

Guest post originally published on PingCAP‘s blog by Shuyang Wu

Apache APISIX is a cloud-native, high-performance, scaling microservices API gateway. It is one of the Apache Software Foundation’s top-level projects and serves hundreds of companies around the world, processing their mission-critical traffic, including finance, the Internet, manufacturing, retail, and operators. Our customers include NASA, the European Union’s digital factory, China Mobile, and Tencent.
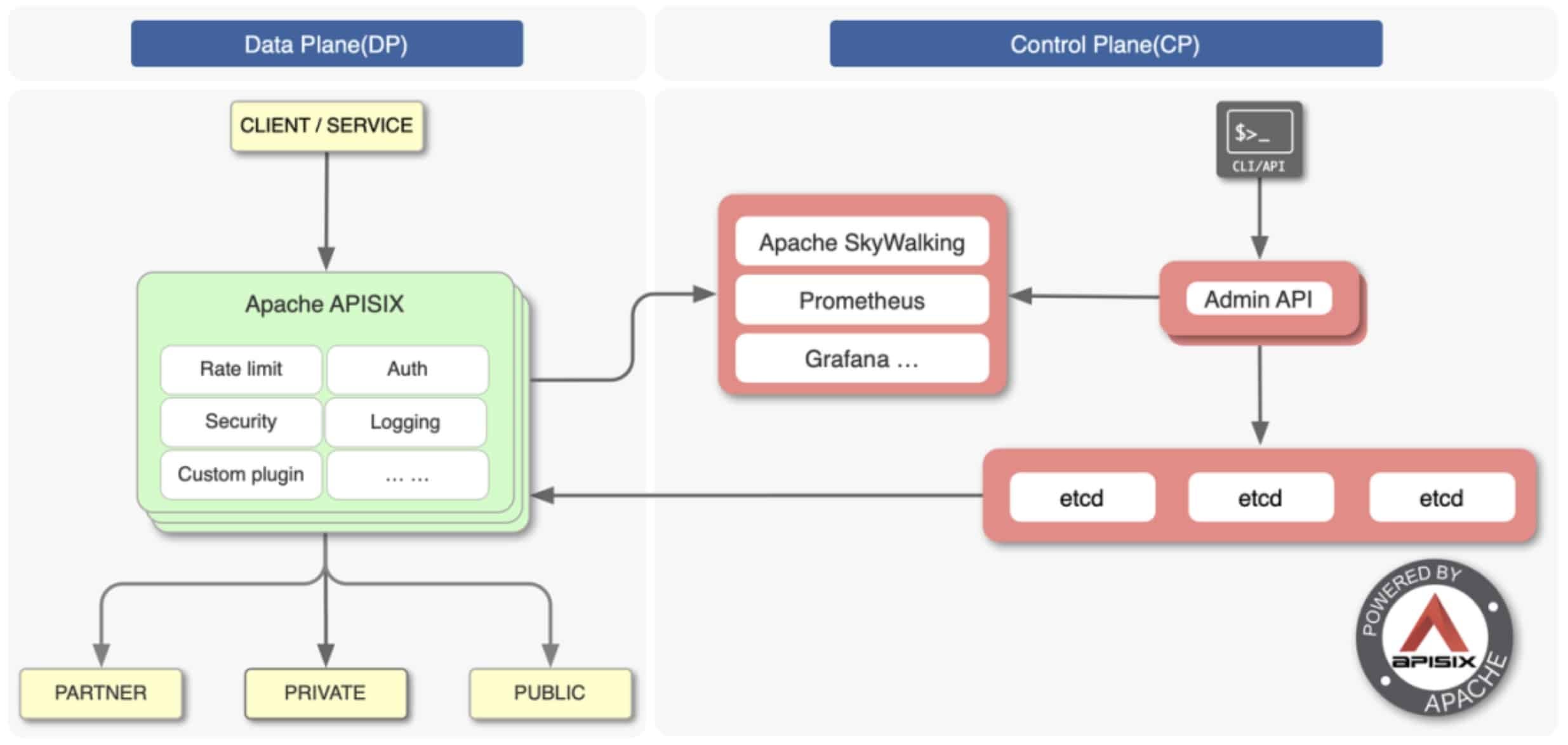
As our community grows, Apache APISIX’s features more frequently interact with external components, making our system more complex and increasing the possibility of errors. To identify potential system failures and build confidence in the production environment, we introduced the concept of Chaos Engineering.
