
Guest post by Huawei and Leinao.ai
Introduction to the Leinao cloud AI platform
The Leinao cloud AI platform includes an AI development platform, public service platform, AI visualized operations platform, and an AI community.
- The AI development platform provides end-to-end technical support and solutions for AI researchers in a diverse range of business scenarios.
- The public service platform provides news and insight into AI for institutions and for the general public.
- The AI visualized operations platform helps managers make better informed decisions.
- The AI community is where AI developers and companies gather, exchange ideas, and improve their skills.
The architecture of Leinao cloud OS
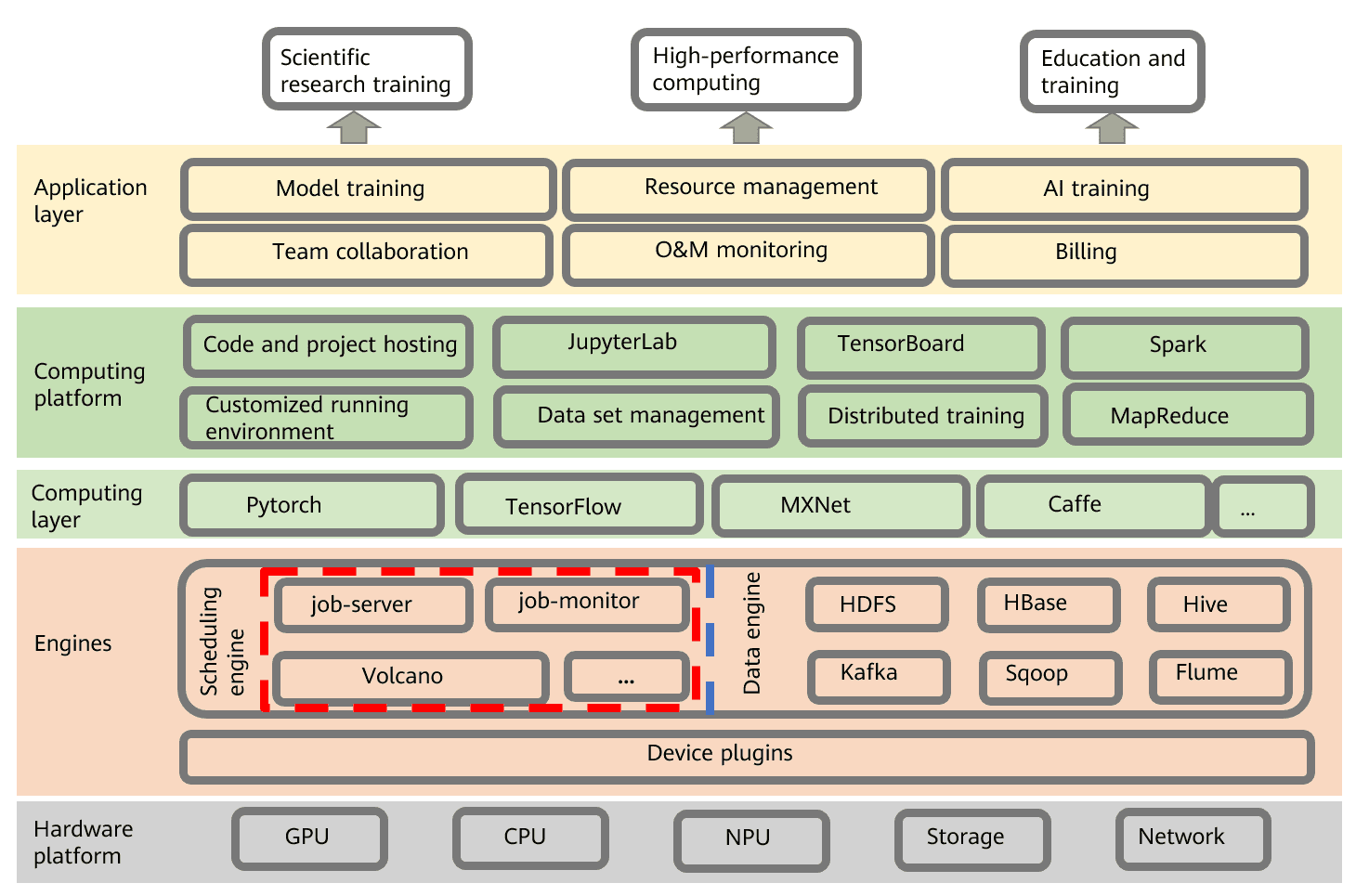
In the Leinao OS, the hardware platforms sit at the bottom of the architecture. On top of them are the job scheduling and data engines. The computing layer, the next layer up, is composed of a set of APIs used to create general distributed training jobs. Finally, on the top, is the application layer, which consists of various service systems, such as the model training, resource management, and O&M monitoring systems.
