
Guest post originally published on CTO.ai’s blog by Benjamin Slater, Director of Technology and Tristan Pollock, Head of Community at CTO.ai
One of the latest additions to the technical jargon soup is Kubernetes (k8s).
It gets thrown around quite a bit, “Kubernetes this! Kubernetes that! Do you even deploy clusters?”
So what does Kubernetes actually mean and how should your engineering team be using it in your day-to-day software development job?*
*Spoiler Alert: You might not directly interface with k8s, but your DevOps team probably is, or at least they should be thinking about it if you are not a fan of the 3pm War Room deployment every Monday.
First, Kubernetes is a very unique word. Where does it come from, you might be asking. Often mispronounced, the real backstory of what Kubernetes means starts with a translation. The name originates from Greek, meaning helmsman (you can see that referenced in the logo) or pilot. Google Translate gives the modern Greek pronunciation, but Reddit explains the common pronunciation as more similar to ancient Greek. Either way, Flavor Flav puts his own spin on it here.
Okay, now on to the technical stuff. First, let’s define Kubernetes.
Kubernetes is a DevOps software development tool built and supported by Google to enable teams to simplify the management of deploying updates and services in a distributed system.
Phew, that is a lot of techie words, but to simplify that: Gone are the days for having to have one giant compute machine on Amazon to support all your running containers. (Or worse, multiple identical giant compute machines holding everything imaginable because you needed more services that help user John_63_xyz to see his dashboard and upload his profile photo… okay, you get the point.)
Next, containers. A container is a standardized unit of software. If you are hung-up on what containers are, I strongly encourage you to give this article by Docker a read and then come back. You can also peek the graphic below.

The advantages of running containerized code are innumerable and it is well established as an industry best practice, but in short: Containerization allows developers to create and deploy applications faster and more securely than before.
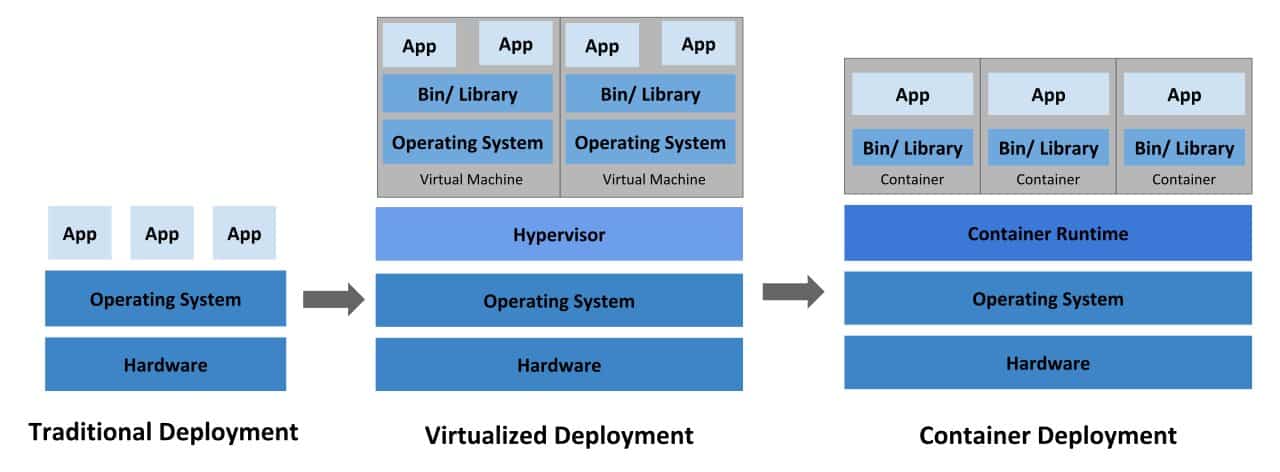
With traditional methods, code is developed into a specific computing environment that when transferred to a new location often results in bugs and errors.
Containerization also reduces wasted resources because each container only holds the application and related binaries or libraries. Simply by allowing more containers in the environment without the need for more servers, containerization increases scalability up to 100 times that of traditional VM environments.
