
Guest post originally published on the Kasten 10 Blog by Michael Cade
Kubestr is an open source collection of tools that makes it fast and easy to identify, validate and evaluate your Kubernetes storage options. Before we get into Kubestr and how it can help I wanted to highlight the Kasten Open Source Strategy and goals to the community.
Kasten Open Source Strategy
A key focus at Kasten is to enable the community with open-source software and projects. To that end, Kasten has a history of contributing to and innovating around open-source software. We’ve made a huge contribution to and are providing ongoing maintenance for the Kopia project. We also deliver continued innovation around Kanister, an extensible open-source framework for application-level data management for Kubernetes. Most recently, our effort around Kubestr unlocks the ability to identify, validate, and evaluate your Kubernetes storage options.
Open source has become increasingly important for cloud-native application development. Cloud-native applications typically consist of multiple services, many of which are open – source-based. While providing solutions for cloud-native workloads, Kasten is also using cloud-native approaches and architectures (drinking our own champagne). In doing so, we use open source solutions and give back to the community by contributing to it.
Benchmarking Your Kubernetes Storage

Since the days of spinning disks, platform operators and developers have been challenged with figuring out how to correctly size storage and make sure the correct capacity and performance requirements are reached. To add to this challenge, applications have different requirements for different workloads. While the fundamentals of storage benchmarking have not changed over the years — but our platforms have.
The reason we benchmark our storage across all platforms is to make sure that the infrastructure can run our applications, and that everything is validated and correctly configured.
Benchmarking your Kubernetes storage is not new, but it can be tedious. With Kubestr, we’ve created an “easy button” that makes it fast and simple to validate available storage options for your applications in Kubernetes.
The Rise of Stateful Workloads

The first wave of workloads for Kubernetes was targeted for stateless services, as they were very easy to refactor and generally lived outside of the Kubernetes cluster. Existing within virtual machines and cloud-based managed services, these workloads would consist of databases and content management systems, to name a few.
The fast-paced growth and maturity of Kubernetes has enabled a new standard in the Container Storage Interface (CSI). The CSI makes it possible for third-party storage providers to develop solutions without adding to the core Kubernetes codebase. This has enabled storage providers to decouple storage from the underlying orchestration engine and create a standard storage interface. As a result, we can now bring stateful workloads inside the Kubernetes cluster and enjoy the benefits of ease of use and flexibility.
We can now deploy traditional workloads such as SAP, SQL Server, Oracle and Hadoop on Kubernetes. And, we can leverage the same storage backend for running data stores for microservices such as MongoDB, Cassandra, Redis, MySQL and PostgreSQL.
The CSI initiative not only introduces a uniform interface for storage vendors across container orchestrators, it also makes it much easier to provide support for new storage systems to encourage innovation, and, most importantly, to provide more options for developers and operators.
All of this is great, but how do we ensure that the right data store is used to achieve the performance required for our microservices running these stateful workloads?
KubeStr – The Easy Button for Evaluating and Validating Kubernetes Storage
Kubestr is a collection of tools that makes it fast and easy to identify, validate and evaluate your Kubernetes storage options. Here’s how it works:
- Identify: There’s an overwhelming choice of storage options available to us for Kubernetes. Consider the public cloud and the various storage options, as well as the available compute node options that reflect the storage performance and capacity. All of that plays a huge part in designing and architecting your Kubernetes cluster and environment. Kubestr is not only for Day 1; it can also help identify storage options available to existing clusters, making it easier to control and understand of the performance available and whether or not it’s being wasted.
- Validate: We also mentioned validation, and the importance of making sure you have correctly configured your environment. Kubestr can confirm that your storage is capable of snapshots, an important feature of your data protection methodology within your stateful workloads. Kubestr creates a lightweight operating system application, which includes a persistent volume claim and persistent volume, takes a snapshot, performs a data restore and validates that the data is what it should be.

- Evaluate: At the evaluation stage, Kubestr evaluates the performance characteristics of the storage using FlexibleIO (fio). FIO is built into the application and works as described in the validate stage, without the snapshot and restore testing. Instead, Kubestr runs an I/O test against the selected storage and provides you with immediate results.
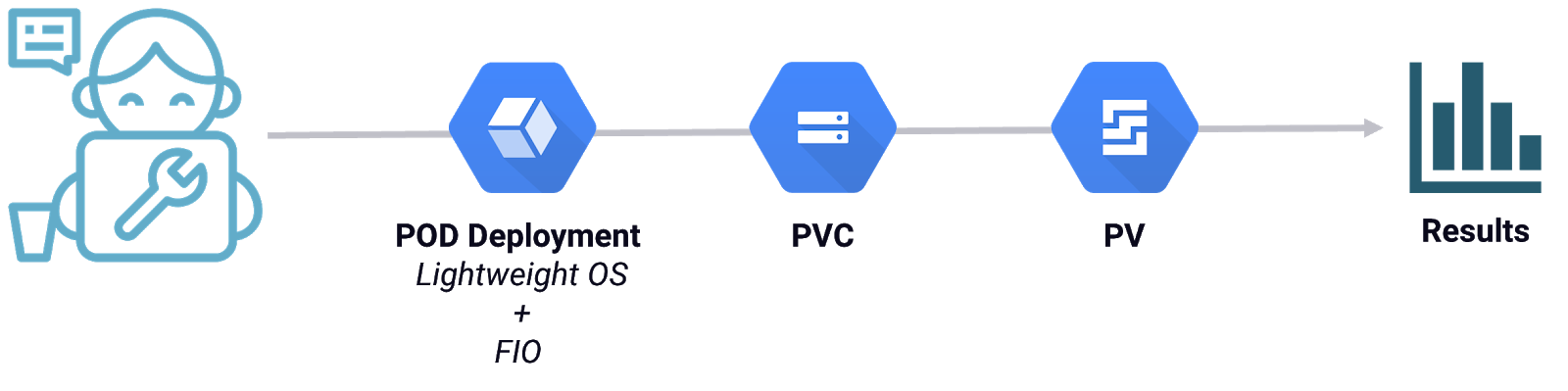
When it comes to storage, there are many options, and choosing which way to go becomes even more complex when navigating the public cloud and managed Kubernetes offerings. Kubestr provides an easy way to choose the right storage type for your required workload and ensure you have the right compute nodes to enable that storage to perform at its best. Choice is a fantastic privilege, and Kubestr is a handy little tool that helps to make those informed decisions, faster, about Kubernetes storage.
More Information
Kubestr is available for multiple platforms including macOS, Windows and Linux. If you would like to find more information and demo Kubestr, simply scan the QR code below.
