Guest post originally published on Vectorized.io’s blog by Alexander Gallego, Founder and CEO at Vectorized.io
As I have previously observed, software does not run on category theory, it runs on superscalar CPUs with wide, multi-channel GB/s memory units and NVMe SSD access times in the order of 10-100’s of microseconds. The reason some software written a decade ago – on a different hardware platform – feels slow is because it fails to exploit the advances in modern hardware.
The new bottleneck in storage systems is the CPU. SSD devices are 100-1000x faster than spinning disks and are 10x cheaper today[1] than they were a decade ago, from $2,500 down to $200 per Terabyte. Networks have 100x higher throughput in public clouds from 1Gbps to 100Gbps.
Although computers did, in fact, get faster, single-core speeds remain roughly the same. The reason being that CPU frequency has a cubic dependency on power consumption, and we’ve hit a wall. Instruction level parallelism, prefetching, speculative execution, branch prediction, deep hierarchy of data caches and instruction caches, etc, have contributed to programs feeling faster when you interact with them, but in the datacenter, the material improvements have come from the rise in core count. While the instructions per clock are 3x higher than a decade ago, core count is up 20x.
This is all to say that the rise of readily available, many-core systems necessitates a different approach for building infrastructure. Case in point[9]: in order to take full advantage of 96 vCPUs on a i3en.metal on AWS, you’ll need to find a way to exploit sustained CPU clock speed of 3.1 GHz, 60 TB of total NVMe instance storage, 768 GiB of memory and NVMe devices capable of delivering up to 2 million random IOPS at 4 KB block sizes. This kind of beast necessitates a new kind of storage engine and threading model that leverages these hardware advances.
Redpanda – a Kafka-API compatible system for mission critical workloads[3] – addresses all of these issues. It uses a thread-per-core architecture with Structured Message Passing (SMP) to communicate between these pinned threads. Threading is a foundational decision for any application, whether you are using a thread-pool, pinned threads with a network of Single Producer Single Consumer SPSC[7] queues, or any other of the advanced Safe Memory Reclamation (SMR) techniques, threading is your ring-0, the true kernel of your application. It tells you what your sensitivity is for blocking – which for Redpanda is less than 500 microseconds – otherwise, Seastar’s[4] reactor will print a stack trace warning you of the blocking since it effectively injects latency on the network poller.
