
Project guest post originally published on the Vitess Blog by Vicent Marti
Although the main interface between applications and a Vitess database is through the MySQL protocol, Vitess is a large and complex distributed system, and all the communication between the different services in a Vitess cluster is performed through GRPC.
Because of this, all service boundaries and messages between Vitess’ systems are specified using Protocol Buffers. The history of Vitess’ integration with Protocol Buffers is rather involved: We have been using and keeping up to date with the Go Protocol Buffers package since its earliest releases, up until May last year, when Google released a new Go API for Protocol Buffers, which is not backwards compatible with the previous Go package.
There are several reasons why we didn’t jump at the chance of upgrading to the new API right away: the upgrade is non-trivial, particularly for a project as large as Vitess; it does not provide any tangible benefits to us, since our use of Protocol Buffers is quite basic, and we don’t use reflection anywhere in our codebase; and most importantly: it implies a very significant performance regression.
Although the new (un)marshaling code in ProtoBuf APIv2 is not measurably slower than the one in APIv1 (it is, in fact, mostly equivalent), Vitess hasn’t been using the APIv1 codecs for a while. Earlier this year, we introduced the Gogo ProtoBuf compiler to our codebase, with really impressive performance results.
For those who are not aware of it, Gogo ProtoBuf is a fork of the original ProtoBuf APIv1 that includes a custom code generator with optional support for many performance related features. The most notable of them, and the one we enabled for Vitess, is the generation of fully unrolled marshaling and unmarshaling code for all the messages in the codebase. This is a very significant performance boost compared to marshaling using the default codecs in ProtoBuf APIv1, which are fully implemented using reflection at runtime. Having static code that can be compiled ahead of time results in much lower CPU usage and measurably shorter response times for our most demanding RPC calls.
Despite the positive results of introducing the Gogo ProtoBuf compiler to our codebase, there was something rather concerning about the optimization: the Gogo project is currently unmaintained and actively looking for new ownership. The main reason for this is the release of the ProtoBuf APIv2: Gogo ProtoBuf is a fork of the APIv1 compiler, so updating it to support APIv2 would essentially mean a full rewrite of the project, just like APIv2 is a full rewrite of APIv1. The maintainers of Gogo, understandably, were not up to the gigantic task.
Hence, it was clear to us that introducing Gogo ProtoBuf generated code in Vitess would be a very short-lived optimization: as soon as we decided to upgrade our project to ProtoBuf APIv2, we’d have to drop Gogo altogether and go back to the default reflection-based (un)marshaler, but we still took the plunge, making sure to use as few Gogo-exclusive features as possible to make the eventual upgrade less painful.
Was this a bad idea? Maybe. Earlier this month we decided to attempt upgrading Vitess to ProtoBuf APIv2, mostly to find out how hard would the process be, and how large the performance regression when removing Gogo’s autogenerated code. The upgrade didn’t go without its hiccups, but we managed to get Vitess working with the new API and the test suite fully green after a couple of weeks of effort.
The results of our benchmarks, however, were discouraging. AreWeFastYet, our nightly benchmark system, detected a very significant increase in CPU usage during all benchmarking runs: up to 19%, resulting in lowering the total throughput of of the system by roughly 3%.