Why Volcano?
The Kubernetes default-scheduler does not work well for batch scheduling, and batch scheduling is critical to AI and big data services. Therefore, when we were building Leinao cloud OS 2.0, we decided to replace the default-scheduler with a scheduling engine that can better serve AI and big data scenarios. Volcano has diverse advanced scheduling policies and can easily connect to mainstream computing frameworks in the AI and big data sectors.
More importantly, Volcano allows you to configure retry policies for distributed training jobs based on events rather on the number of retries. It is more flexible. In addition, it is more light-weighted than Hadoop, which is a distributed processing framework that also supports batch scheduling. After thorough analyses and comparisons, we finally chose Volcano for Leinao cloud OS 2.0.
Volcano provides enhanced job APIs.
| Function | Volcano |
| Task set | PodGroup |
| Retry policies for distributed training jobs | Diverse policies based on events and actions |
| Resource queue division | Queue |
| Status definition | Detailed definition |
| Support for deep learning frameworks | Multiple frameworks supported |
| Support for big data jobs | Supported |
Volcano improves many aspects of default-scheduler.
| default-scheduler | Volcano |
| Distributed training jobs occupy resources but sometimes produce nothing. | Gang scheduling |
| Small jobs are sometimes starved for resources occupied by larger jobs. | Domain resource fairness (DRF) supported |
| No resource pool division and management | Queue is introduced to divide and manage resource pools. |
Default-scheduler and Volcano work differently in a couple of other ways as well.
| default-scheduler | Volcano |
| Scheduling policies extended through scheduler plugins | Customized plugins supported |
| Predict and priority stages | Apart from the predict and priority stages, there are resource preemption, backfill, and reservation. |
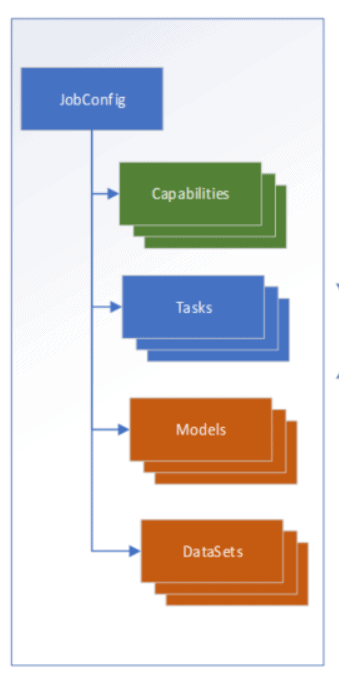
We encountered some obstacles when we connected the OS to Volcano. For example, OS development was already complete when we tried to connect it to Volcano, and connecting them directly required a huge change to the OS’s computing and application layers. Moreover, Volcano did not support debugging jobs and tool sets yet. That was when we decided to introduce job-server, for API adaptation and integrated development of debugging tool sets.
