
KubeCon + CloudNativeCon + Open Source Summit China Virtual sponsor guest post from Huawei
Introduction
Volcano is a cloud native batch computing platform and CNCFs ‘first container batch computing project. Major use cases are in the field of high-performance computing (HPC), such as big data, AI, gene computing, and rendering. Kubernetes has been backing workloads as micro services for a long time and falls short in batch computing scenarios. Therefore, Volcano is developed to extend cloud native from micro services to big data, artificial intelligence, and HPC by providing the following capabilities:
- Full lifecycle management for jobs
- Scheduling policies for high-performance workloads
- Support for heterogeneous hardware
- Performance optimization for high-performance workloads
Volcano was open-sourced in 2019. The community has more than 50 users who deploy Volcano in their production. Volcano is diving deeper in the preceding four directions to support more scenarios. This article describes the latest progress of Volcano in terms of job lifecycle management and scheduling policies for high-performance workloads.
Job Lifecycle Management
There are many distributed training frameworks developed for cloud native AI. Each framework has its own characteristics. As commonly seen, a user deploys multiple frameworks for different scenarios, which increases O&M complexity and costs.
To simplify O&M and centrally manage resources, Volcano provides a unified object for job management, Volcano Job. Volcano Job supports various upper-layer computing engines, such as TensorFlow, PyTorch, MXNet, MPI, Kubeflow, KubeGene, MindSpore and PaddlePaddle. Users do not need to install operators. They can use Volcano Jobs to run AI training jobs and enjoy enhanced lifecycle management. Together with the Volcano scheduling policies, a complete batch computing system is within easy reach.
Volcano Job provides the following capabilities:
- Multiple job templates. Roles such as ps/worker in TensorFlow and master/worker in MPI can be defined in Jobs. More configurations are supported.
- A complete event and action mechanism. For example, you can define the action to be taken for a Job when a task in the Job fails.
- Task indexes for data fragmentation
- Job plugins with user extensions
The built-in svc, ssh, and env plugins are provided for Volcano Jobs. These plugins automatically create headless Services for the interaction between the ps and worker, and automatically configure SSH for password-free login of the master and worker in MPI, which simplify how you run your workloads.
A recent proposal for AI job management in the community is to support Distributed Framework Plugins, which aims to further reduce the complexity of describing distributed training jobs based on Volcano Jobs.
The original semantics of Volcano Job can describe various training jobs, but in a bit complex way (TensorFlow use case). This proposal uses the Volcano Job plugin extension mechanism to support various AI jobs, including TensorFlow, PyTorch, MXNet, and MPI job plugins. Take TensorFlow as an example.
The key implementation of TensorFlow plugin is that how to set correct TF_CONFIG environment variable for each pod.
First, we must know the cluster role of task in Volcano Job, and the port to be exposed. And this information can be passed by plugin arguments, which is defined in job spec.

Second, the TensorFlow job plugin can implement the interfaces which are defined by Volcano to customize its behaviors. Here is the job plugin interface in Volcano.

Here is the implementation of OnPodCreate in TensorFlow plugin. We can see that TensorFlow plugin generate the TFConfig in this function and patch the pod spec.