In this post, we’ll share how we use Chaos Mesh® to improve our system stability.
Our pain points
Apache APISIX processes tens of billions of requests a day. At that volume level, our users have noticed a couple of issues:
- Scenario #1: In Apache APISIX’s configuration center, when unexpectedly high network latency occurs between etcd and Apache APISIX, can Apache APISIX still filter and forward traffic normally?
- Scenario #2: When a node in the etcd cluster fails and the cluster can still run normally, an error is reported for the node’s interaction with the Apache APISIX admin API.
Although Apache APISIX has covered many scenarios through unit, end-to-end (E2E), and fuzz tests in continuous integration (CI), it has not covered the interaction scenario with external components. If the system behaves abnormally, for example, if the network jitters, a hard disk fails, or a process is killed, can Apache APISIX give appropriate error messages? Can it keep running or restore itself to normal operation?
Why we chose Chaos Mesh
To test these user scenarios and to discover similar problems before our product goes into production, our community decided to use Chaos Mesh for chaos testing.
Chaos Mesh is a cloud-native Chaos Engineering platform that features all-around fault injection methods for complex systems on Kubernetes, covering faults in Pod, the network, file system, and even the kernel. It helps users find weaknesses in the system and ensures that the system can resist out-of-control situations in the production environment.
Like Apache APISIX, Chaos Mesh has an active open source community. We know that an active community can ensure stable software use and rapid iteration. This makes Chaos Mesh more attractive.
How we use Chaos Mesh in APISIX
Chaos Engineering has grown beyond simple fault injection and now forms a complete methodology. To create a chaos experiment, we determined what the normal operation or “steady state” of our application should be. We then introduced potential problems to see how the system responded. If the problems knocked the application out of its steady state, we fixed them.
Now, we’ll take the two scenarios we mentioned to show you how we use Chaos Mesh in Apache APISIX.
