
Guest post originally published on Netris’ blog by Alex Saroyan
Let’s be honest, nobody wants to deal with networking, but we can’t serve our applications without investing time and money in developing a good network design and setting up some basic operational procedures. How we connect our application islands (most likely Kubernetes) to the rest of the world can make or break the user experience.
Back in the days when my team and I were operating data center networks, the edge of the network had to use quite a number of technologies co-existing together. Border routers, load balancers, firewalls, VPN concentrators – we had at least two of each in every data center for redundancy. We were getting service changes and implementation requests from application and business units almost every day. The big challenge was that tiny mistakes in tedious network device configuration would lead to terrible outages. Change implementation was taking time and caused back-and-forth between engineers, leading to long delays. Back then it was expected that “Networking is hard and complicated so you need to wait a bit”
Network outages due to human error still exist even, no matter how big the size of your company!
We can’t blame network engineers. The problem is that standard networking products are overcomplicated and are not fundamentally designed for automation or automatic operation.
The public cloud has raised the bar for infrastructure change implementation.
Every private network requires some sort of gateway to peer with other networks. Public cloud providers offer the network services on-demand and automatically. When any of your resources need to communicate with hosts beyond your VPC (ex. access Internet), your traffic travels through Internet Gateway service (in AWS terminology), or NAT (Network Address Translation) gateway services.
When your traffic needs to leave the border of the data center (region in AWS terminology), you are using the service of the border router. The border routers maintain connectivity with many Internet providers (top tier Internet carriers and Internet exchange points). For every network packet needing to leave a particular region, the border routers need to compare the destination IP address with the full Internet routing table (900k+ routing records) to decide what is the best route for forwarding.
Traffic in the opposite direction also applies here. When you expose applications to the public Internet you use the service of an on-demand load balancer, which is another service that belongs in the gateway layer. A load balancer should collaborate with the border router to receive your traffic from the Internet, and in addition should collaborate with your Kubernetes nodes (or whatever is your server backend) to distribute the traffic towards the destination application (Read more about cloud-native load balancer service for on-prem local cloud)
These network services are essential for a cloud-native environment. In the public cloud we take the existence of such services for granted.
This is great, because it allows cloud practitioners to focus on applications that are core and unique to their business!
On-demand, self-operating network infrastructure services are currently the state of the art for cloud environments. Your on-premises private cloud should be the same. Otherwise it’s not a private cloud it’s just a legacy on-prem.
What network gateway services are essential for private cloud?
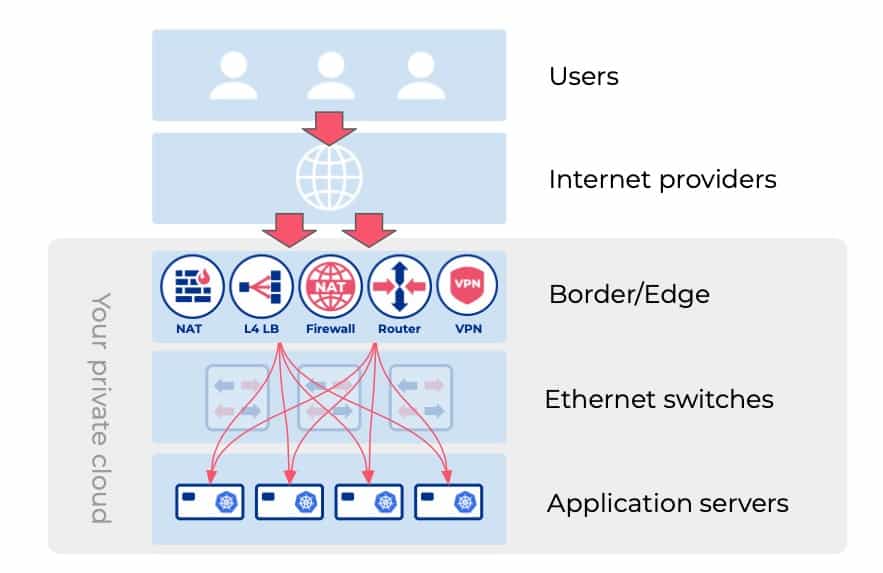
- Border router – Sits at the edge of your private network and handle BGP sessions with your Internet providers and Internet exchange points. Routes egress traffic towards the Internet using the best path available at any moment. Also makes your public IPv4/IPv6 address space accessible globally, and accepts the ingress traffic.
- NAT (Network Address Translation) – Allows hosts with private IP addresses to communicate with the Internet.
- L4 load balancer – Exposes applications to the Internet, and routes traffic into your Kubernetes ingress (or whatever your application stack is).
- Site-to-site VPN – Enables applications hosted on private IP address space to communicate with private IP address hosted applications located in another data center or remote office (transiting through encrypted tunnels over the Internet).
What are the minimal expectations for gateway/border services in a private cloud?