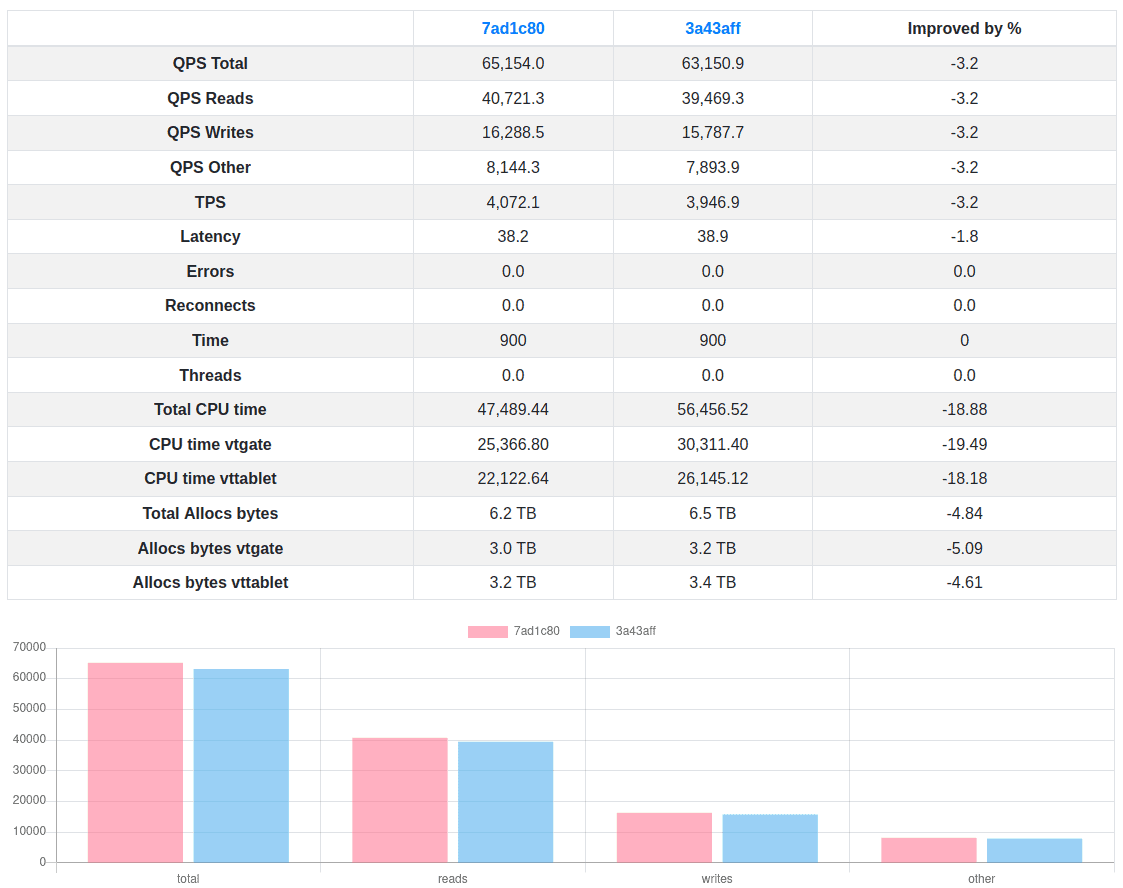
We try really hard to never regress performance between Vitess releases, so we started evaluating our options to perform this upgrade and leaving behind the ProtoBuf APIv1 package (now deprecated) and the Gogo ProtoBuf compiler (now unmaintained) while keeping Vitess as fast as it was.
Introducing vtprotobuf, the Vitess ProtoBuf compiler #
The most obvious choice that occured to us was picking up ownership of Gogo ProtoBuf, but its maintainers were right: upgrading it to APIv2 is a massive undertaking. We don’t have the staffing capacity to commit to upgrading and owning such project indefinitely.
So instead, we’ve attempted to build a ProtoBuf compiler that fulfills our performance needs while learning from the lessons of Gogo ProtoBuf: vtprotobuf is a ProtoBuf compiler for Go that generates highly optimized (un)marshaling code for APIv2, whilst being (hopefully) easier to maintain in the long term.
The vtprotobuf compiler makes a different design choice compared to Gogo ProtoBuf: it is not a fork of the APIv2 compiler, but an independent plug-in that runs alongside the upstream compiler for APIv2 and generates the optimized code as opt-in helpers. This is a trade-off because it means that we cannot implement some of the optimizations that Gogo supports, like making message fields non-nullable, or aliasing the generated types in the generated ProtoBuf messages. These are Gogo ProtoBuf features that some Go projects have used successfuly to reduce the amount of garbage generated when handling Protocol Buffer messages, but Vitess has never opted-in into those, so it didn’t make sense for us to port them to our APIv2 generator.
Instead, by focusing solely on highly optimized marshaling and unmarshaling code, vtprotobuf can be implemented in a tiny codebase that depends only on the public and stable google.golang.org/protobuf/compiler/protogen package from APIv2, while the original APIv2 code generator runs alongside it and generates the actual ProtoBuf messages and associated metadata for reflection.