| Requirement | Solution |
| Compatible with the original JobConfig requests | Adapt APIs. |
| Support for sing-node jobs | Use job-server to adapt APIs. |
| Support for distributed training jobs | |
| Debugging jobs (JupyterLab, Wetty, and code-server) | Develop this feature. |
| Visualized TensorBoard | Develop this feature. |
| Storage optimization plugins | Develop this feature. |
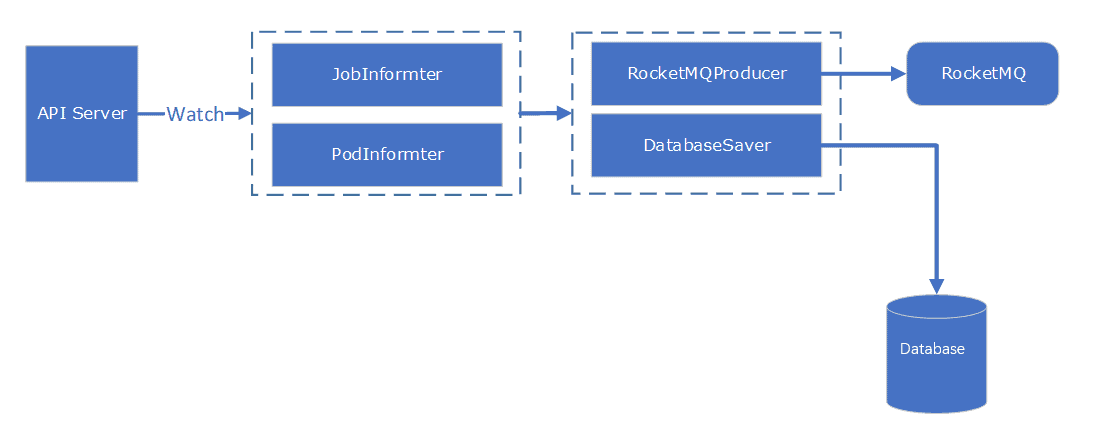
Another problem we faced was how to deal with task monitoring. Upper-layer services need detailed information on current and recent task status, and historical records, but Volcano only supports job monitoring. Should we customize Volcano or further develop the OS to support task monitoring? If we customize Volcano, it would get complicated later on, when we want to upgrade Volcano. The Volcano community iterates in a fast speed. We did not want to miss its latest features provided with every iteration. Therefore, we went with the latter choice, that is, to further develop the OS.
The following figure shows the monitoring mechanism. It uses an API server to watch jobs and pods.
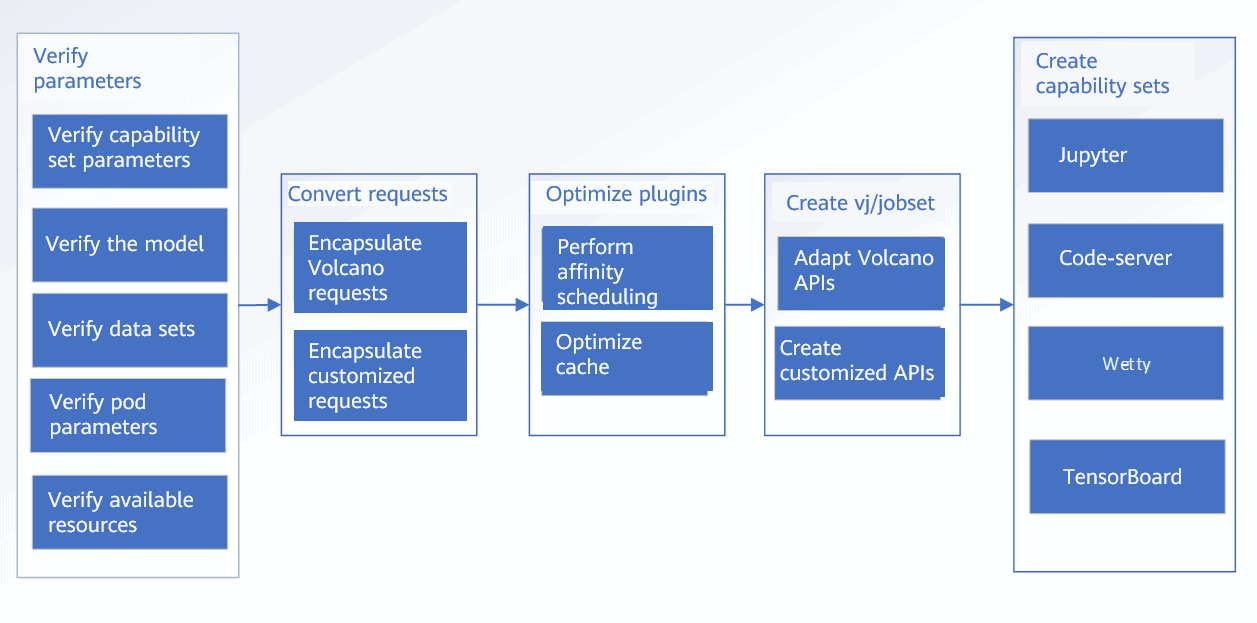
Creating a job
Scenario requirements:
- Jobs can be created in batches.