Let’s see how to use Volcano Jobs to concisely describe TensorFlow jobs.
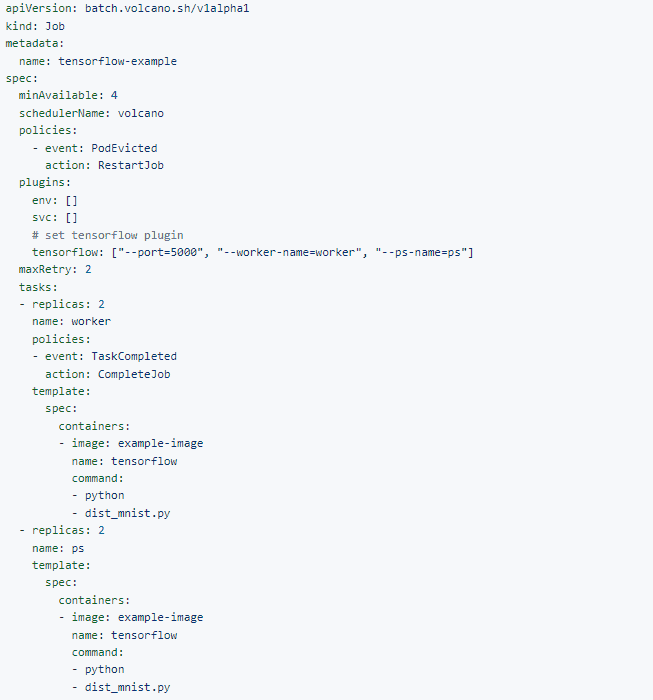
Scheduling Policies for High-performance Workloads
GPU is a costly, scarce resource for most training jobs, especially for a large-scale GPU cluster. How to fully use GPUs is a common concern. AI distributed elastic training is one of the important means to improve GPU utilization. The elastic training system scales in or out the number of training instances based on the computing capability to keep the GPU utilization close to the desired level.
Volcano is optimized for elastic training. It scales out training instances based on the [min, max] configuration of Jobs to shorten the training time and improve resource utilization. Here is a use case of elastic training.
For example, a K8s cluster has 10 GPUs, and user wants to use Volcano to schedule training jobs (tfjob/pytorchjob/vcjob) in two queues: queue1 and queue2.
| Weight | Deserved GPU | |
| Queue1 | 1 | 5 |
| Queue2 | 1 | 5 |
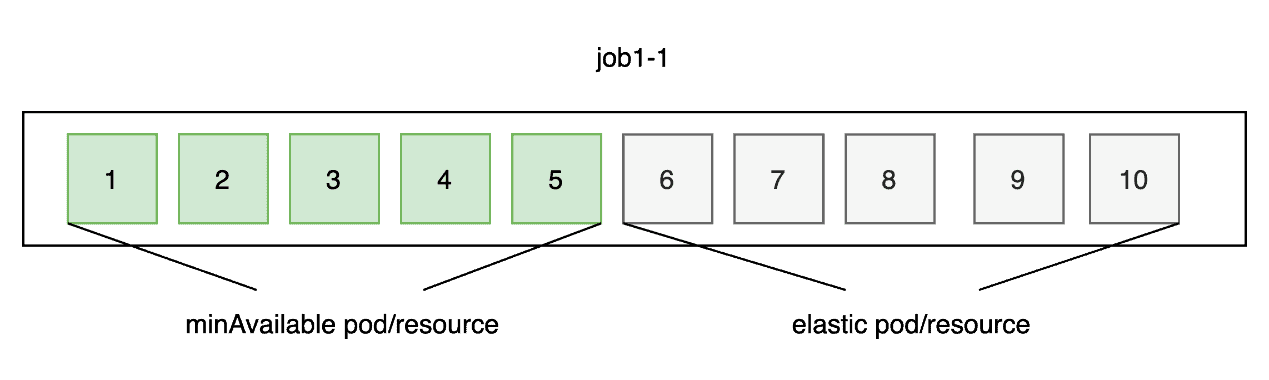
If there is a job1-1 running in queue1, we set pod6 to pod10 as elastic pods/resources which can be preempted when queue1’s resource is insufficient. The elastic pods have the lowest priority. Specifically, these pods will be created last and be preempted first.
- Elastic pods can be scheduled only when there are free resources.
- Elastic pods will be preempted if there are not enough resources for running minAvailable pods.
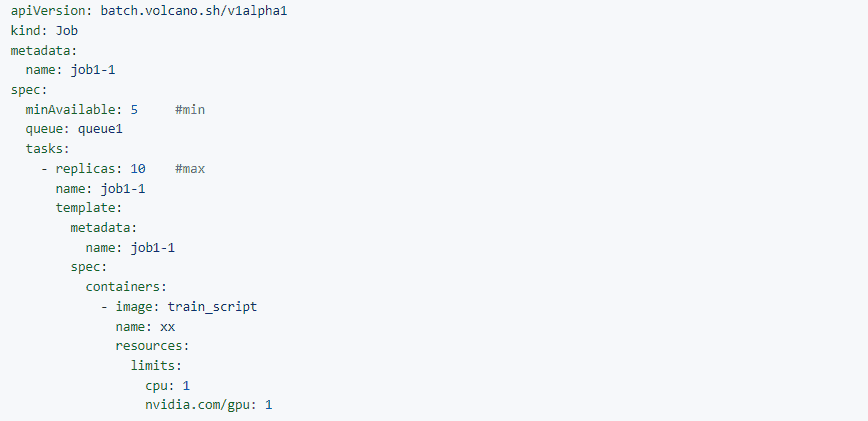
Here are some detail use cases:
Use case 1: If job1-1 and job1-2 are submitted at the same time, job1.minAvailable pods and job2.minAvailable pods will be created first, and then job1/job2.elastic pods will be created if there are extra resource.

