the scaling behavior of microservices and fast-changing workloads such as functions. KEDA defines its own set of Kubernetes resources to define scaling behavior and can be considered an ‘HPA v3’ (as the HPA resource is already at ‘v2’).
A framework that combines the Kubernetes Deployment model, scaling, and event and network routing is Knative. Knative is a platform that builds on top of Kubernetes and takes an opinionated view on workload management through a Knative-Service resource. At the core of Knative is CloudEvents, and Knative services are basically functions triggered and scaled by events, either CloudEvents or plain HTTP requests. Knative uses a Pod sidecar to monitor event rates and thus scales very quickly on changes in event rates. Knative also supports scaling to zero and thus allows for a finer-grained workload scaling better suited for microservices and functions.
Knative services are implemented using traditional Kubernetes Deployments/Services, and updates to Knative services (e.g., a new container image) create parallel Kubernetes Deployment/Service resources. Knative uses this to implement blue/green and canary deployment patterns, with the routing of HTTP traffic being part of the Knative service resource definition.
Thus, the Knative service resource and its associated resources for defining routing of events become the primary resource for developers to use when defining their application deployment on Kubernetes. Much like we today often interact with Kubernetes through Deployment resources and let Kubernetes handle Pods, using Knative means developers will mainly concern themself with the Knative service, and Deployments are handled by the Knative platform.
While I expect the Knative model to suit a large majority of use cases, your mileage may vary. If you instead are doing machine learning, then maybe Kubeflow is a better abstraction. If you are more focused on DevOps and delivery pipelines, then kpack, Tekton or Cartographer may be the abstraction for you. Whatever you do on Kubernetes, there’s an abstraction for that!
Storage: Moving away from persistent volumes
Kubernetes provides PersistentVolume and PersistentVolumeClaim resources for managing storage for workloads. It’s probably my least favorite resource to allow developers to use for anything but ephemeral cache data.
From a high-level perspective, a problem with PersistentVolumes (PVs) is that they combine the primary concern of our application with a storage concern, which is not an ideal cloud-native design pattern. The twelve-factor app methodology guides us to consider any backing services as network-attached. This is due to how we horizontally scale workloads in Kubernetes and the management of data (think CAP theorem).
PVs represent file systems of files and directories, and we operate on data with a POSIX file-system interface. Access rights are also based on a POSIX model, with users and groups being allowed read or write access. Not only is this model poorly matched to cloud-native application design, but it’s also tricky to use in practice, which means that most often, PVs are mounted in a ‘container can access all data’ mode.
Developers should build stateful applications that are stateless. This means data should be handled externally to the application using other abstractions than filesystems, e.g., in databases or object stores. Database and object store applications may use PVs for their storage needs, but these systems should be administered by infrastructure/SRE teams and consumed as-a-service by developers.
A dramatic improvement in data security is possible when we consider storage as network-attached, e.g., consider object storage through REST APIs. With REST APIs, we can implement authentication and authorization through short-lived access tokens based on Kubernetes workload identities as described above.
With the adoption of a serverless workload pattern, we should expect more dynamic and shorter-lived workloads (e.g., serverless functions handling one event per Pod). The mismatch between workloads and ‘old-fashioned disks’ becomes even more apparent in such situations.
In Kubernetes, the container storage interface (CSI) has been the interface for adding file-system and block storage to workloads through PVs. The Kubernetes special interest group on object storage is working on a container object storage interface (COSI) which may turn object storage into a first-class citizen in Kubernetes.
O brave new world
In this blog, I have argued that there are good reasons to look beyond the ‘traditional’ Kubernetes resources when defining Kubernetes applications. This is not to say that we will never use the traditional resource types. There will still be legacy applications that we cannot easily convert, and SRE teams may still need to run stateful services that can be consumed by applications built by developers. This will particularly be the case for private cloud infrastructures.
The future of Kubernetes is in the custom resource definitions (CRDs) and abstractions which we build on top of Kubernetes and make available to users through CRDs. Kubernetes becomes a control plane for abstractions, and it’s the CRDs of these abstractions that developers should focus on. Kubernetes control planes may manage resources inside Kubernetes or even outside Kubernetes as, e.g., Crossplane manages cloud infrastructure.
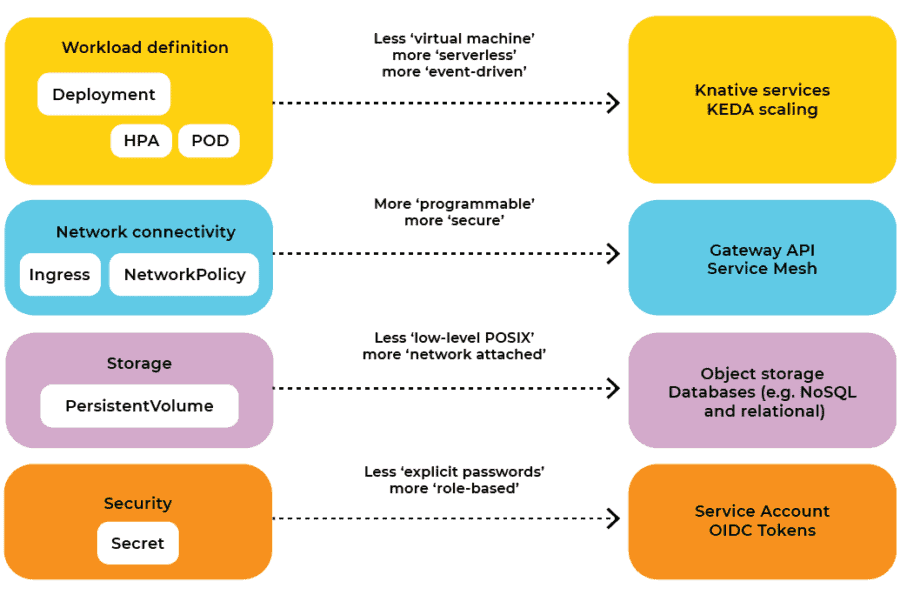
As summarized above, the majority of the traditional Kubernetes resources may have better alternatives for developers. Using alternatives will improve how we develop and operate cloud-native applications in the years to come. After all, Kubernetes is a platform for building platforms. It’s not the end-game!
Want to hear Kelsey Hightower’s view on this topic? Watch the recording of his talk at The DEVOPS Conference 2022: https://hubs.li/Q0175XCl0