




“Guest post originally published on Buoyant’s blog by Risha Mars, Software Engineer at Buoyant
In this article we’re going to show you how to accomplish a basic Kubernetes observability task: getting “golden metrics” (or “golden signals”) from the applications running on your Kubernetes cluster. We’ll do this without changing any code or doing any configuration by installing Linkerd, an open source, ultralight service mesh. We’ll cover what a service mesh is, what the term “observability” means, and how the two relate in the Kubernetes context.
Monitoring Kubernetes applications with a service mesh
So you’ve just adopted Kubernetes. Congratulations! But now what? One of the first observability tasks for any Kubernetes adopter is monitoring—at a minimum, you need to know when things go wrong so that you can quickly fix them.
Kubernetes observability is a very broad topic and there are many discussions online about the nuances of observability vs monitoring, distributed tracing vs logging, and so on. In this article we’re going to focus on a basic: getting “golden metrics” (or “golden signals”) from the applications running on your cluster, without changing any code. We’ll do this by installing a Linkerd, an open source, ultralight service mesh. Unlike most service meshes, Linkerd takes only minutes to install on a cluster and requires no configuration.
While simple, Linkerd contains a very powerful metrics pipeline. Once installed, it will automatically instrument and report success rates, traffic levels, and response latencies by observing the HTTP (or gRPC) and TCP communication to and from everything running on the cluster.
The metrics that Linkerd can automatically report for a service are often referred to the service’s golden metrics.
What are golden metrics and why are they important?
If you already know what golden metrics are, skip on ahead to the next section!
Golden metrics (or “golden signals”) are the top-line metrics that you need to have an idea of whether your application is up and running as expected. These metrics give you an at-a-glance signal about the health of a service, without needing to know what the service actually does.
In her great blog post on monitoring and observability, Cindy Sridharan states that “when not used to directly drive alerts, monitoring data should be optimized for providing a bird’s eye view of the overall health of a system.”
The Google SRE book defines the “golden metrics” as:
- Latency – A measure of how slow or fast the service is. It’s the time taken to service requests, typically measured in percentiles. A 99th percentile latency of 5ms means that 99% of requests are served in 5ms or less.
- Traffic – Gives you an idea of how busy or “in demand” a service is. Usually measured as the number of requests per second to the service.
- Errors – The number of requests that have failed. Commonly combined with overall traffic to generate a “success rate” – the ratio of successful requests to requests that encountered an error.
- Saturation – A measure of how loaded your system is, based on its primary constraints. If the system is memory-bound, this might be a measure of the percentage of the maximum memory currently being used.
By observing traffic to and from a service, Linkerd can trivially provide measurements of latency, traffic, and errors—which Linkerd, optimistically, provides in the form of a success rate. (The fourth metric, saturation, is often elided in monitoring discussions, as it requires knowledge of the internals of the service and typically tracks other metrics such as traffic and latency.)
Sometimes these metrics are also called the “RED” metrics for a service:
- Rate – the number of requests, per second, you services are serving.
- Errors – the number of failed requests per second.
- Duration – distributions of the amount of time each request takes.
Regardless of what you call them, the beauty of Linkerd is that it not only instruments the traffic to record these metrics, it aggregates and reports them so that we can easily consume them. (We’ll see how below.) This gives us the ability to monitor our application. Once we are able to monitor our application, we can be alerted when something’s wrong; study its performance over time; and measure and improve its reliability and performance.
Golden metrics: the easy way
Setup: Access your Kubernetes cluster and install the Linkerd CLI
We’ll assume you have a functioning Kubernetes cluster and a `kubectl` command that points to it. In this section, we’ll walk you through an abbreviated version of the Linkerd Getting Started guide to install Linkerd and a demo application (which is the application we’ll be getting golden metrics for) on this cluster.
First, install the Linkerd CLI:
curl -sL https://run.linkerd.io/install | sh
export PATH=$PATH:$HOME/.linkerd2/bin
(Alternatively, download it directly from the Linkerd releases page.)
Validate that your Kubernetes cluster is able to handle Linkerd; install Linkerd; and validate the installation:
linkerd check --pre
linkerd install | kubectl apply -f -
linkerd check
Finally, install the “Emojivoto” demo application, which is the application we want to get golden metrics for. If you look closely at the following command, you’ll see that we’re actually adding linkerd to the application (which we call “injecting”) and then deploying the application to Kubernetes. (If you’re curious about how this works, check out our documentation).
curl -sL https://run.linkerd.io/emojivoto.yml \
| linkerd inject - \
| kubectl apply -f -
And well… that’s actually it. That’s all you need to instrument your application and be able to access your golden metrics! Let’s take a look at them now.
