

Guest post by Volcano Community Maintainer
Kubernetes is a popular container orchestration framework mainly used to deploy microservice applications in the early development phase.
An increasing number of users want to run big data and AI frameworks such as Spark and TensorFlow on Kubernetes, so that they can run all their applications on a unified container platform. However, to run these high performance computing (HPC) applications, advanced scheduling functions are required, for example, fair-share scheduling, priority-based scheduling, and queue scheduling. The default scheduler of Kubernetes only supports pod-based scheduling. Although the scheduling framework has been incorporated in Kubernetes V1.17, it cannot provide job-based scheduling for HPC applications.
Volcano, a general-purpose batch scheduling system built on Kubernetes, was launched to address HPC scenarios in cloud native architecture. It supports multiple computing frameworks such as TensorFlow, Spark, and MindSpore, helping users build a unified container platform using Kubernetes. Volcano features powerful scheduling capabilities such as job scheduling and provides diverse functions, including job lifecycle management, multi-cluster scheduling, command line, data management, job view, and hardware acceleration.
In terms of scheduling, Volcano provides scenario-based algorithms and solutions and also scheduling frameworks to facilitate scheduler extension. Based on scenarios and job attributes, distributed computing or parallel computing can be further classified. In An Introduction to Parallel Computing, parallel computing is classified into three types.
Simple parallel
Simple parallel means that multiple tasks of a job can be executed completely in parallel without communication or synchronization. A typical example is MapReduce. Mapper tasks do not communicate with each other or synchronize the running status during execution. Another common example is Monte Carlo methods, in which tasks do not need to communicate or synchronize with each other when calculating random numbers. Such parallel computing is widely used in different scenarios, for example, data processing and VatR. Accordingly, different scheduling frameworks, such as Hadoop, DataSynapse, and Symphony, are developed for these scenarios. As communication and synchronization are not required between tasks, the entire job can still be completed even when several compute nodes (workers) are evicted. However, the job execution time may be prolonged. When the number of workers increases, the job execution time will be shortened. This type of job is called Elastic Job.
Complex parallel
Complex parallel requires that multiple tasks of a job collectively execute a complex parallel algorithm by synchronizing information with each other. Typical examples are the TensorFlow modes PS-Worker and Ring All-reduce. This job attribute poses higher requirements on the job scheduling platform, such as gang scheduling and job topology. Tasks of such jobs need to communicate with each other, and therefore new tasks cannot be extended after jobs are started. Without checkpoints, the entire job must be restarted when any task fails or is evicted. This type of job is called Batch Job, most of which run in traditional HPC scenarios. Slurm, PBS, SGE, and HTCondor are scheduling platforms for these batch jobs.
Pipelined parallel
Pipelined parallel means that multiple tasks of a job depend on each other, but subsequent tasks can start before the previous tasks are complete. For example, in the Hadoop framework, the Reduce phase is partially started before the Map phase is complete, which improves task concurrency and execution efficiency. Pipelined parallel computing has very limited application scenarios (mostly for performance optimization). Therefore, there is no dedicated platform to manage such jobs. Pipelined parallel computing is different from workflow. A workflow refers to the dependency between jobs. As the jobs in a workflow differ greatly, it is difficult to start subsequent jobs before the previous jobs are complete.
“Secondary scheduling” is another concept we mention together with parallel computing. A simple parallel job contains a large number of tasks, with each task requiring basically the same resources. Secondary scheduling is ideal for such jobs and can ensure a relatively high resource reuse rate. Both Hadoop YARN and Platform Symphony EGO adopt the same secondary scheduling principle. However, secondary scheduling is not designed for complex parallel jobs. A complex parallel job usually contains a few tasks that must be started simultaneously. The communication topologies between tasks may be different (for example, PS/Worker or MPI). In addition, the tasks require different resources, which results in low resource reuse rate.
Although there are different management platforms for the two types of parallel jobs, the goal is to allocate the best resources for jobs. This is why Volcano is designed to support multiple types of jobs. So far, you can easily manage your Spark, TensorFlow, and MPI jobs on Volcano.