Getting back to Kubernetes and what it is, it is a tool used for container orchestration. Meaning that it is one point of reference that you can “talk to” to access ANY of the services that you have running on your Kubernetes cluster. Even if those services are across different machines. Pretty great, yeah?
So What Does Kubernetes Do Exactly?
EVERYTHING… for deployment and maintenance needs. Historically (not speaking ftp), the deployment process looked something like this:
- Code review is approved and changes are merged into master
- ssh into your Amazon EC2 instance holding the git repo for your application
- cd into your project directory
- ^C to stop application
- git pull origin master
- <application start command>
- Hope it works out 🤞
Over the years, the process has improved with Docker and docker-compose to run images of the application in containers instead of the application on bare metal, but it still follows the same steps as above.
Alternatively, if using Kubernetes, you can run kubectl apply -f {deployment yaml} to directly target ALL services on ALL machines of the specified type in your deployment yaml file and apply the new image(s) from your local machine (depending on the privileges you setup for the connection to your cluster).
On top of it being one line, it applies the update in a rollout fashion, meaning that it shuts down the services one at a time as it applies the new changes.
What if I Need to Add New Services Not Defined in the Cluster?
Simple, create a new deployment yaml file for the new service and run the apply command.
What if I Need More Than One of the Same Service?
Even easier, each service (called a deployment) has a number of pods representing the number of “service instances” that are running that application. Just set that value to be greater than 1, or even better set the “autoscaling” limit to be the maximum number of service instances you want running at a time and let Kubernetes scale the number of instances up and down based on traffic.
Is There a Limit on the Number of Services That I Can Run?
Yes and no. Your Kubernetes cluster manages which machines (called nodes) the new pods get deployed to (and yes you can pair up applications that need to be together), which isn’t a problem until there isn’t enough space on any of the nodes you have allocated to your cluster. You can correct this by adding more nodes, so the sky and your wallet are the limit.
How Do I Setup a Kubernetes Cluster for My Application?
There are a number of ways for setting up a Kubernetes cluster for your application ranging from bare metal to managed cloud provider solutions. In this article I’m going to point you in the right direction for setting up a managed solution in each of the major cloud providers as well as how to use The Ops Platform to make your life simpler, observable, and streamlined like a Control Plane.
Amazon Web Services (AWS) EKS
According to AWS’s documentation, there are 2 ways to create a new EKS managed Kubernetes cluster. The first being an officially supported CLI developed by Weaveworks called eksctl. With eksctl, you can spin up a new managed cluster with reasonable defaults just by running eksctl create cluster.
Pretty easy right? You can also customize the settings on the cluster via the command line or a configuration yaml if you know what you are doing, which adds some complexity. From their website it looks like this tool does the heavy lifting from the setup side, but doesn’t provide any abstractions over kubectl for pod or deployment maintenance.
$ eksctl create cluster
[ℹ] using region us-west-2
[ℹ] setting availability zones to [us-west-2a us-west-2c us-west-2b]
[ℹ] subnets for us-west-2a - public:192.168.0.0/19 private:192.168.96.0/19
[ℹ] subnets for us-west-2c - public:192.168.32.0/19 private:192.168.128.0/19
[ℹ] subnets for us-west-2b - public:192.168.64.0/19 private:192.168.160.0/19
[ℹ] nodegroup "ng-98b3b83a" will use "ami-05ecac759c81e0b0c" [AmazonLinux2/1.11]
[ℹ] creating EKS cluster "floral-unicorn-1540567338" in "us-west-2" region
[ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial nodegroup
[ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-west-2 --cluster=floral-unicorn-1540567338'