We believe this is a solid trade-off that will make vtprotobuf very easy to maintain in the long run and that ensures that we’re always playing nice with any changes performed upstream, since we no longer carry our own fork.
The first beta version of vtprotobuf is now publicly available : it supports optimized code generation for marshaling, unmarshaling and sizing. The resulting codegen is based on the original implementation in Gogo ProtoBuf, but it is fully adapted to ProtoBuf APIv2 messages and has received numerous micro-optimizations that make it run as fast or faster in all our benchmarks. Furthermore, we’ve also implemented a new feature which is not available in the original Gogo ProtoBuf compiler: memory pooling.
Memory pooling in vtprotobuf #
There are two main reasons for the overall poor performance of Protocol Buffers in Go: the reliance on reflection for marshaling and unmarshaling, and the overhead of memory allocation.
The first issue with reflection is handled by vtprotobuf by generating optimized code to perform serialization and deserialization for each specific message. The second issue is much harder to fix.
Other ProtoBuf implementations, like C++, work around the memory allocation issues by using memory arenas: large memory blocks that can be used to allocate memory with a bump-pointer allocator (extremely efficient) and that can be freed all at once. This is a pattern that works beautifully in the typical request-response RPC system where Protocol Buffers are commonly used. Arenas are, however, unfeasible to implement in Go because it is a garbage collected language.
The Gogo ProtoBuf compiler works around the issue by allowing users to opt-in into fewer pointer fields in their generated message structs, something which reduces the overall number of allocations at the expense of ergonomics (it’s hard to tell whether nested messages are missing or not) and backwards incompatibility with upstream ProtoBuf generated messages. As explained earlier, we’ve opted not to modify the generated message structs at all, as to not carry a whole fork of the ProtoBuf Go generator, so this is not an option for us.
Hence, the next best option are memory pools for individual objects, and this is the functionality that vtprotobuf now provides. When enabling the pool feature in protoc-gen-go-vtproto, we can mark individual ProtoBuf messages so they’re always allocated off a memory pool when being unmarshaled. The marked messages receive a helper method so they can be directly returned to the memory pool when they’re no longer needed, and a specialized Reset implementation that zeros them out whilst making sure to keep as much underlying memory around as possible (e.g. in nested slices, maps and objects) so that retrieving those objects from the memory pool later on results in fewer allocations when unmarshaling.
Memory pooling is far from a performance silver bullet: many ProtoBuf messages are too small to benefit from pooling at all, and some have so much nested complexity that the overhead of recursively pooling its fields defeats the optimization in the first place. Furthermore, the Go programming language provides no capabilities in its type system to safely manage these pooled objects. If not used very carefully, it’s very easy to corrupt memory and cause data races with pooled ProtoBuf messages.
Despite its limitations, we have found that memory pooling is an extremely effective optimization in Vitess. When used well in APIs where it makes sense, it becomes significantly faster than the custom Gogo ProtoBuf messages without pointer fields, with average unmarshaling times for large messages being competitive with C++ arena-based unmarshaling. Let’s see a practical example now!
Case study: VReplication Row Streaming #
Vitess’ replication engine, VReplication, is one of the most RPC-heavy paths in a Vitess cluster. It is a powerful and versatile MySQL replication engine, capable of keeping copies of tables in sync between distinct Vitess keyspaces and materializing partial views of tables. Whenever we commit changes or optimizations that affect GRPC or ProtoBuf marshaling, we pay very close attention to their impact on the replication subsystem. Since the whole replication process is performed through GRPC, and in production deployments the replicated tables are often massive (terabytes), any performance regressions in this path often result in real world time increases that range between minutes and hours.
To measure the impact of ProtoBuf changes in our replication process, we’ve built a synthetic stress test that performs a full replication of a large MySQL table between two Vitess keyspaces. This is a realistic example that exercises the most expensive part of the replication process: the initial copy of all row data between the two Vitess tablets.
As a baseline for our performance measurements, we’re going to perform the replication using an old Vitess commit, where we were still using ProtoBuf APIv1 but without any of the Gogo ProtoBuf optimizations.