Scenario #1
We deployed a Chaos Engineering experiment using the following steps:
- We found metrics to measure whether Apache APISIX is running normally. In the test, the most important method is to use Grafana to monitor the Apache APISIX’s running metrics. We extracted data from Prometheus in CI for comparison. Here, we used the routing and forwarding requests per second (RPS) and etcd connectivity as evaluation metrics. We analyzed the log. For Apache APISIX, we checked Nginx’s error log to determine whether there was an error and whether the error was in line with our expectations.
- We performed a test in the control group. We found that both
create routeandaccess routewere successful, and we could connect to etcd. We recorded the RPS. - We used network chaos to add a five second network latency and then retested. This time,
set routefailed,get routesucceeded, etcd could be connected to, and RPS had no significant change compared to the previous experiment. The experiment met our expectations.
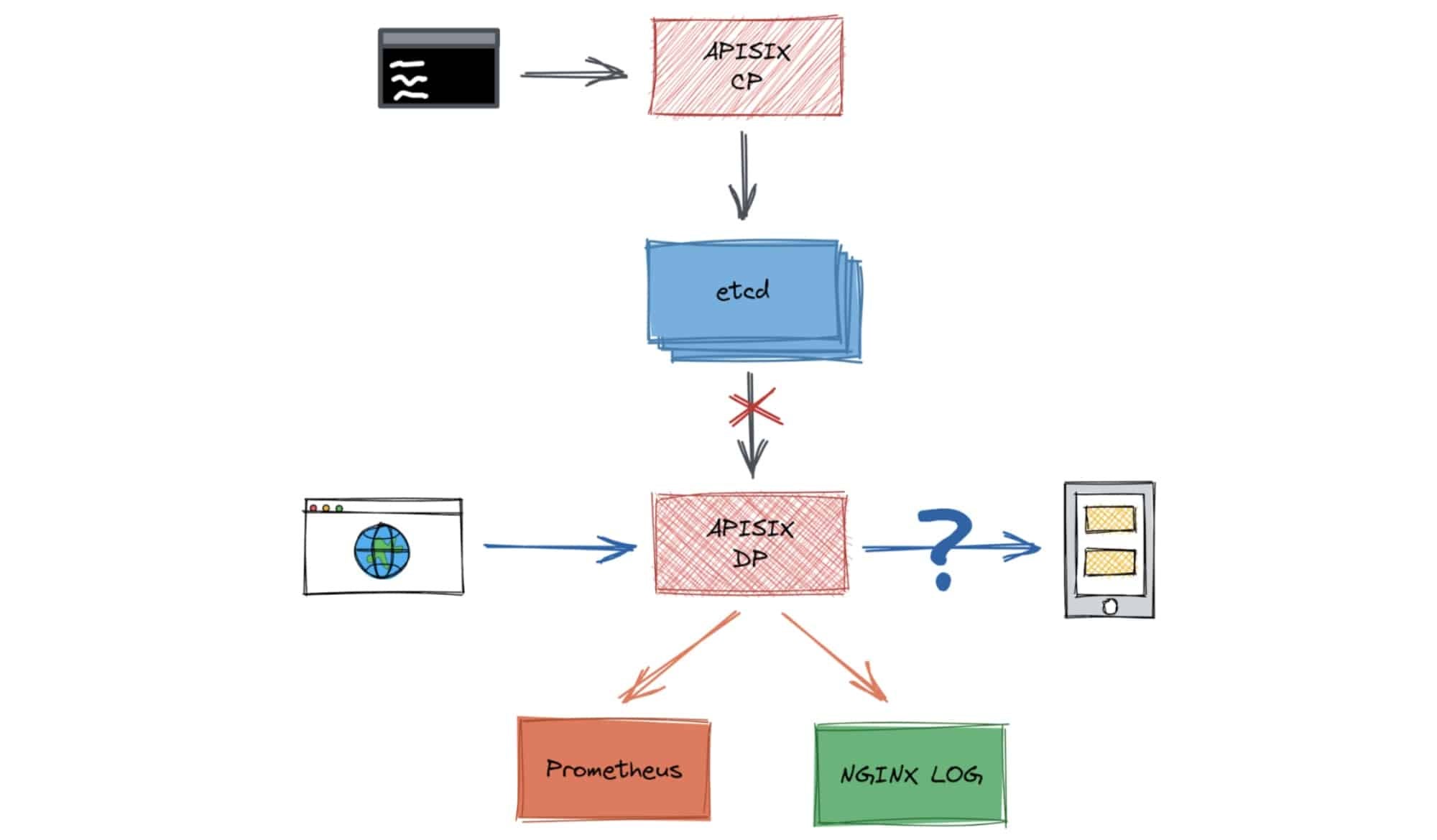
High network latency occurs between etcd and Apache APISIX
Scenario #2
After we conducted the same experiment as above in the control group, we introduced pod-kill chaos and reproduced the expected error. When we randomly deleted a small number of etcd nodes in the cluster, sometimes APISIX could connect to etcd and sometimes not, and the log printed a large number of connection rejection errors.
When we deleted the first or third node in the etcd endpoint list, the set route returned a result normally. However, when we deleted the second node in the list, the set route returned the error “connection refused.”
Our troubleshooting revealed that the etcd Lua API used by Apache APISIX selected the endpoint sequentially, not randomly. Therefore, when we created an etcd client, we bound to only one etcd endpoint. This led to continuous failure.
After we fixed this problem, we added a health check to the etcd Lua API to ensure that a large number of requests would not be sent to the disconnected etcd node. To avoid flooding the log with errors, we added a fallback mechanism when the etcd cluster was completely disconnected.