[ℹ] 2 sequential tasks: { create cluster control plane "floral-unicorn-1540567338", create nodegroup "ng-98b3b83a" }
[ℹ] building cluster stack "eksctl-floral-unicorn-1540567338-cluster"
[ℹ] deploying stack "eksctl-floral-unicorn-1540567338-cluster"
[ℹ] building nodegroup stack "eksctl-floral-unicorn-1540567338-nodegroup-ng-98b3b83a"
[ℹ] --nodes-min=2 was set automatically for nodegroup ng-98b3b83a
[ℹ] --nodes-max=2 was set automatically for nodegroup ng-98b3b83a
[ℹ] deploying stack "eksctl-floral-unicorn-1540567338-nodegroup-ng-98b3b83a"
[✔] all EKS cluster resource for "floral-unicorn-1540567338" had been created
[✔] saved kubeconfig as "~/.kube/config"
[ℹ] adding role "arn:aws:iam::376248598259:role/eksctl-ridiculous-sculpture-15547-NodeInstanceRole-1F3IHNVD03Z74" to auth ConfigMap
[ℹ] nodegroup "ng-98b3b83a" has 1 node(s)
[ℹ] node "ip-192-168-64-220.us-west-2.compute.internal" is not ready
[ℹ] waiting for at least 2 node(s) to become ready in "ng-98b3b83a"
[ℹ] nodegroup "ng-98b3b83a" has 2 node(s)
[ℹ] node "ip-192-168-64-220.us-west-2.compute.internal" is ready
[ℹ] node "ip-192-168-8-135.us-west-2.compute.internal" is ready
[ℹ] kubectl command should work with "~/.kube/config", try 'kubectl get nodes'
[✔] EKS cluster "floral-unicorn-1540567338" in "us-west-2" region is ready
*Pictured above: Example command and outputs. Taken from https://eksctl.io
Alternatively, you can go through the AWS Management Console or AWS CloudFormation and set it up from there but you then have to be exposed to a lot more technical depth for setting up the cluster VPC, installing and setting up kubectl, setting up the cluster configs so that you can reach it and nodes communicate properly, et cetera, et cetera. There is nothing wrong with taking that path, and if you are a tried and true AWS console user, maybe you take joy in that, but for the rest of us, why bother?
Google Cloud Provider (GCP) GKE
Similar to AWS, Google Cloud offers 2 paths to get up and running with a new GKE managed Kubernetes cluster, a quick start path, using an online console and a full install guided path. Both paths are valid, but highly technical.
They will get you there step by step but you might want to dip into the official Kubernetes docs to fully understand the components that you are putting in place in the walkthrough.
gcloud beta container clusters create cluster-name \\
--zone compute-zone \\
--release-channel channel
*Pictured above: Example command for setting up a new cluster through Google Cloud’s CLI.
Microsoft Azure (AKS)
Following the same pattern, Azure also has 2 paths for setting up a new AKS managed Kubernetes cluster. This time it is a quickstart guide followed by a full fledged tutorial that walks you through testing your containerized application all the way up to scaling the application in your Kubernetes cluster.
Similar to GKE, Kubernetes is less abstracted and the technical understanding is left up to the user.
az group create --name myResourceGroup --location eastus
az aks create --resource-group myResourceGroup --name myAKSCluster --node-count 1 --enable-addons monitoring --generate-ssh-keys
*Pictured above: Example 2 step process to create a new cluster through Azure’s online CLI.
The Ops Platform
On The Ops Platform, we currently support setting up and tearing down managed Kubernetes clusters on AWS (EKS) and GCP (GKE). Support for Azure is planned and will be coming in the not too distant future.
To be able to achieve this we have 2 open source Ops (or automations), an eks Op and a gke Op that can be run from both the terminal and Slack. They provide you with a guided experience by asking you questions about how you want your cluster to be setup, reducing the amount of technical knowledge required. The objective is to make your life easier and level up your team’s productivity, while still providing you with some of the most powerful tools.
To run the eks or gke Op in the CLI, you need to first have The Ops CLI installed (accessible via the Dashboard on our website https://cto.ai in the signed in view) and then type:
ops run @cto.ai/eks
OR
ops run @cto.ai/gke
Depending on your Cloud Provider of choice.