Once you have decided on your threading model, the next step is your memory model and ultimately, for storage engines, your buffer management. In this post, we’ll cover the perils of buffer management in a thread-per-core environment and describe iobuf, our solution for a 0-copy memory management in the world of Seastar.
Request Flow Architecture
As mentioned earlier, Redpanda uses a single pinned thread per core architecture to do everything. Network polling, submitting async IO to the kernel, reaping events, triggering timers, scheduling compute tasks, etc. Structurally, it means nothing can block for longer than 500 microseconds, or you’ll be introducing latency in other parts of your stack. This is an incredibly strict programming paradigm, but this opinionated idea forces a truly asynchronous system, whether you like it or not as the programmer.
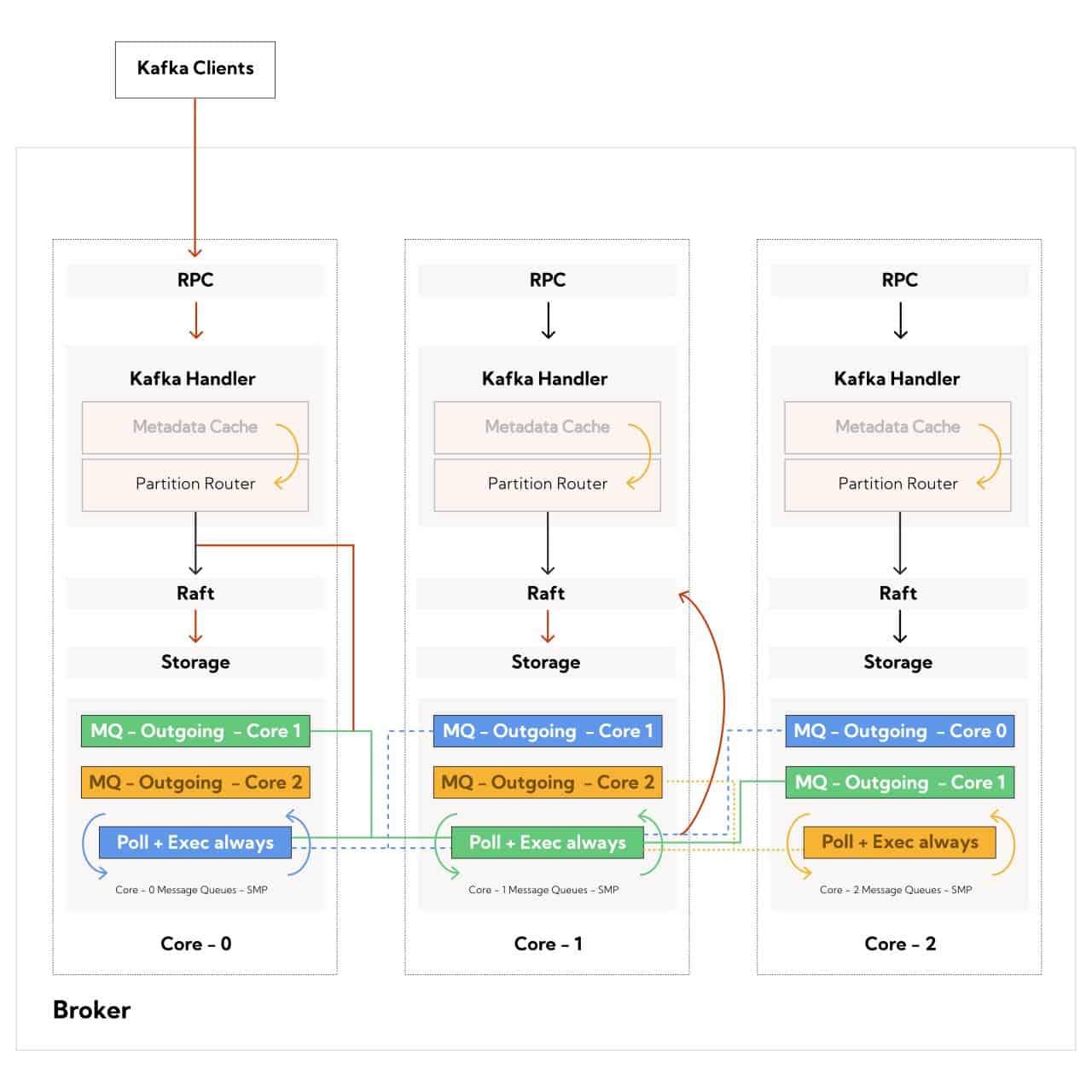
The challenge in a TpC (thread-per-core) architecture[8] is that all communication between cores is explicit. This muscles the programmer into implementing algorithms that favor core-locality (d-cache, i-cache) over the straightforward multi-threaded implementations via mutexes. This imperative has to be co-designed with the asynchronicity of a future<>-based implementation.
For our Kafka-API implementation as shown in Figure 1, we explicitly trade memory usage to reduce latency and increase throughput by materializing key components. The metadata Cache is materialized on every core since every request has to know if the partition exists, and that that particular machine is, in fact, the leader of the partition. The Partition Router maintains a map of which logical core actually owns the underlying Kafka partition on the machine. Other things like Access Control Lists (ACLs) are deferred until the request reaches the destination core since they can get unwieldy in memory footprint. We have no hard and fast rule of what we materialize on every core vs. what is deferred for the destination core, and it’s often a function of memory (smaller data structures are good candidates for broadcast), computation (how much time is spent deciding) and frequency of access (very likely operations tend to get materialized on every core).
One question remaining is how, exactly, does memory management work in a TpC architecture? How does data actually travel from L-core-0 to L-core-66 safely using a network of SPSC queues within a fully asynchronous execution model where things can suspend at any point in time?
struct iobuf { };
Redpanda’s 0-copy buffer management for TpC
To understand iobuf, we need to understand the actual memory constraints of Seastar, our TpC framework. During program bootstrap, Seastar allocates the full memory of the computer and splits it evenly across all the cores. It consults the hardware to understand what memory belongs to each particular core, reducing inter-core traffic to main memory.