- Debugging tool sets, such as JupyterLab, TensorBoard, code-server, and Wetty, are supported.
- Data storage set optimization policies can be configured for batch jobs.
- Training, quantization, and model conversion are supported.
The workflow is as follows:
Deleting a job
Scenario requirements:
- Jobs are automatically deleted when they finish.
- Additional capabilities (Jupyter and code-server) of the jobs are deleted, as well.
When the job finishes, Volcano automatically deletes it.
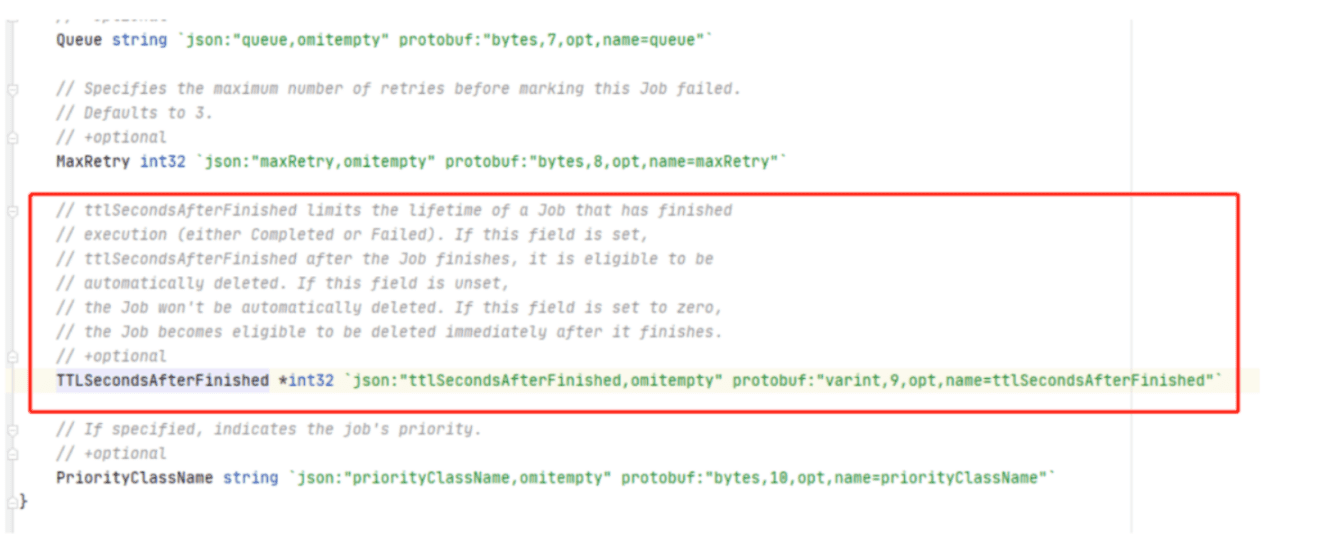
Related resources (pods, services, and ingresses) are deleted.