Alternatively you can run these in Slack, after installing our Slack App (also found on the signed in Dashboard) using:
/ops run cto.ai/eks
OR
/ops run cto.ai/gke
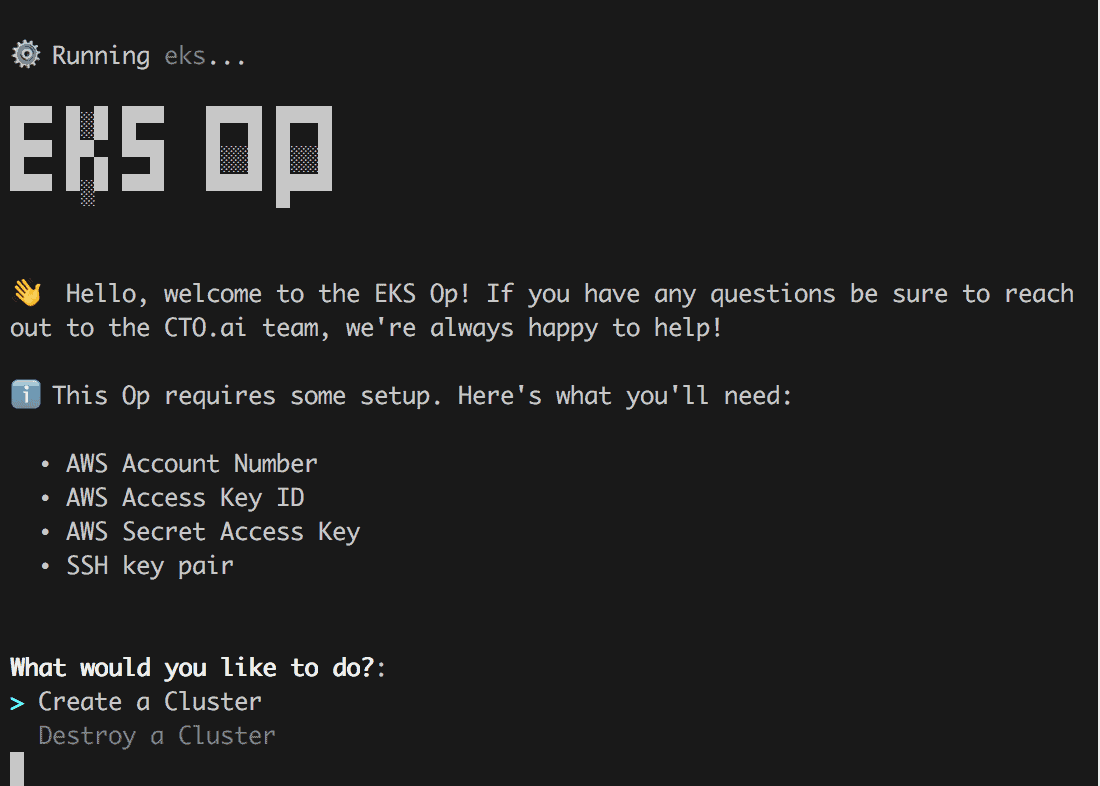
After running the Op, you are greeted with friendly message and a heads up as to pieces that you need to have available (either in your local configs or in the secret store registered to your Ops Team).
In the case of the eks Op, you need the following to be able to connect to your AWS account to create or destroy a Kubernetes cluster.