Common Scheduling Scenarios
Gang scheduling
When running a batch job (such as TensorFlow or MPI), all tasks of the job must be coordinated to start together; otherwise, none of the tasks will start. If there are enough resources to run all tasks of a job in parallel, the job will execute correctly. However, this is usually not the case, especially in on-premises environments. In the worst-case scenario, all of the jobs are pending due to deadlock. That is, every job has only successfully started some of its tasks and is waiting for the remaining tasks to start.
Job-based fair-share scheduling
When running several elastic jobs (for example, streaming), it’s better to fairly allocate resources to each job to meet their SLA/QoS when multiple jobs are competing for additional resources. In the worst-case scenario, a single job may start a large number of pods but not actually use them, and therefore other jobs cannot run due to insufficient pods. To avoid allocations that are too small (for example, one pod started for each job), the elastic job can leverage gang scheduling to define the minimum available number of pods that should be started. Any pods beyond the specified minimum available amount will share cluster resources with other jobs fairly.
Queue scheduling
Queues are widely used to share the resources for elastic and batch workloads. Specially, queues are used to:
Share resources among tenants or resource pools.
Provide different scheduling policies or algorithms for different tenants or resource pools.
These functions can be further extended with hierarchical queues. Sub-queues in a hierarchical queue are given an additional priority, which allows them to “jump” ahead of other sub-queues in the queue. In kube-batch, queues are implemented as cluster-wide Custom Resource Definitions (CRDs). This allows jobs created in different namespaces to be placed in a shared queue. Queue resources are proportionally allocated based on their queue configuration (kube batch#590). Hierarchical queues are currently not supported, but are being developed.
Other HPC systems can handle queues containing hundreds or thousands of jobs. Clusters should also be able to handle a large number of jobs in the queue without slowing any operations. It is an open question of how to achieve such behavior with Kubernetes. It might also be useful to support queues spanning multiple clusters.
Namespace-based, fair-share, cross-queue scheduling
In a queue, each job has an almost equal opportunity to be scheduled in a scheduling cycle. This means that a user with more jobs has a greater chance of having their job scheduled, which is unfair to other users. For example, when a queue contains a small amount of resources, and there are 10 pods belonging to user A and 1,000 pods belonging to user B, pods of user A are less likely to be scheduled to a node.
A more fine-grained policy is required to balance resource usage among users in the same queue. As Kubernetes supports a multi-user model, namespaces are used to distinguish users. Each namespace is configured with a weight to determine the resource use priority.
Fairness over time
Batch workloads require that resources are fairly allocated over a long period of time, but not at any specific time point. For example, it is acceptable for a user (or a specific queue) to occupy half of the total cluster resources to run a large job within a certain period, but if this extends into the scheduling cycle (which may be several hours after the job is complete), the user (or queue) should be penalized. You can run HTCondor jobs to see how this behavior is implemented.
Job-based priority scheduling
The pod priority/preemption function was released in Kubernetes V1.14. It ensures that high priority pods are bound to a node before low priority pods. However, there are still some optimizations to be made on job/PodGroup-based priority. For example, high priority jobs/PodGroups should try to preempt a whole job/PodGroup with a lower priority instead of several pods from different jobs/PodGroups.
Preemption & Reclaim
In the loan model by fair share, some jobs or queues will overuse resources when they are idle. The resource owner will reclaim the resources if there are any further resource requests. The resources can be shared between queues or jobs. The reclaim action is used to balance resources between queues, and the preempt action is used to balance resources between jobs.
Reservation & Backfill
When a huge job that requests a large number of resources is submitted to Kubernetes, the job may starve or finally be killed based on the current scheduling policy or algorithm if there are many small jobs in the pipeline. To prevent starvation, resources should be reserved for jobs conditionally, such as by setting the timeout period. When resources are reserved, they may be idle or unused. To improve resource utilization, the scheduler will backfill smaller jobs to those reserved resources conditionally. Both reservation and backfill are triggered based on the results returned by plugins. The Volcano scheduler provides APIs for developers or users to determine which jobs are reserved or backfilled.