- Immediate on-the-fly service change and provisioning (self-operating / automatic cloud-like experience)
- DevOps friendly interfaces: Kubernetes CRDs, Terraform, RestAPI, intuitive GUI
- Native integration with Kubernetes (Automatically adjust the network by watching kube-api)
- Provide the essential network services (border routing, Layer-4 load balancing, NAT, site-to-site VPN)
- High Availability
- Horizontally scalability
- Run on commodity hardware
Where does your traditional networking gear fit?
Traditional networking gear, such as Cisco ASR series or Juniper MX series, are very fast and quite stable. They behave well unless you make an “oops” in your daily duty of writing imperative network configurations into the CLI of production devices.
Every year we witness a few remarkable network outages caused by a human error.
To err is human: Vendors should provide solutions that are easier to operate and are less prone to human error. (Public cloud has proved it’s possible)
Specialized routers can do a gazillion different routing functions (you likely need only a handful), but very commonly they can’t provide load balancing or NAT or other essential network services. So by design, when you use traditional networking hardware, you are forced to maintain dedicated devices for different network functions (one for router, another for load balancer, another for firewall, etc.), and don’t forget to multiply by two (for redundancy). More devices leads to even more network integrations to maintain, which eventually leads to even more increased complexity. This is the opposite of a cloud-like experience.
With a cloud-native mindset, you can’t risk your network every time your application team needs a new load balancer instance, or every time there’s a new Kubernetes node requiring a new BGP peer config between Calico and the physical network (to name a few).
These old-good traditional networking gear are great for static use cases, but are error prone in modern dynamic environments.
Raise your hand if you are now experiencing supply chain problems for your physical infrastructure!
In addition, you don’t want to mix and match brands and models, as everyone knows this is a sure-fire way to have to deal with incompatibility issues. Customers typically end up locked-in with the vendor & model of their selected devices. If you’ve been in the industry for more than 5 years you’ve likely dealt with supply chain issues when trying to buy additional equipment. So when doing your first cloud repatriation project, you might want to consider having addition options, and not just the one vendor you’re familiar with.
Why on earth would we lock ourselves to a single vendor, when modern commodity hardware, if managed right, unlocks cost and supply chain diversity benefits?
Can we use Linux machines and SmartNICs for border networking in the private cloud?
I’ve managed routers at many different scales in various applications, from forwarding Kbps on a little embedded Linux board to moving Tbps across multiple countries using Cisco & Juniper. I’ve always admired Linux, and even happened to build a wireless ISP network that used a highly distributed network of Linux server-routers covering a city the size of San Francisco.
One of the big reasons for my admiration of Linux routers is that it’s universal, you don’t need different hardware for different functionality. Your server can perform as a border router, load balancer, firewall, VPN gateway, everything and anything. You only need to have the right amount of resources. And it’s Linux, so you can install anything you need and you can easily script-create whatever is unique to your business needs.
But the limitation was always the performance. The flexibility of general purpose machines had the downside of limited performance for network forwarding applications.
It blows my mind how SmartNICs, DPDK, and FRR have changed that!
Border routers needs to speak BGP with many Internet providers (and IXPs) with the ability to handle a full routing table (900K+ routes). For decades, this task would require specialized hardware. FRR (Free Range Routing) has changed this. With FRR we are able to handle multiple dozens of peers sending a full routing table on a regular Linux server.
But can we forward 100Gbps+ with a Linux server?
Normally, every packet entering the Linux router generates a CPU interrupt and gets into the kernel for forwarding. Border routers need to forward millions of packets per second, generating millions of CPU interrupts per second which easily overwhelms the kernel and creates bottlenecks.
A SmartNIC is a network interface card with an ASIC (application specific integrated circuit). By leveraging DPDK (data plane development kit) it is possible to use this ASIC for accelerating network traffic processing.
Combining a SmartNIC and DPDK it is possible to offload some network functions into the ASIC, thereby bypassing the standard interrupts and kernel processing, and processing network traffic at the user level (using pre-allocated CPU cores).
So a ~$1,000 SmartNIC with the right software can turn a $5,000 server into a high performance gateway that can do border routing, load balancing, NAT, VPN, and more, forwarding 100Gbps+ of traffic & 20M+ packets per second.
This solution is comparable to the traditional (read: expensive $20K-200K) network device.
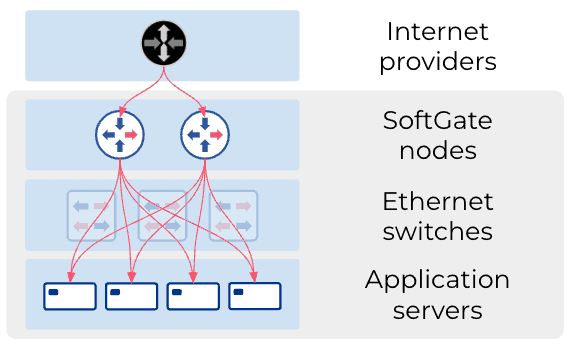
Another bonus: It runs on commodity hardware available from your favorite server vendors. We at Netris want to simplify networking and bring it closer to the Linux, DevOps, and NetOps communities. We have created Netris SoftGate‘ a software solution that helps to turn Linux servers into fully functional gateways.