The flame graph in the destination tablet of the Vitess cluster clearly shows the source of RPC overhead:
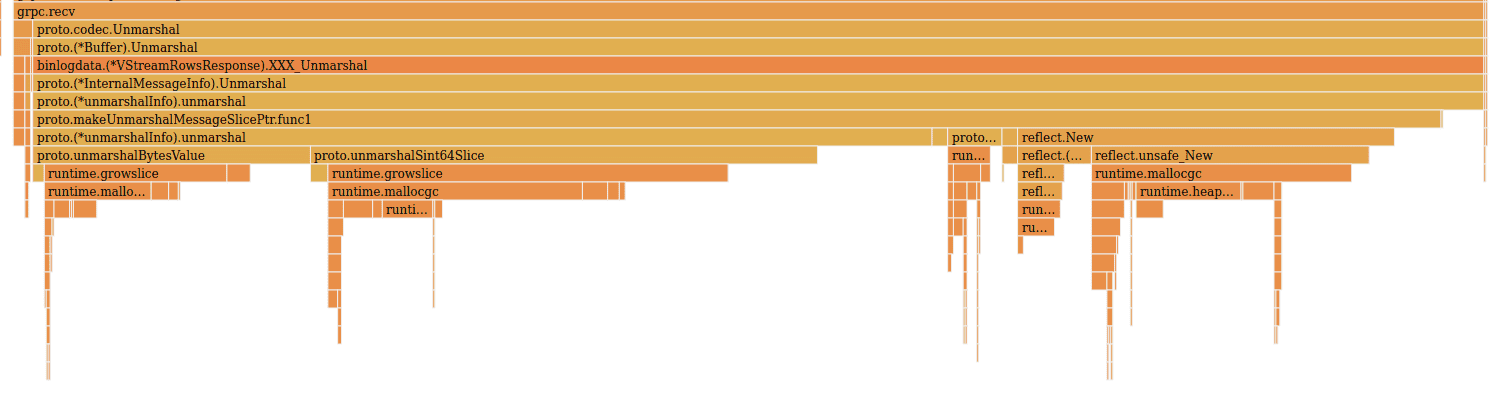
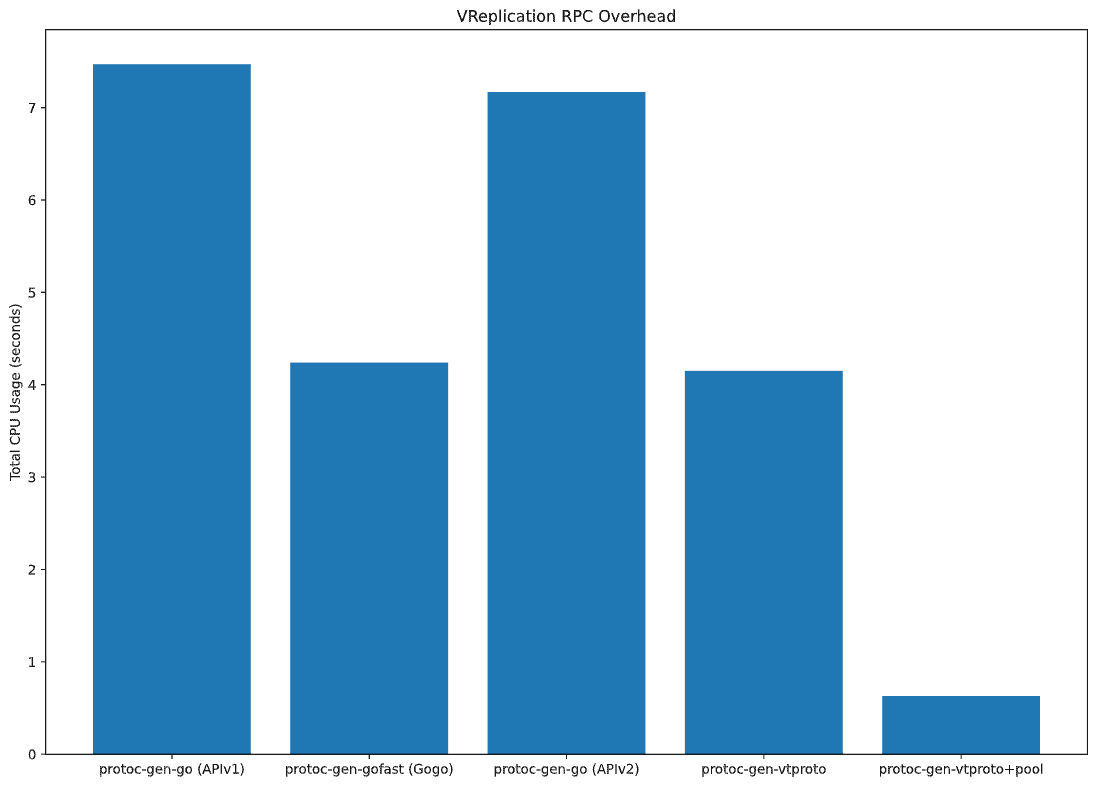
The reflection-based unmarshal code is not particularly efficient, but the vast majority of time is actually spent allocating memory for the contents of the individual rows being streamed. We spend a total of 7.47 CPU seconds in unmarshaling overhead through the whole benchmark.
