

Guest post by Volcano Community Maintainer
Volcano is a Kubernetes native batch scheduling system. This open-source project is optimized for compute-intensive workloads, and is especially useful in sectors such as AI, big data, genomics, and rendering. Mainstream computing frameworks in these sectors can easily connect to Volcano to integrate high-performance job scheduling, heterogeneous chip management, and job management.
Why do you need Volcano?
- Group Scheduling
The default scheduler of Kubernetes schedules containers one by one. This can waste resources and result in resource bottlenecks, causing containers to deadlock in scenarios where a group of containers need to be scheduled all at the same time, for example, in AI training jobs or big data applications.
Suppose an AI application consisting of 2 ps containers and 4 worker containers needs to be scheduled onto limited resources. When the default scheduler tries to schedule the last worker container, if there are no resources available, the scheduling fails. The job hangs as the application cannot run without that last worker container. Meanwhile, resources occupied by the already scheduled containers produce nothing.
This is where Volcano comes in. It ensures that a gang of related containers can be scheduled at the same time. If for any reason it is not possible to deploy all of the containers in a gang, Volcano will not schedule that gang. In practice, it is not uncommon for us to deploy a set of internally dependent containers onto limited resources. Volcano is vital in these cases as gang scheduling eliminates potential deadlocks resulting by insufficient resources. Volcano significantly improves resource utilization for heavily loaded clusters.
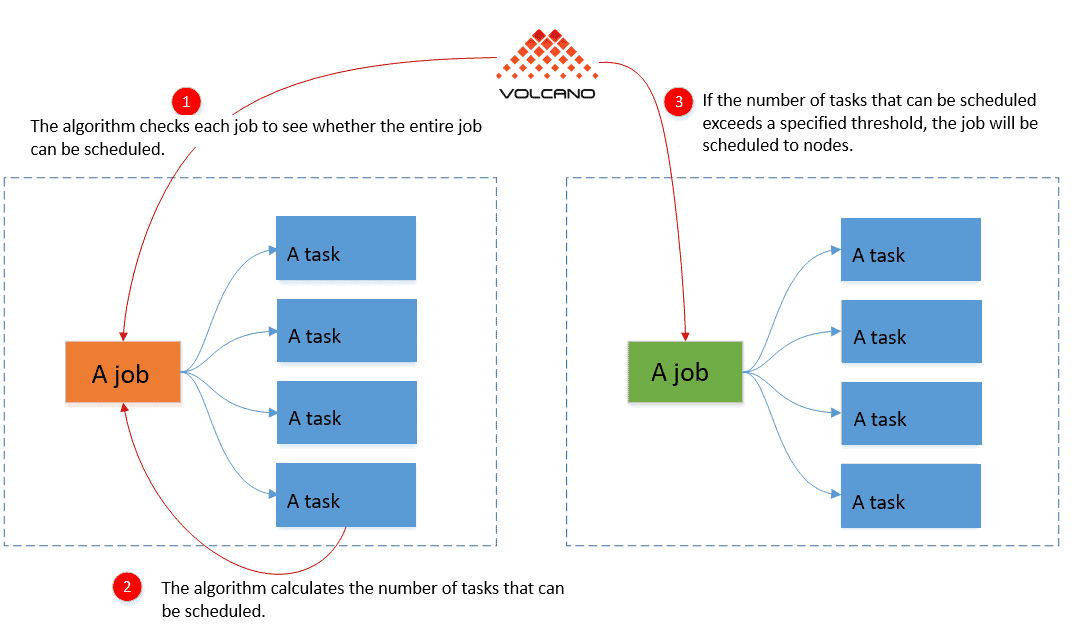
Gang scheduling is based on container groups, or “jobs” as they are called in the code. With gang scheduling, the algorithm checks each job to see whether the entire job can be scheduled. The containers in each group are called “tasks”. If the number of tasks that can be scheduled exceeds a specified threshold, the job will be scheduled to nodes. This process of scheduling is called “bind nodes” in the code.
- Automatic Optimization of Resource Allocation
Containers are scheduled to the nodes that can supply the CPU, memory, GPU, and other resources necessary for the job. Typically, multiple nodes will be available. Each node will have different resources available for new workloads. Volcano analyzes the expected resource utilization for different scheduling plans, and selects the most appropriate node for the job.