- AWS Account Number
- AWS Access Key Id
- AWS Secret Access Key
- SSH key pair
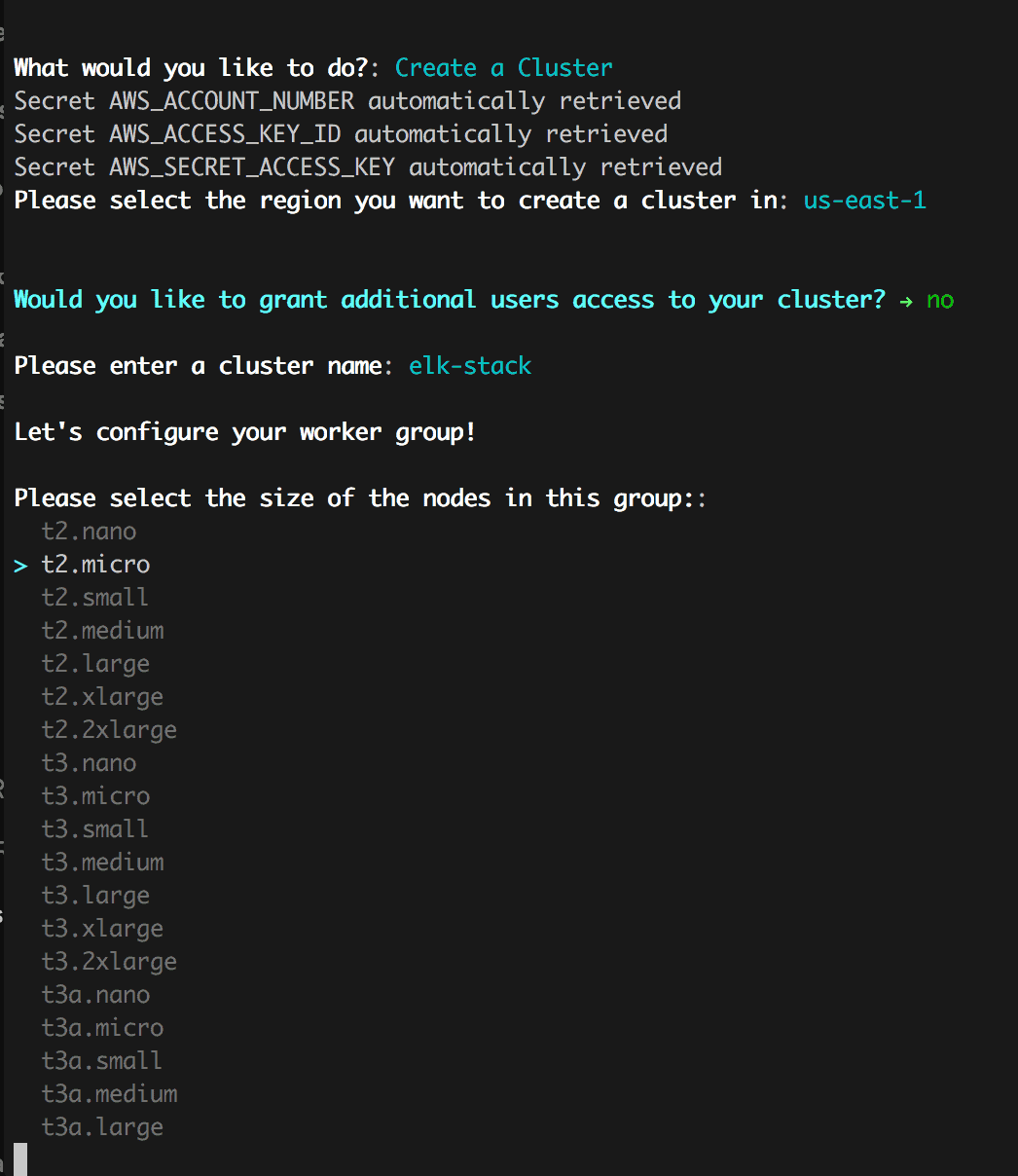
After selecting “Create a Cluster” the Op will fetch the necessary configs if they are available or ask for them via the secret interface and then follow up with questions regarding how you want your cluster setup including:
- the name of your cluster,
- region,
- machine sizes,
- and autoscaling settings.
This is an improved experience, because you now longer need to go back to the created cluster to “add-on” the features that should have been available up front.
In addition, we also package in setting up monitoring and logging, as well as specifying users that you want to have access to your cluster.
