

Guest post originally published on Elastisys’ blog by Cristian Klein, Sr Cloud Architect at Elastisys
Several court rulings and a guideline from the European Data Protection Board (EDPB) made it clear: It is a huge legal risk to process EU personal data on US-owned clouds. Therefore, many Kubernetes operators are scrambling to port their environments to an EU cloud provider or their on-prem data centers. Unfortunately, such environments often lack the notion of “availability zone”, which makes cross-data-center redundancy difficult. In this post, we will show you how we dealt with this requirement using Kubernetes, Rook / Ceph, Calico and WireGuard.
Regions vs. availability zones
US-owned cloud providers call their data centers “availability zones” and group them into regions. Data centers in a region are physically far enough from each other so they are unlikely to be impacted by the same Internet or power outage, or extreme weather event. However, they are close enough so that latency is low and bandwidth is plenty, and can be exposed as a single unit.
Indeed, from a usage perspective, a region “feels” like a single data center. For example, operators can enjoy a single private network stretched across several zones. Similarly, a single regional load-balancer can point to Virtual Machines across several zones. Some US-owned cloud providers even provide regional disks.
Hence, stretching your workload across two zones in the same region greatly increases resilience to outages, without extra effort from your side.
Do I always have availability zones?
Unfortunately, most EU cloud providers and on-prem data centers lack the notion of availability zones and only group their data centers into regions. This means that, although they might have data centers in close physical proximity with low latency and plenty of bandwidth, they do not “feel” like a single data center. Specifically, they lack a stretched private network, disks replicated across data centers and a way to fail-over ingress traffic across data centers.
If your resilience requirements require stretching your workload across multiple data centers, you will have to put in a lot of extra effort.
Cloud native to the rescue!
Cloud Native projects, such as Kubernetes, allow building an application platform that meets your resilience requirements. Let’s describe the platform we built by going step-by-step through the architecture diagram below.
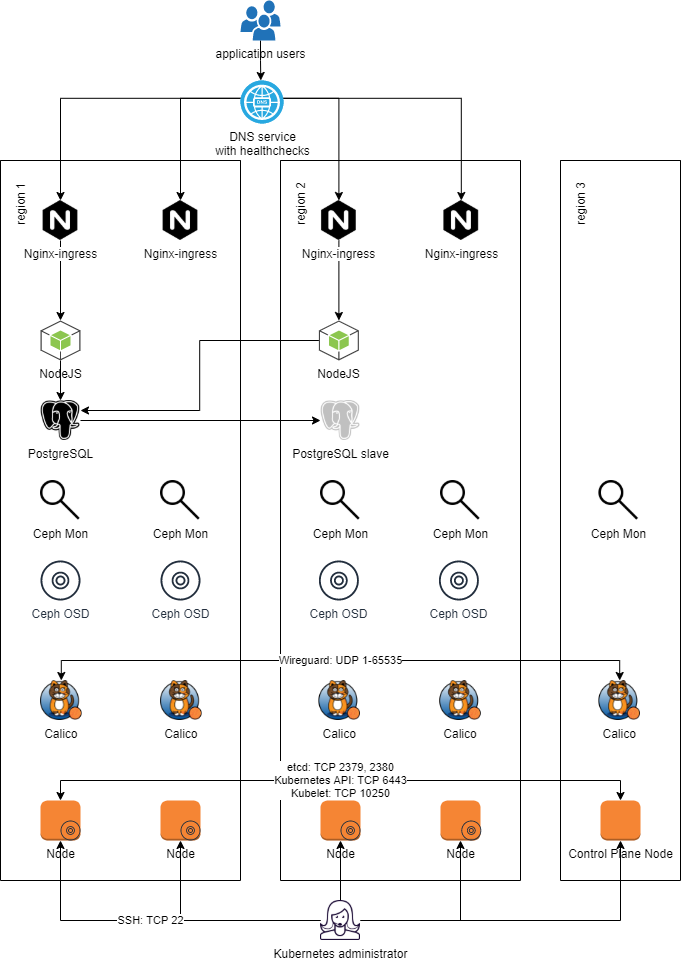
Choosing regions
First, you need to choose three regions. Region 1 and 2 run workloads and store data, hence need more capacity. Region 3 is only acting as an “arbiter” to avoid “split brain” and needs very little capacity. Split brain could happen when region 1 thinks region 2 is down, but region 2 thinks region 1 is down, and each considers itself responsible for performing write operations. Writes happening in two parts of the system without proper synchronization may lead to huge data loss. The arbiter is there to sanction the “right” region and ensure only one is in charge of writes.