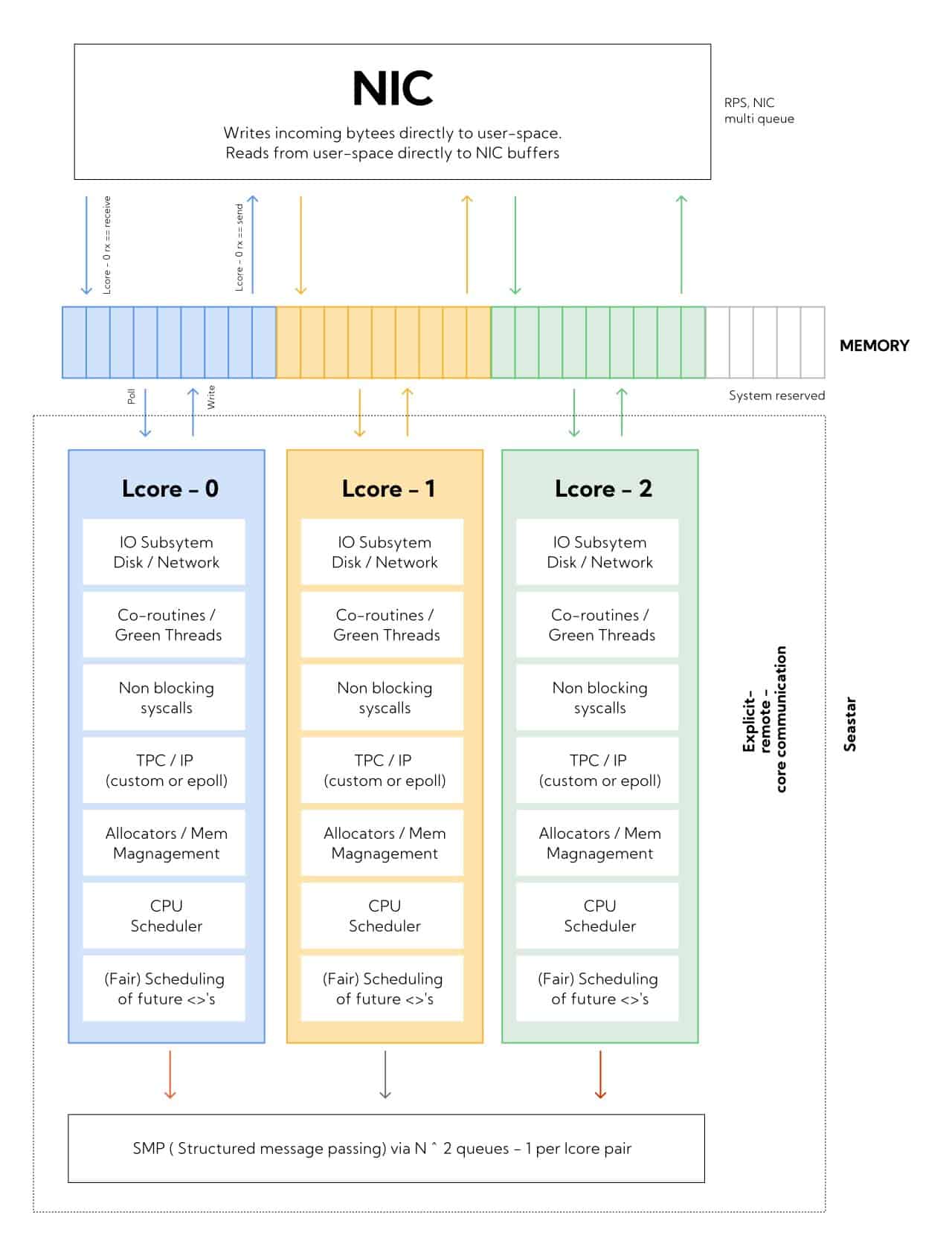
As Figure 2 suggests, memory allocated on core-0, must be deallocated on core-0. However, there is no way to guarantee that a Java or Go client connecting to Redpanda will actually communicate with the exact core that owns the data.
At its core, an iobuf is a ref-counted, fragmented-buffer-chain with deferred deletes that allows Redpanda to simply share a view of a remote core’s parsed messages as the fragments come in, without incurring a copy overhead.
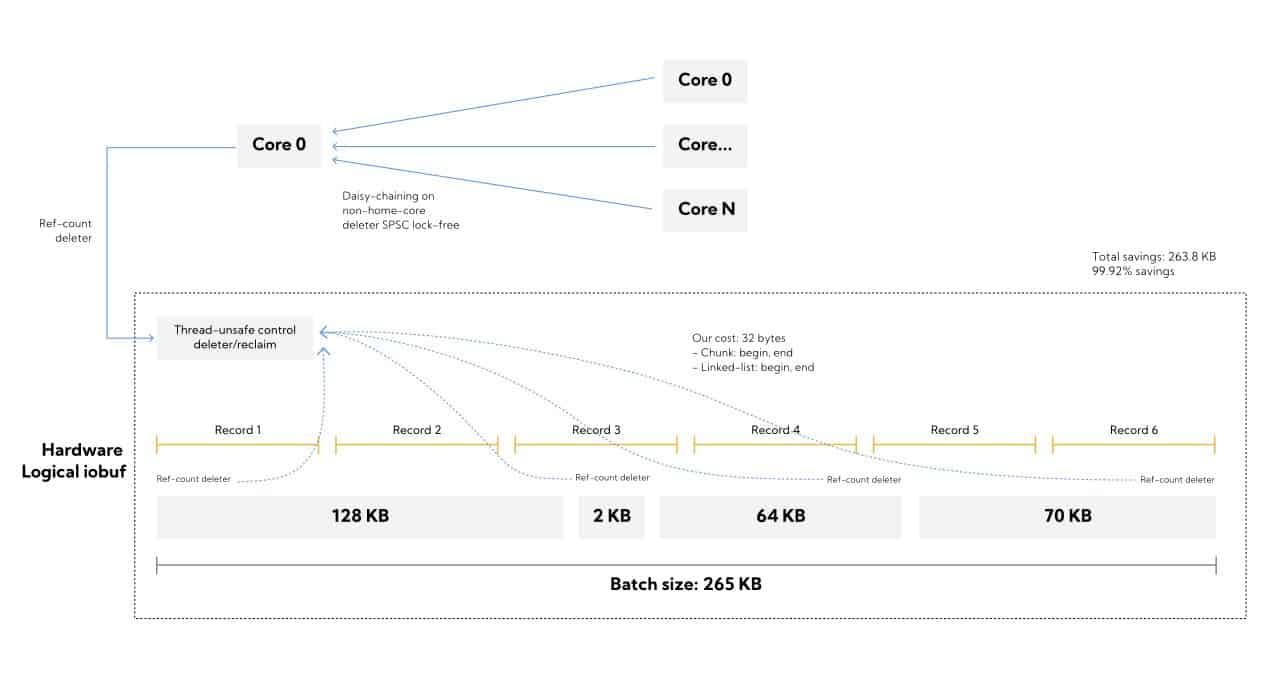
The fragmented buffers abstraction is not new. The linux kernel has sk_buff[5] and the freebsd kernel has an mbuf[6] which are roughly similar. The additional extension of an iobuf is that it works in the TCP model leveraging Seastar’s network of SPSC queues to have proper deletes in addition to being able to share sub-views arbitrarily, tailored for a storage-like workload.
Removing the C++ templates, allocators, pooling, pointer caching, etc, one could think of an iobuf as being equivalent to:
struct fragment {
void * data;
size_t ref_count;
size_t capacity;
size_t size;
fragment* next; // list
fragment* prev;
}
struct iobuf {
fragment* head;
};The origins of iobuf are rooted in one of our central product tenets for building a Kafka® replacement for mission critical systems – giving users 10x lower tail latencies for most workloads. Aside from a thread-per-core architecture, the memory management would have been our second bottleneck if not designed from the ground up for latency. On long running storage systems, memory fragmentation is a real problem, and one that is eventually either met with a proper solution (iobuf), stalls or an OOM.
Like its predecessors skbuff and mbuff, iobuf allows us to optimize and train our memory allocator with predictable memory sizes. Here is our iobuf allocation table logic:
struct io_allocation_size {
static constexpr size_t max_chunk_size = 128 * 1024;
static constexpr size_t default_chunk_size = 512;
// >>> x=512
// >>> while x < int((1024*128)):
// ... print(x)