- Support for a Range of Advanced Scheduling Scenarios
Volcano offers a diverse set of scheduling algorithms, such as priority, domain resource fairness (DRF), and binpack, which means you can more easily handle diverse services requirements. For example, you may want to ensure DR and disruption isolation when deploying your applications. With Volcano, you can easily deploy containers running the same application but on different nodes, and with each node only having one pod. In another scenario, to ensure that certain applications do not compete for resources, you may want to avoid deploying them on the same node. Volcano can help you do that.
How does Volcano manage all of this? Let’s take a closer look at some of the scheduling algorithms Volcano offers.
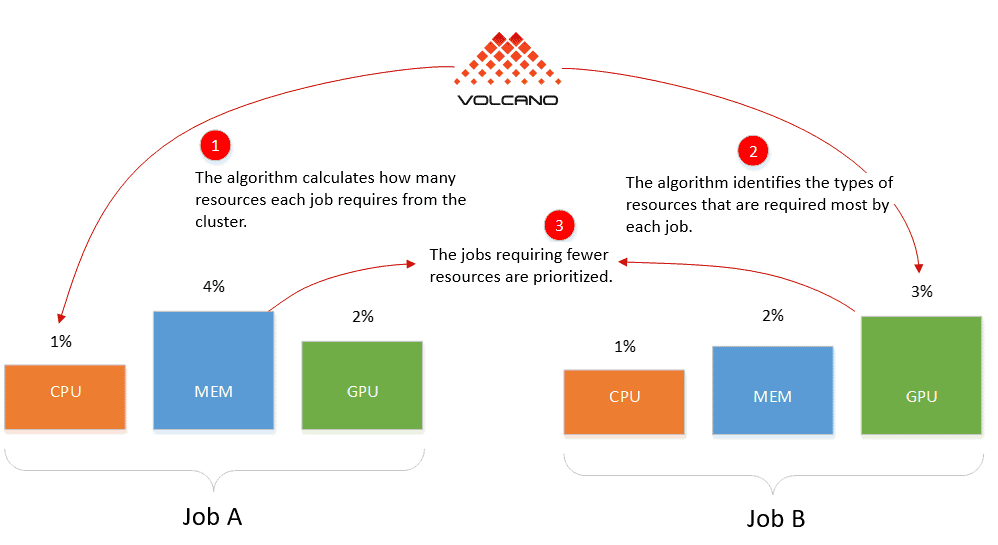
The DRF algorithm is used by both YARN and Mesos but not Kubernetes. DRF prioritizes jobs requiring fewer resources so more jobs can be performed. Smaller jobs will not be starved for resources occupied by larger jobs. DRF treats each job, such as an AI training job or a big data analysis job, as a single unit for scheduling purposes.
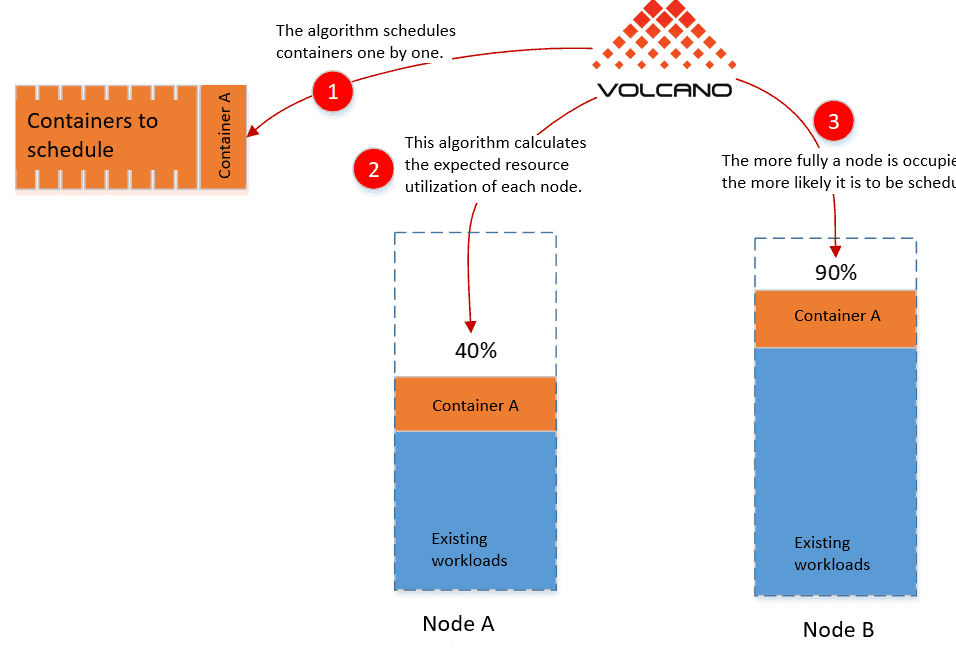
The binpack algorithm tries to ensure that any node that is occupied is occupied as fully as possible. It avoids scheduling empty nodes in favor of occupied nodes, and the more fully a node is occupied, the more likely it is to be scheduled. This algorithm calculates the resource utilization of each node. It concentrates your workloads in the cluster, which works better with the auto-scaling of Kubernetes clusters. With binpack, each container is treated as an individual scheduling unit.