Creating infrastructure
Next step involves creating the infrastructure. Provision sufficient Virtual Machines (VMs) for complete separation of control plane Nodes from workload Nodes. You may even want to have separate storage Nodes, which run no application containers and only host Ceph instances.
Most infrastructure providers will come with a firewall configured via SecurityGroups. Make sure to open the right ports both for administrator access, as well as to allow Kubernetes and application components to communicate, as shown in the architectural diagram. Since SecurityGroups are not shared among regions — remember, these are essentially 3 different clouds — you will have to use IP allowlisting. Try to be as restrictive as possible, i.e., don’t open the Kubelet TCP port to the whole world.
Creating a stretched Kubernetes cluster
Next step involves spraying the Kubernetes cluster on top of the created infrastructure. We are big fans of Kubespray, to the point that we contribute to it. Kubespray will allow you to properly separate control plane and data plane Nodes, by adding the right taints. Properly labeling your Nodes with topology labels will allow applications to use PodTopologySpreadConstraints to spread its replicas across data centers and achieve the cross-data-center resilience you need.
Another issue to bear in mind is that intra-cluster traffic might travel through untrusted networks. Most data security regulations require you to encrypt all such traffic. Fortunately, Kubespray has recently added support for configuring Calico with WireGuard. Without going into details, WireGuard is like a Node-to-Node VPN. Think IPsec on steroids! Same security guarantees, zero hassle.
Creating a stretched Rook cluster
Since you are creating a stretched Kubernetes cluster, you cannot use Container Storage Interface (CSI) to integrate with the storage — i.e., dynamically attached virtual disks — provided by the three regions. The virtual disks would not be synchronized between regions, which implies that losing a region would make you lose all data stored on the PersistentVolumes hosted on that region — far from what we want to achieve here.
Fortunately, the Rook CNCF project can be used to create a Kubernetes-native storage cluster using the disks attached to the VMs. Under the hood, Rook uses a battle-tested storage solution called Ceph which handles data mapping and replication. In fact, you can easily create a stretched storage cluster. Rook understands the topology labels of your Kubernetes Nodes and configures the so-called Ceph CRUSH map to ensure data is replicated across data centers.
Using the right tolerations, you can ensure that a Ceph Mon is running in the arbiter region, so as to maintain Ceph Mon quorum even when one data-center is down. Without Mon quorum, Ceph OSDs — the component that actually stores data — will not be allowed to perform writes, so as to avoid split brain and huge data loss.
Getting traffic into the cluster
Your last challenge will be getting traffic into the cluster, specifically routing it only towards the healthy regions. Fortunately, DNS services with health checks are plenty. Such DNS services serve a dynamic DNS record pointing to only those IP addresses that pass a health check. If you are using an Ingress controller — as most (all?) Kubernetes clusters do — simply point the health check to the Ingress controller’s healthz endpoint. Combined with a low DNS TTL, your application users — whether their browser on an app — will be directed to the healthy regions.
You are free to choose a DNS service from either a US- or EU-owned entity. The DNS service will only see the IP address of the resolving DNS server and the domain being resolved. Hence, no personal data — not even the IP address of the application user, which were ruled personal data — will be processed by the DNS service.
If you want to be extra kind to your Kubernetes developers — you want them to send you hugops, don’t you? — consider sending them a DNS record instead of an IP address for accessing the Kubernetes API. This allows you to use the same DNS service with health checks to hide the failure of your region from your developers.
That sounds easy! Am I done?
As the Swedes would say: “nja” (yes and no). Do you have twice the required capacity in your cluster? Have you properly configured all applications with the right PodTopologySpreadConstraints? Are all your Deployments and StatefulSets configured with sufficient replication? Is fail-over happening fast enough?
Answering all these questions is not a simple checklist exercise, rather resilience to failure should regularly be tested. This ensures that you don’t get bitten by unexpected failure modes when the failure happens, rather you proactively identify gaps and bridge them as required.
For example, we had an application using a StatefulSet with replication 1, which was deemed sufficient, since the application could tolerate a few minutes of downtime during a fail-over. When we induced failure of the region hosting the StatefulSet’s only Pod, we were surprised to find that Kubernetes was not rescheduling it to the healthy region, as we needed to manually delete the Pod. In effect, we bumped into a Kubernetes feature designed to treat StatefulSets delicately as intended. Fortunately, we found this out during failure testing, so the solution was to simply set replication 2.
This point is so important, that I’m going to write it again: Resilience to failure must be regularly tested.