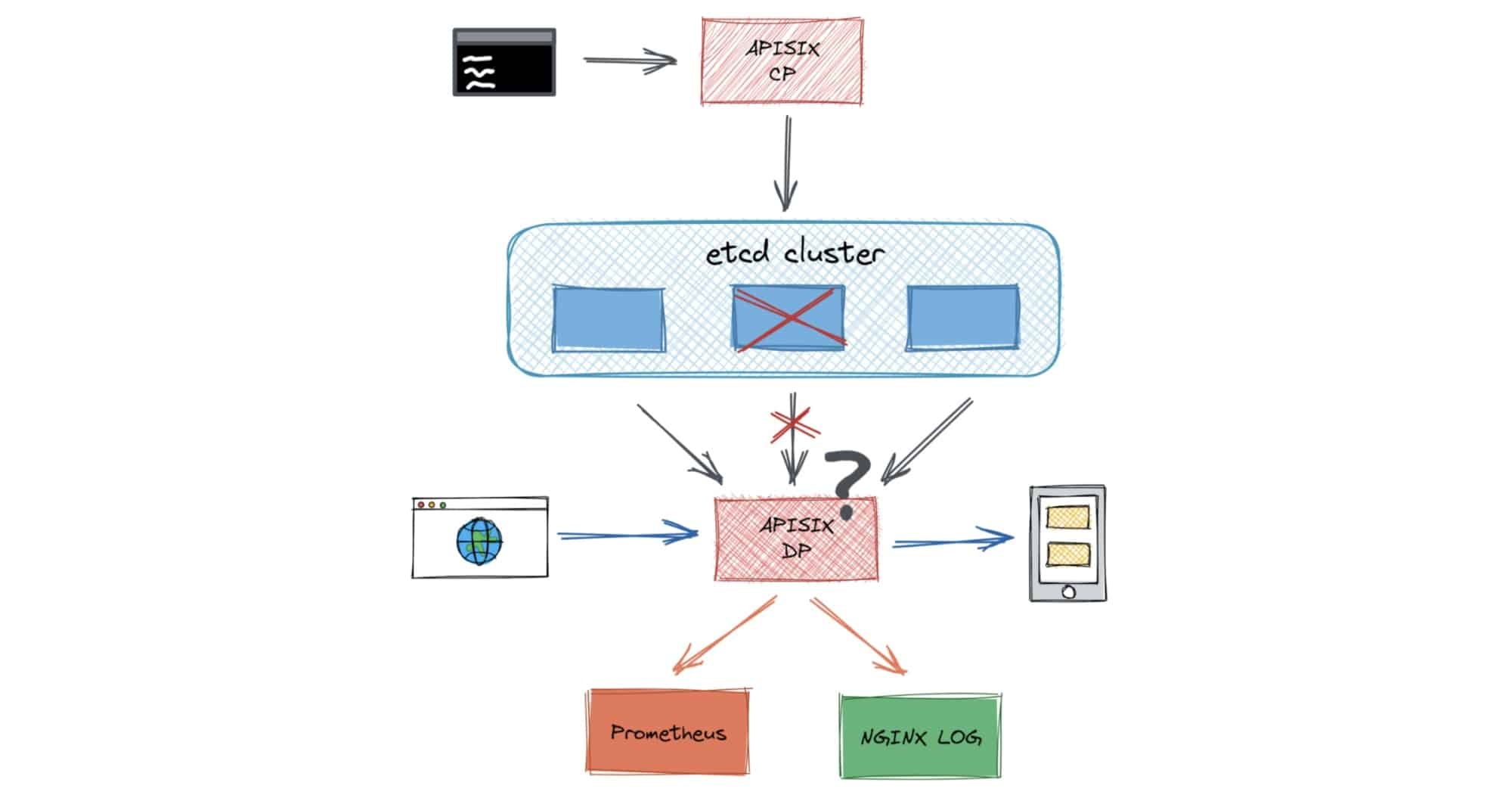
An error is reported from one etcd node’s interaction with the Apache APISIX admin API
Our future plans
Run a chaos test in E2E simulation scenarios
In Apache APISIX, we manually identify system weaknesses for testing and repair. As in the open source community, we test in CI, so we don’t need to worry about the impact of Chaos Engineering’s failure radius on the production environment. But the test cannot cover complicated and comprehensive application scenarios in the production environment.
To cover more scenarios, the community plans to use the existing E2E test to simulate more complete scenarios and conduct chaos tests that are more random and cover a larger range.
Add chaos tests to more Apache APISIX projects
In addition to finding more vulnerabilities for Apache APISIX, the community plans to add chaos tests to more projects such as Apache APISIX Dashboard and Apache APISIX Ingress Controller.
Add features to Chaos Mesh
When we deployed Chaos Mesh, some features were temporarily unsupported. For example, we couldn’t select a service as a network latency target or specify container port injection as network chaos. In the future, the Apache APISIX community will assist Chaos Mesh to add related features.
You’re welcome to contribute to the Apache APISIX project on GitHub. If you are interested in Chaos Mesh and would like to improve it, join its Slack channel (#project-chaos-mesh) or submit your pull requests or issues to its GitHub repository. Chaos Engineering