Viewing metrics in Grafana
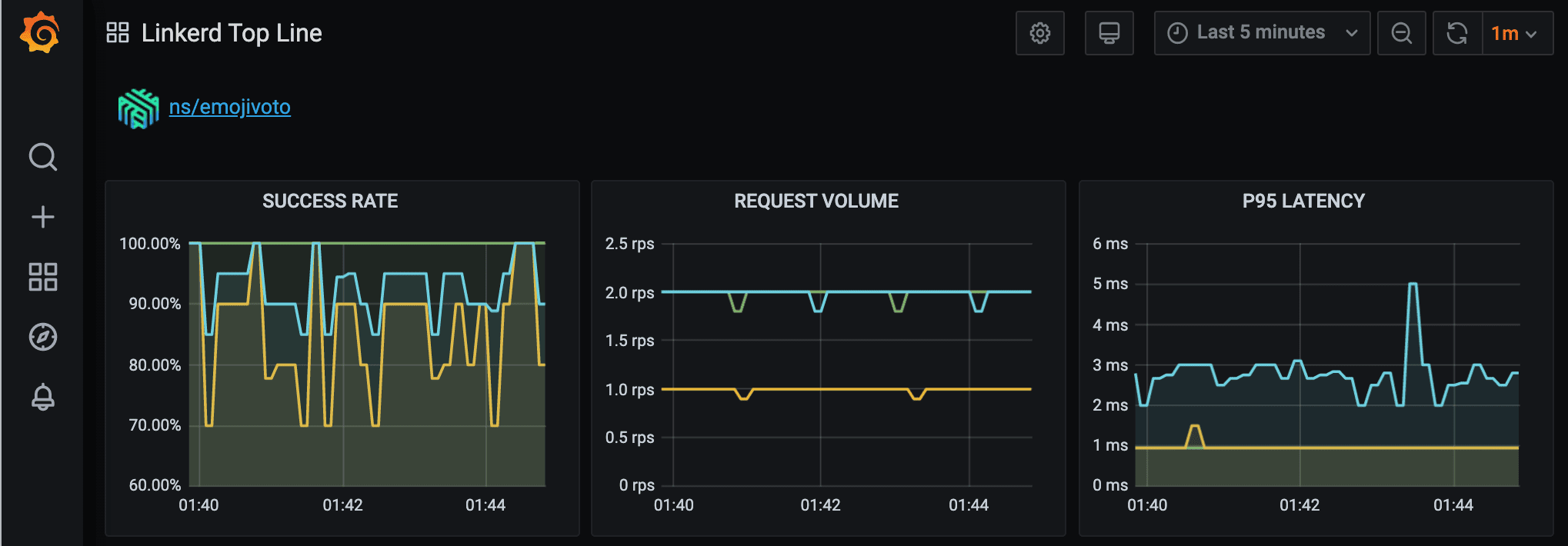
Want to see helpful charts and dashboards of all those sweet metrics? Not a problem! Run `linkerd dashboard –show grafana` and open the link that the command outputs. You’ll see Linkerd’s Top Line dashboard, containing overall and per-namespace breakdowns of the metrics it is collecting. Scroll down to our application’s namespace (ns/emojivoto) and observe the following graphs:
Viewing metrics via the Linkerd CLI
We can also view our application’s metrics using the `linkerd stat` command.

All of this data can also be found in Linkerd’s dashboard, which you can access by running `linkerd dashboard`:
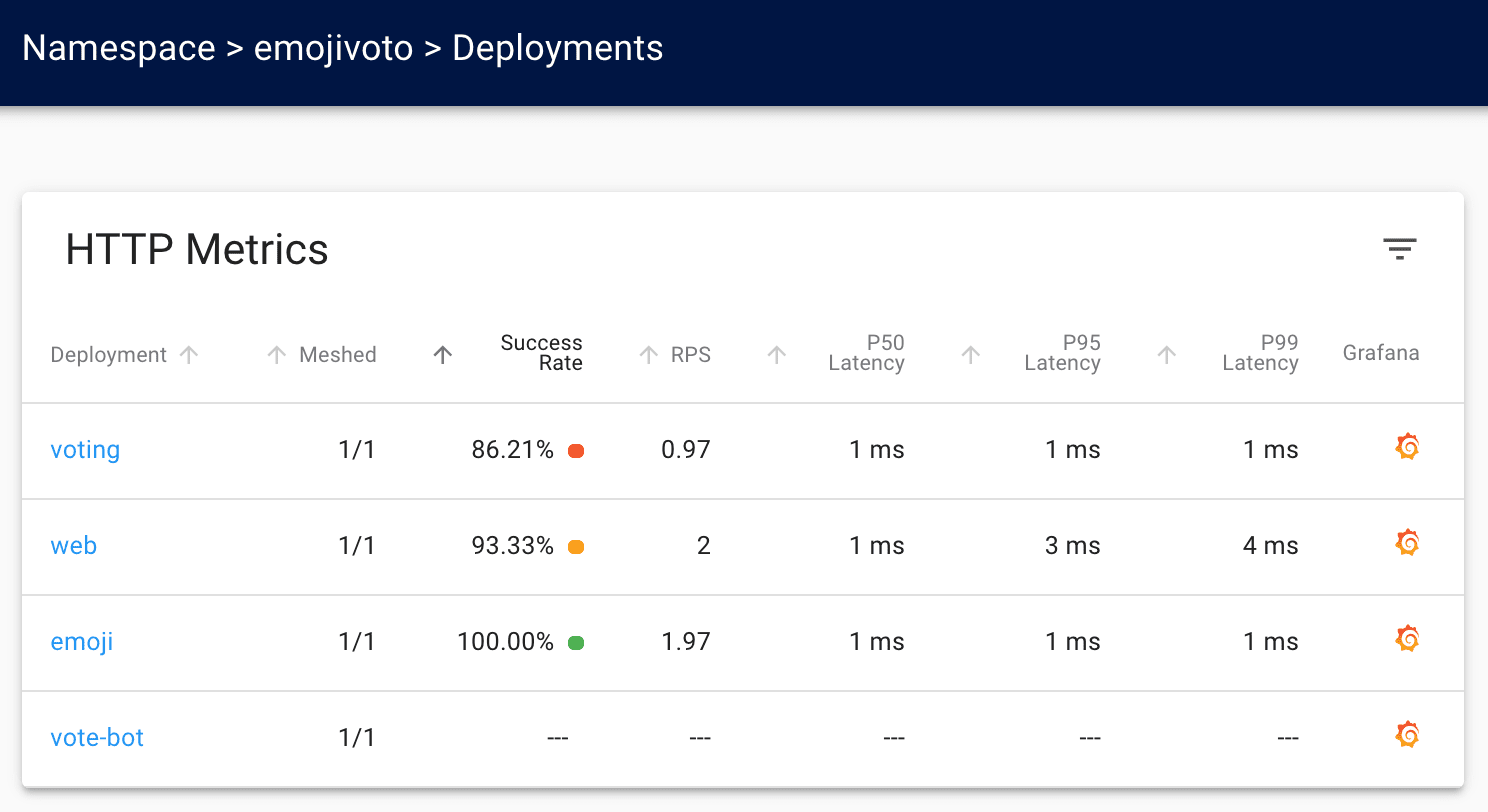
Looking at the Grafana graphs (or the Linkerd dashboard), you can immediately see that the “voting” service isn’t doing very well – its success rate is quite low! Adding golden metrics to our application has immediately allowed us to see that something might be wrong with our application.
Was it really that simple? The answer is yes! All we needed to do was install Linkerd and inject it into our application. Under the hood, when Linkerd is added to a service, it automatically instruments any HTTP and gRPC calls to and from the pods of the service. Since it understands these protocols, It can record the response class and latency of those calls and aggregate them, in this case into a small, internal instance of a time series database called Prometheus. When you view the golden metrics via Linkerd’s dashboard and CLI, Linkerd fetches them from this internal Prometheus instance, giving you all of those sweet metrics without any changes to your application code.
What else can Linkerd do?
We’ve seen how to use Linkerd to get our golden metrics, which is the first step towards getting observability of our system, i.e., a high level view of what’s going on in our complex application. But metrics are just the beginning. As you continue on your monitoring and observability journey, there are two other commonly used tools that you are bound to encounter: logs and distributed tracing.