Let’s compare this to the same replication process with ProtoBuf APIv1, but using the Gogo ProtoBuf generated unmarshaling code. Since we’re only interested in the faster (un)marshal code, we don’t need to modify our .proto files to enable the optimizations. We can simply replace the default protoc-gen-go generator with protoc-gen-gofast, provided by the Gogo project:
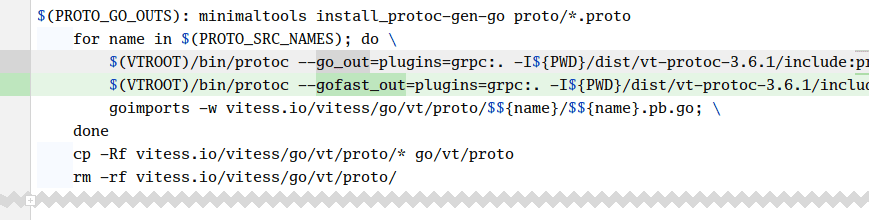
No further changes are need to enjoy the benefits of the optimization. Let’s see its impact on unmarshal overhead by running the benchmark again:
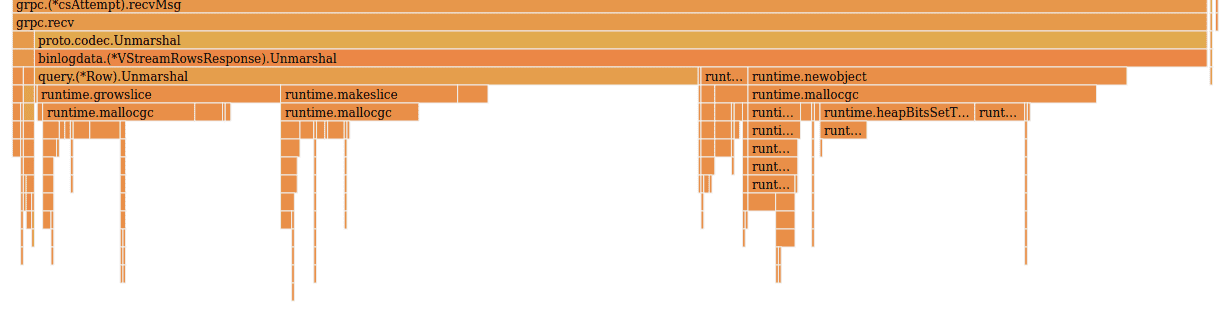
With all the reflection-based code replaced with optimized, pre-generated unmarshaling code, we can see that the overhead of actually parsing the ProtoBuf messages has been greatly reduced. We’re no longer calling into the proto package, and instead we’re using the specialized Marshal method in the VStreamRowsResponse struct to perform the unmarshaling. Most of the CPU time is now spent in allocating memory for the row data. In total, we’re now spending 4.24 CPU seconds in unmarshal overhead.
Let’s now see what performance looks like once we’ve upgraded Vitess to ProtoBuf APIv2. We’re going to need to remove the protoc-gen-gofast generator from Gogo ProtoBuf and replace it with the new APIv2 Generator. Also note that now the GRPC generator runs on its own, instead of being a plug-in passed to the default generator.