Volcano Scheduling Framework
The Volcano scheduler can schedule various types of jobs through multiple plugins. These plugins effectively support scheduling algorithms in different scenarios, such as gang scheduling (co-scheduling) and fair-share scheduling at each resource level. The following figure shows the overall architecture of the Volcano scheduler.
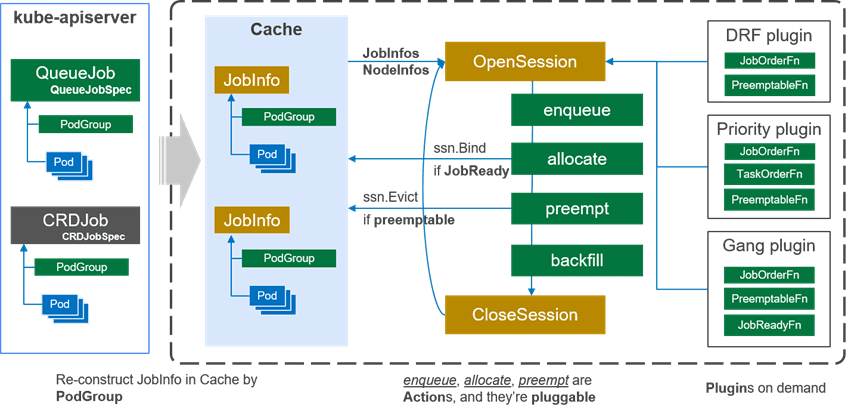
The Cache component caches the node and pod information in clusters and reconstructs the relationship between jobs (PodGroups) and tasks (pods) based on the PodGroup information. To ensure information consistency in a distributed system, the Volcano scheduler always schedules jobs based on the cluster snapshot at a certain time point and makes consistent decisions in each scheduling cycle. In each scheduling cycle, Volcano dispatches jobs as follows:
1. Volcano creates a Session object to store data required in the current scheduling cycle, such as cluster snapshots. Currently, the scheduler creates only one Session, which is executed by one scheduling thread. In later versions, the scheduler is allowed to create multiple Sessions, with each Session executed by a thread. Cache is used to resolve scheduling conflicts.
2. Volcano executes the actions in an OpenSession and a CloseSession in sequence. In an OpenSession, users can register user-defined plugins such as Gang and DRF to provide algorithms for actions. After the actions are executed based on the configured sequence, the CloseSession will clear the intermediate data.
1) There are four default actions in a scheduling cycle: enqueue, allocate, preempt, and backfill. The allocate action defines the resource allocation process during scheduling. Specially, the allocate action sorts jobs based on JobOrderFn and nodes based on NodeOrderFn, checks the resources on the nodes, and selects the most suitable nodes for the jobs in the JobReady state. As the actions are implemented through plugins, users can redefine their allocation actions, for example, firmament (a graph-based scheduling algorithm).
2) The plugins define the algorithms required by actions. For example, the DRF plugin provides the JobOrderFn function to sort jobs based on the dominant resource. The JobOrderFn function calculates the share value of each job based on DRF. A smaller share value indicates that fewer resources are allocated to the job. Therefore, resources will be preferentially allocated to this job. The DRF plugin also provides the EventHandler function. After a job is allocated with resources or preempts resources, the scheduler instructs the DRF plugin to update the job share value.
3. Cache not only provides cluster snapshots, but also provides interfaces (such as bind) for interaction between the scheduler and kube-apiserver.
The Volcano scheduler adds multiple pod states to improve scheduling performance in the preceding scenarios.
- Pending: After a pod is created, it is in the Pending state and waits to be scheduled. The purpose is to find the optimal destination for these pending pods.
- Allocated: When idle resources are allocated to a pod but no scheduling decision is sent to kube-apiserver, the pod is in the Allocated state. The Allocated state exists only in the scheduling cycle and is used to record pod and resource allocation information. When a job meets the startup conditions (for example, minMember), the scheduler submits a scheduling decision to kube-apiserver. If the scheduling decision cannot be submitted in the current scheduling cycle, the pod status will be rolled back to Pending.