Use case 2: If you submit job1-1 and then submit job1-2 in queue1, elastic pods in job1-1 will be preempted.

Use case 3: If you submit job1-1 and then submit job2-1 in queue2, elastic pods in job1-1 will be preempted.
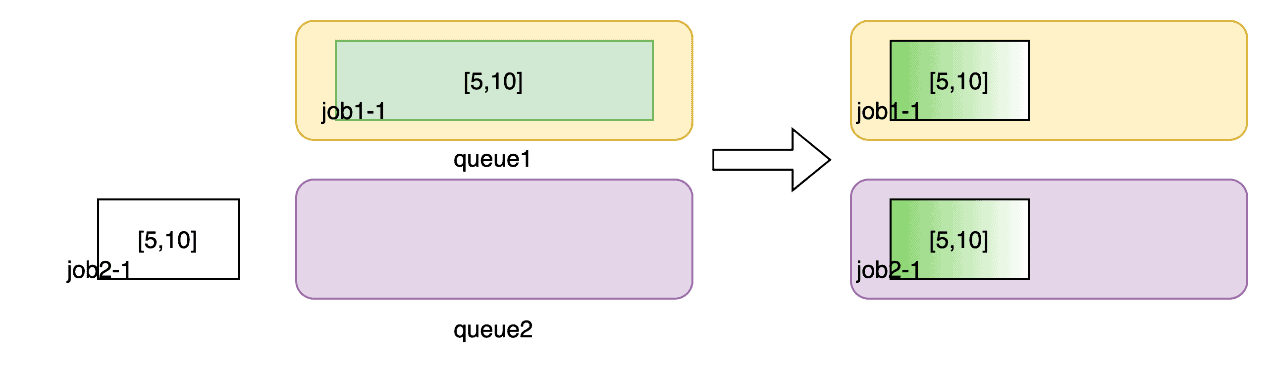
Here are some key points about elastic training.
- Set different priority for minAvailable pods and elastic pods.
- The elastic pods get scheduled last and get preempted first.
- The elastic pods should be preempted while there is starving job whose minAvailable is not satisfied.
- Elastic Pods should be preempted to make sure the queue fair-share based weight.
To sum up, Volcano uses the job plugin extension mechanism to manage TensorFlow, MXNet, MPI, and PyTorch jobs using machine learning plugins, which simplifies O&M. As for scheduling policies, capabilities such as Job min/max, preemption, relaim, queue fair-share are used to support PyTorch elastic training, improving the GPU utilization and shortening the training duration.
There are also research and development projects under Volcano in terms of heterogeneous hardware support and high-performance workload optimization, such as GPU virtualization, high-throughput scheduling optimization, and Job Flow. We will introduce them in the coming articles.
Leibo Wang is a maintainer and Tech-Lead of CNCF Volcano community, and also an architect at Huawei with 15 years of experience on resource management and batch scheduling.
Qiankun Li is a sensor engineer at Ximalaya Company. He is a contributor to the Volcano community and is focusing on machine learning platform development.
Reference:
https://github.com/volcano-sh/volcano/blob/master/docs/design/distributed-framework-plugins.md
https://github.com/volcano-sh/volcano/blob/master/docs/design/distributed-framework-plugins.md