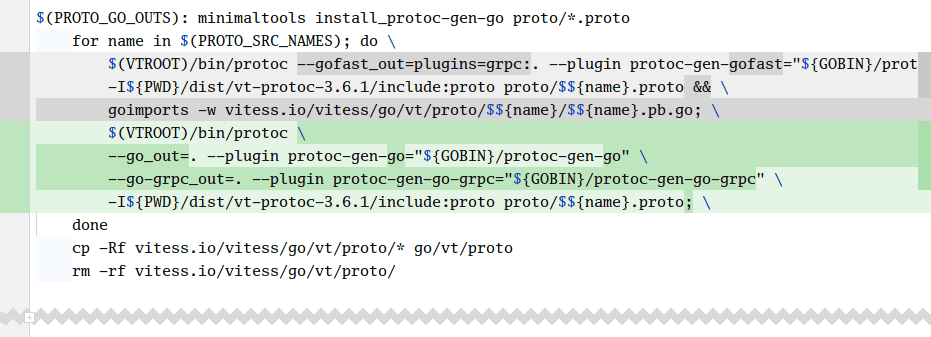
With the optimized Gogo code now gone, we’re expecting a performance regression. Let’s find out how bad it is in practice:
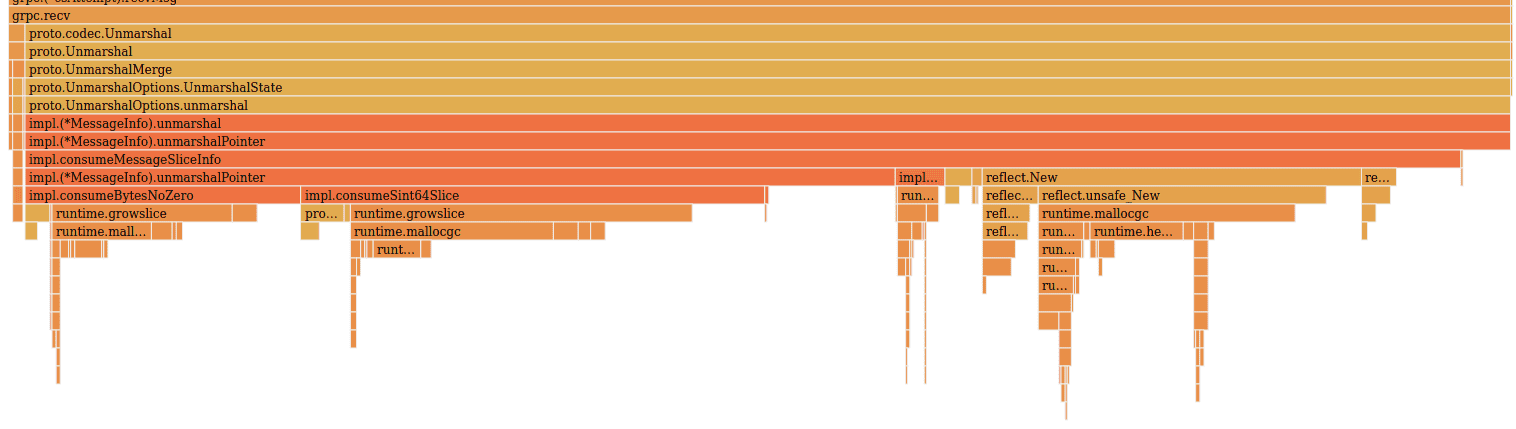
Oh no! We’re back at square one. The overhead of using reflection is back, and although the new reflection-based parser in ProtoBuf APIv2 is slightly faster than the one in V1, the total overhead of unmarshaling is massive compared to our Gogo ProtoBuf unmarshaling code. We’re now spending 7.17 CPU seconds.