- Pipelined: This state is similar to Allocated. The difference is that the resources allocated to the pod in this state are the ones being released by other pods. This state is used during the scheduling cycle and will not be updated to kube-apiserver, which reduces communication and QPS of kube-apiserver.
- Binding: When a job meets the startup conditions, the scheduler submits a scheduling decision to kube-apiserver. Before kube-apiserver returns the final state, the pod remains in the Binding state. This state is also stored in the cache of the scheduler and is valid across scheduling cycles.
- Bound: After the job scheduling decision is confirmed by kube-apiserver, the pod changes to the Bound state.
- Releasing: The pod is in the Releasing state when it waits to be deleted.
- Running, Failed, Succeeded, and Unknown: no changes compared with the current design.
The state changes according to different operations, as shown in the following figure.
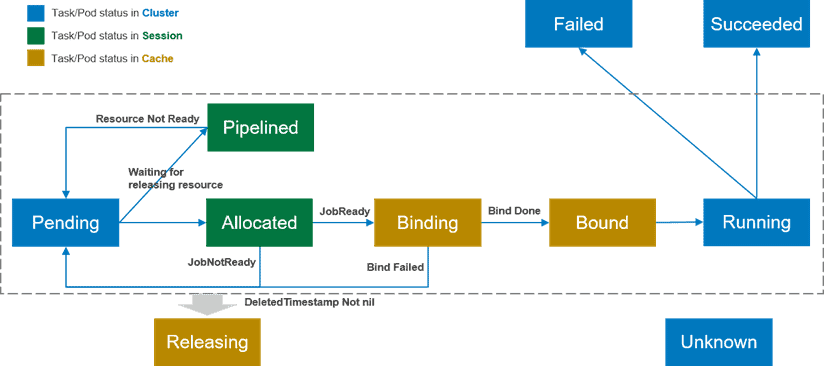
These pod states provide more optimization possibilities for the scheduler. For example, when a pod is evicted, the cost of evicting a pod in the Binding or Bound state is lower than that of evicting a pod in the Running state. In addition, the states are recorded in the Volcano scheduler, reducing the communication with kube-apiserver. However, the Volcano scheduler does not fully unleash the power of pod states. For example, the preemption/reclaim function only evicts pods in the Running state. This is because it is difficult to completely synchronize states in a distributed system. For example, a pod in the Binding state may change to Bound so fast that it fails to be evicted.
Volcano Scheduling Implementation
The Volcano scheduler uses actions and plugins to support the preceding scenarios.
Actions enable different types of operations and plugins make decisions. For example, fair-sharing, queues, and co-scheduling (gang scheduling) are implemented through plugins. Plugins can determine which jobs should be scheduled first. The preemption, reclaim, backfill, and reserve operations are implemented through actions, for example, job A preempts job B.
Note that actions and plugins work together. For example, the fair-sharing plug-in partners with the action allocate to work. The action preempt is supported by the plug-ins to select the jobs for preemptive scheduling.
The following uses job-based fairness (DRF) and preemption to illustrate how actions and plugins work.
DRF: Currently, fair-share scheduling is based on the DRF and implemented through plugins. In OpenSession, the dominant resource and the initial share value of each job are calculated first. Then, the JobOrderFn callback function is registered. The JobOrderFn function receives two jobs and sorts the jobs based on the share value and the dominant resource of the objects. The EventHandler is registered in this process. When a pod is allocated or preempted, DRF dynamically updates the share value based on the corresponding job and resource information.
Other plugins share a similar implementation scheme. The corresponding callback functions, such as JobOrderFn and TaskOrderFn, are registered in OpenSession. The scheduler determines how to allocate resources based on the callback function result and updates the number of scheduling times in the plugin through EventHandler.
Preemption: The preempt action is performed after the allocate action. It selects one or more jobs with lower priority to evict. Preemption is different from allocation. The preempt action is created to select jobs with different priorities, but it still relies on plugins. Other actions share a similar implementation scheme, that is, converting job selection into an algorithm plugin.