// ... x=int(((x*3)+1)/2)
// ... x=int(min(1024*128,x))
// print(1024*128)
static constexpr std::array<uint32_t, 15> alloc_table =
// computed from a python script above
{{512,
768,
1152,
1728,
2592,
3888,
5832,
8748,
13122,
19683,
29525,
44288,
66432,
99648,
131072}};
static size_t next_allocation_size(size_t data_size);
}; Predictability, memory pooling, fixed sizes, size capping, fragmented traversal, etc, are all known techniques to reduce latency. Asking for contiguous and variably sized memory could cause the allocator to compact all of the arenas and reshuffle a lot of bytes for what could be a short-lived request, not only injecting latency on the request path, but for the entire system since we have exactly one thread performing all operations.
Hardware is the platform. When we ask the network layer to give us exactly 11225 bytes in contiguous memory, we are simply asking the allocator to linearize an empty buffer of that exact size and for the network layer to copy bytes as the fragments come from the hardware into the destination buffer. There is ultimately no free lunch when it comes to trying to squeeze every single ounce of performance of your hardware and often it requires re-architecting from zero.
If you made it this far, I encourage you to sign up for our Community Slack (here!) and ask us questions directly or engage with us on twitter via @vectorizedio or personally at @emaxerrno
[1] Cost of SSD over the last decade – Blackblaze stats – https://www.backblaze.com/blog/hard-drive-cost-per-gigabyte/
[2] Cliff Click – crash course on modern hardware – https://www.youtube.com/watch?v=5ZOuCuGrw48
[3] https://vectorized.io/redpanda
[4] http://seastar.io
[5] skbuff – https://lwn.net/Kernel/LDD2/ch14.lwn
[6] mbuf – https://www.freebsd.org/cgi/man.cgi?query=mbuf
[7] SPSC queue – http://www.1024cores.net/home/lock-free-algorithms/queues
[8] Thread Per Core Architecture – https://helda.helsinki.fi//bitstream/handle/10138/313642/tpc_ancs19.pdf?sequence=1
[9] i3en.metal instances on AWS – https://aws.amazon.com/ec2/instance-types/i3en/