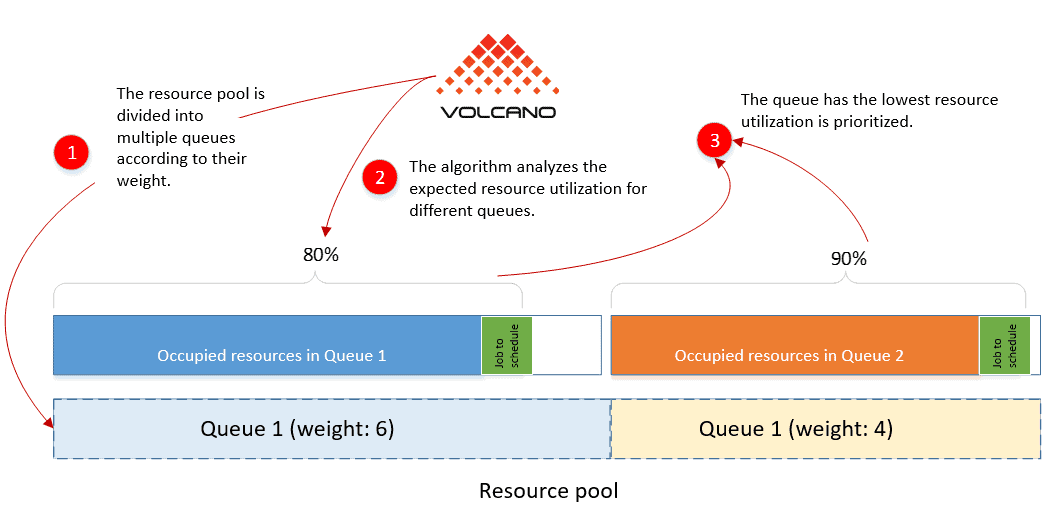
The queue (proportion) algorithm is offered in YARN but not Kubernetes. Volcano makes it up for Kubernetes. This algorithm is used to control the overall resource allocation of a cluster. For example, if two teams in a company are sharing a pool of compute resources, queue can be used to specify that team A can use up to 60% of the total cluster resources, and team B up to 40%. The algorithm prioritizes the queue that has the lowest expected resource utilization.
Volcano has many scheduling algorithm plugins and conflicts may occur, so weight is introduced to each plugin. It ensures that a final scheduling decision can be made. For example, in Kubernetes scheduling, there are two stages, the predict stage and the priority stage. In the first stage, nodes that fail to meet requirements are filtered out. In the second stage, nodes are scored. The NodeOrder algorithm scores all nodes in the second stage according to the different weight of each algorithm plugin.
Volcano originated from kube-batch, a project initially intended to address issues with gang scheduling in Kubernetes. Later, as AI and big data services started demanding stronger and more versatile scheduling in Kubernetes, kube-batch was combined with various scenario-specific practices to provide enhanced scheduling capabilities. It was then renamed Volcano to reflect its power and a glowing future.
For more details about Volcano, visit https://volcano.sh/.