Let’s enable the optimized code generation of vtprotobuf. We need to run the protoc-gen-go-vtproto generator alongside the protoc-gen-go and protoc-gen-go-grpc generators:
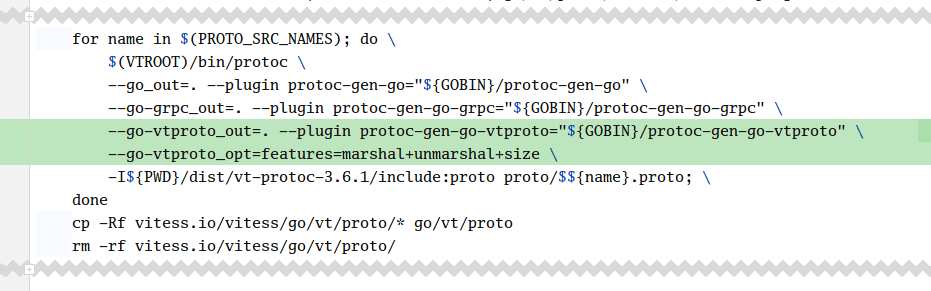
It is not enough to simply generate the optimized marshaling and unmarshaling helpers for our ProtoBuf messages. We need to opt our RPC framework into using those by injecting a specific codec. The vtprotobuf README has instructions for different Go RPC frameworks, including GRPC.
When running the benchmark again, we’re hoping to see performance very similar to Gogo ProtoBuf, but working on top of APIv2 ProtoBuf messages:
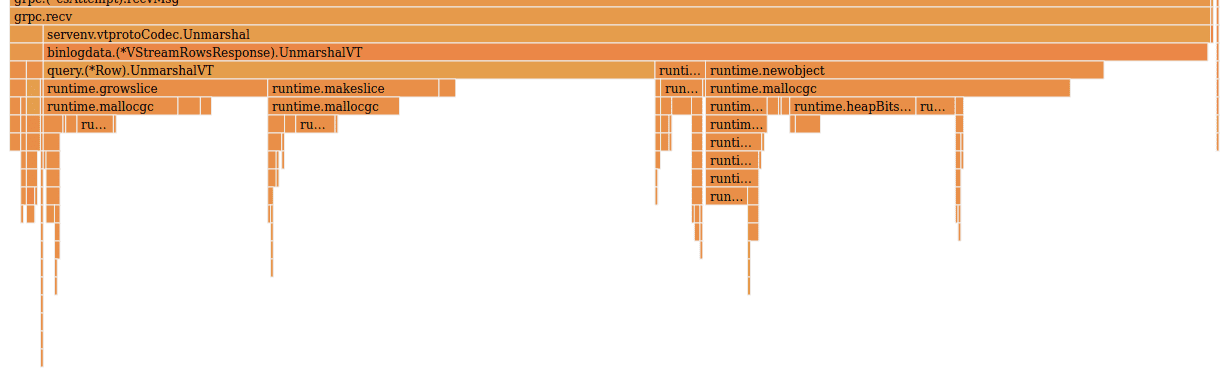
This is great. Reflection usage is now gone, and we can see how GRPC calls directly into our specialized UnmarshalVT helpers for each ProtoBuf message. There’s still the fixed overhead of memory allocation, but we’re spending 4.15 CPU seconds in unmarshal overhead now. We’re slightly faster than with Gogo ProtoBuf, and we’re unmarshaling into forward-compatible APIv2 ProtoBuf messages.
We could very easily stop here, since we’ve successfully upgraded Vitess to use ProtoBuf APIv2 without having a performance regression, but we want to go one step further. The VStreamRows RPC call in the VReplication process is an ideal use case for memory pooling.
To enable memory pooling, we add the pool feature to our protoc-gen-go-vtproto invocation, and specify which objects need to be memory pooled. For now, we’re just focusing on the Row and VStreamRowsResponse messages that are used in VReplication. To specify which messages must be pooled, we can use ProtoBuf extensions like Gogo ProtoBuf does, but in order to keep our .proto files free of foreign dependencies, we’ve also added the option to configure pooling directly as commandline flags.