Retrying a job
In OS 1.0, retry policies are set simply based on the number of retries. Volcano allows you to set retry policies based on events. It is much more flexible and better suits our scenarios. We gave up on our original solution and adopted the retry mechanism of Volcano.
| Event Value | Trigger |
| “*” | All events |
| PodFailed | The pod failed. |
| PodEvicted | The pod was evicted. |
| Unknown | Some pods are gang-scheduled and running, but others failed to be scheduled. |
| TaskCompleted | All tasks in taskRole have finished. |
| Action Value | Response |
| AbortJob | Exit the job. The job status is aborted.All pods in the job are evicted and will not be created again. |
| RestartJob | Restart the job. |
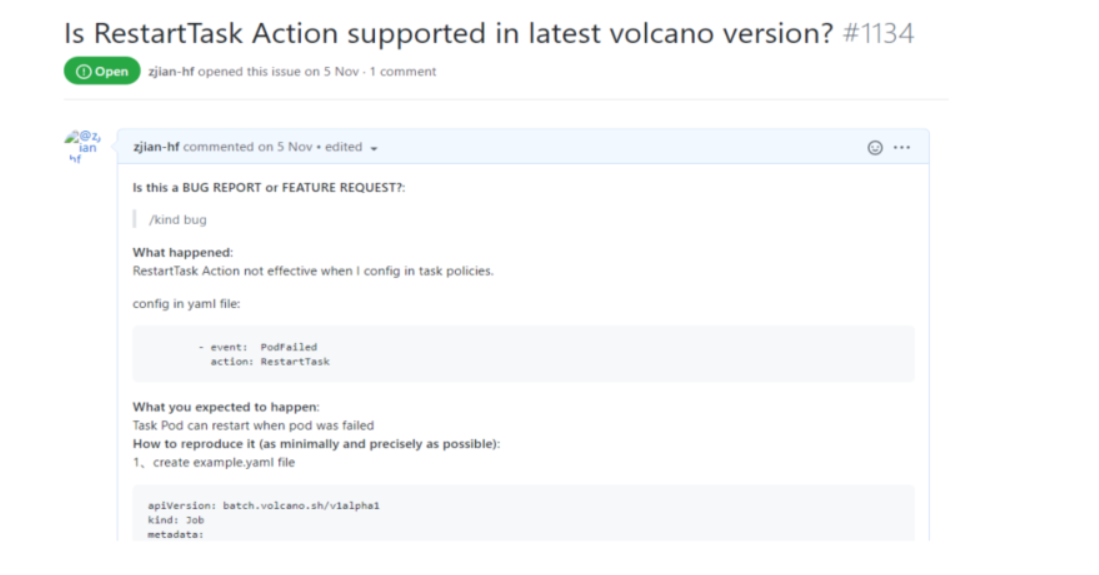
| RestartTask | Restart the task only. Currently not supported. |
| TerminateJob | Exit the job. The job status is terminated. The job cannot be resumed.All pods in the job are evicted and will not be created again. |
| CompleteJob | The job status is completed. Kill unfinished pods. |
| ResumeJob | Resume the job. |
- Policies defined in taskRole have a higher priority than the retry policies defined in jobs. A retry policy consists of an event and action.
- event indicates a triggering condition.
- action indicates the action to take when the specified triggering condition is met.
- maxRetry indicates the maximum number of retries allowed for a job.
When we were developing the OS to support task monitoring, we received great support from the Volcano community. For example, we once found that RestartTask became invalid. The problem was solved the same day it was reported to the community. Their response was very fast.
Next Up
We look forward to working with the community on topology scheduling and how to select the best GPU topology for scheduling when there are multiple GPUs on a single server. We seek deeper cooperation with the community in developing more advanced features and building a more inclusive ecosystem.
For more details about Volcano, visit:https://volcano.sh/zh/