Distributed tracing involves instrumenting your application such that the length of time a request spends inside a service is measured. Tracing is a great tool to use for debugging slow requests and figuring out which service is the bottleneck when our application uses many microservices that talk to each other. Linkerd can help with distributed tracing, though a service mesh can ultimately only do so much when it comes to distributed tracing.
Akin to distributed tracing, Linkerd also provides a powerful dynamic request tracing tool called tap. The tap command is akin to “tcpdump for microservices”: it allows you to see (a sample of) live requests to or from a particular service. Tap can be a powerful tool for debugging Kubernetes services in production.
Finally, application logs are, of course, one of the first things a developer might turn to if they suspect a specific process is out of whack. And when running a service mesh, it can sometimes be useful to see what is going on inside the mesh. While Linkerd can’t provide application logging for you, the `linkerd logs` command provides an easy way to at least see what’s going on inside Linkerd itself.
What’s next?
In this blog post we’ve covered how to easily get golden metrics for the applications and services running on your Kubernetes cluster. This is a solid first step in your observability journey. Of course, there’s a lot more to learn and implement before you are a certified Kubernetes observability expert! One particularly exciting observability topic these days is around SLOs, or “service level objectives”—don’t miss our guide on how to set up SLOs using Prometheus and Linkerd.
We hope the information in this blog post will help you get up and running with monitoring your Kubernetes services. Good luck in your journey!
Buoyant is the creator of Linkerd and of Buoyant Cloud, the fully automated, Linkerd-powered platform health dashboard for Kubernetes. Sign up for early access today!