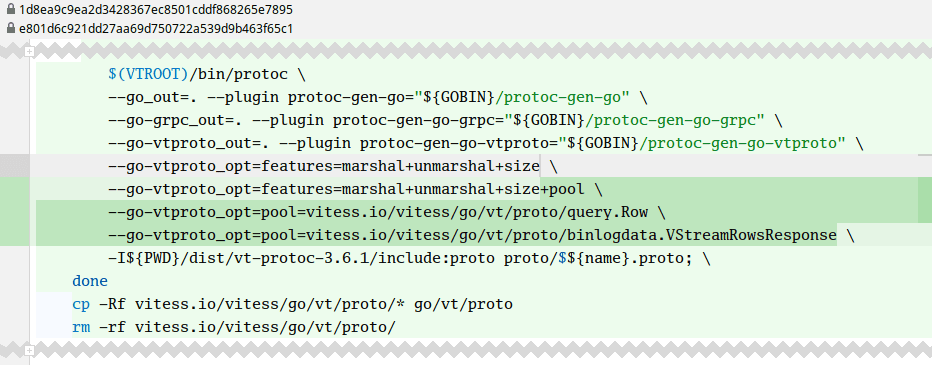
Once the pooling helpers for our messages have been generated, we must update the calling code to ensure we’re pooling the messages from the stream. For this specific VStreamRows API, Vitess already provides a callback-based abstraction behind the stream, so fetching and returning the messages from the pool is very easy to implement, assuming that receivers of the send(r) callback do not keep the message around – which they don’t.
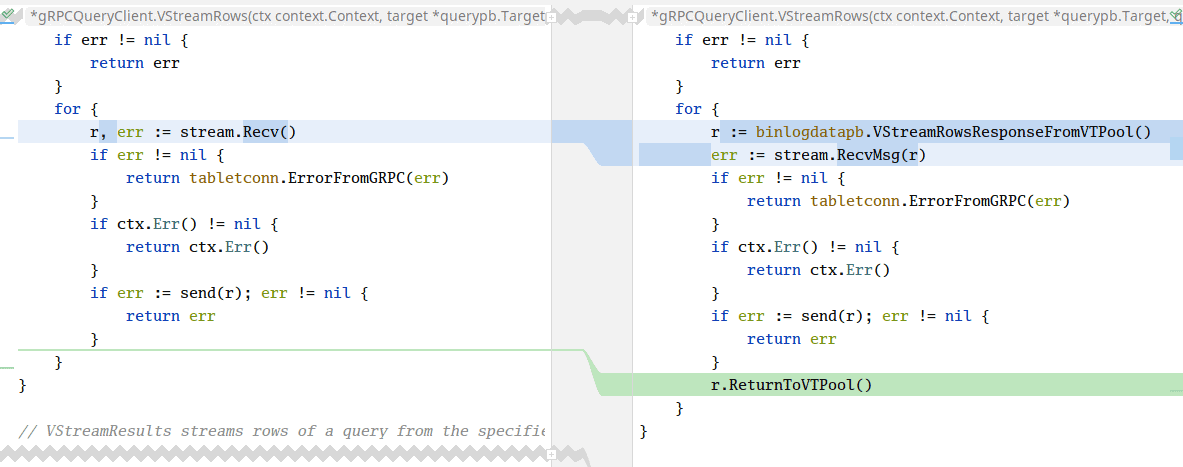
With these trivial changes in place, we can run our replication benchmark again and look at the overhead of unmarshaling the rows:

No, I did not screw up when cropping the flame graph. Once we enable memory pooling for VStreamRowsResponse objects, the unmarshaling code no longer needs to allocate memory for the underlying Row data. We’re spending 0.63 CPU seconds in unmarshaling now, because we just keep re-using the same few Response objects over and over again while copying rows from the source Vitess tablet.
The impact of the memory pooling optimization is clearly visible when graphed against the CPU usage of all the different ProtoBuf code generators:
Wrapping up #
Protocol Buffers performance in Go is a hard subject, which has only become much more complex with the release of the ProtoBuf APIv2 and the deprecation of Gogo ProtoBuf, the best recipe we’ve had in the past to reduce the CPU usage of the marshaling & unmarshaling overhead in our RPCs.
There are many open-source and proprietary Go projects that are either stuck in ProtoBuf APIv1 (because they rely on Gogo ProtoBuf) or that have upgraded to APIv2 and suffered a performance regression. We know that vtprotobuf is not able to handle all the use cases that Gogo ProtoBuf did, but we’re hoping it’ll enable many projects to migrate to ProtoBuf APIv2 without suffering a serious performance penalty, like we’ve done in Vitess, and result in a more unified and more performant Go ecosystem.
We’re actively testing the beta of vtprotobuf in the Vitess master branch already, and we’re hoping to ship the optimized codegen as the default for our next major Vitess release. Please feel free to try it out on your own projects and report any performance regressions or incompatibilities.