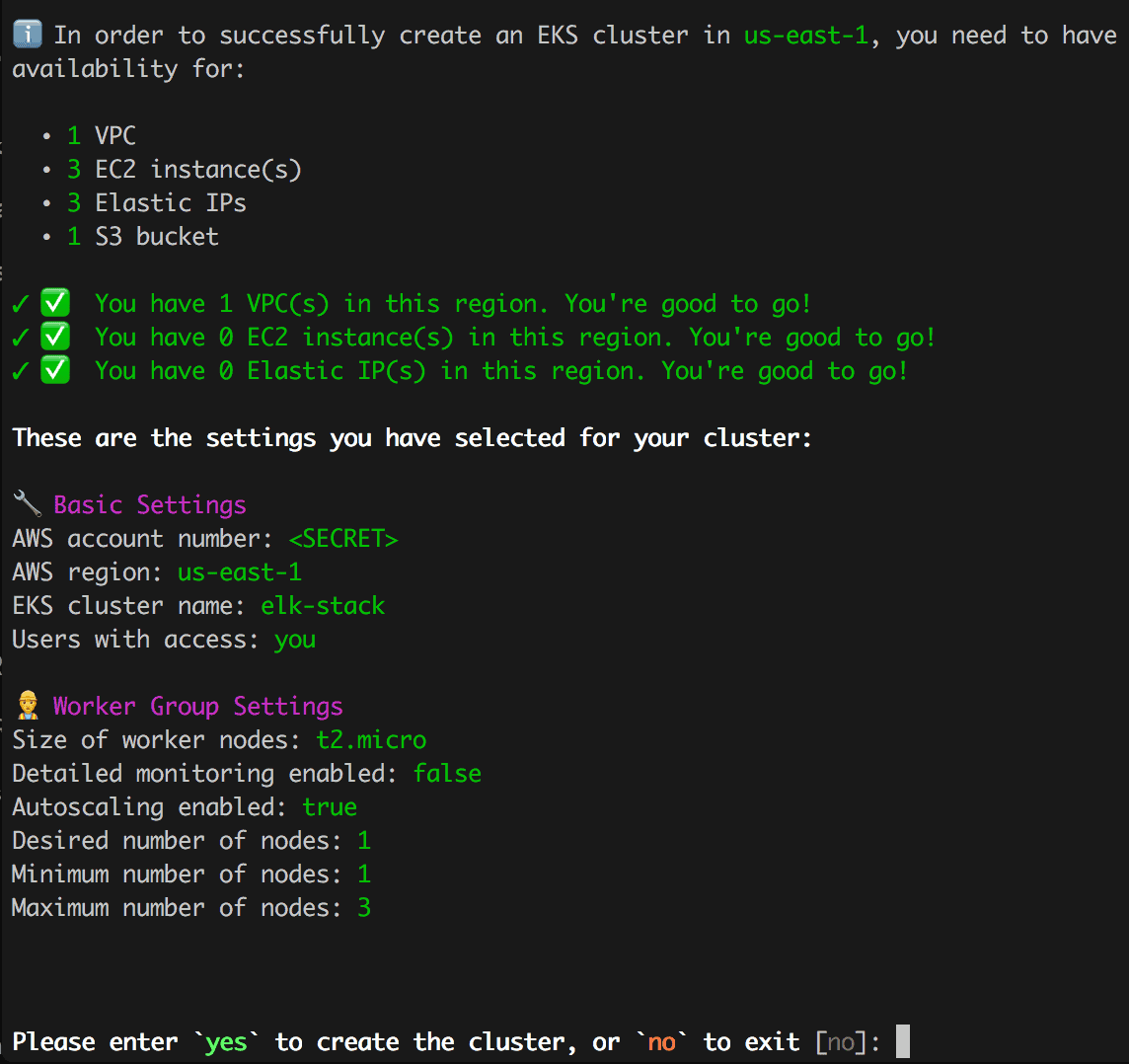
Before sending you off to the races and spinning up the new cluster, we provide a detailed printout to show what is being setup and giving you the option to continue or not.
Worst case if you are unhappy with you cluster, or don’t want to use it anymore, you can use the same Op to destroy it and start again or create something at a later date.
The gke Op provides a very similar experience, so I encourage you to try it on your own! Get hacking!
Maintaining Your Kubernetes Cluster in Slack
Great, you now have a new Kubernetes cluster in one of the top cloud service providers, so how do you maintain it and check that all your pods are up and running happily?
Easy, Kubernetes provides you with some tools like its Kubernetes dashboard to see all your pods, view your configs and secrets, and apply updates.
Alternatively, if you created your cluster using our eks Op or gke Op, you can use our **k8s Op** to view and maintain your Op in the CLI or Slack.
To run the Op in Slack, type in:
/ops run cto.ai/k8s
This can be used on any channel (if you are running it from a private channel, be sure to invite the bot user @invite cto.ai).

The k8s Op allows you to:
- Configure your cluster (create Kubernetes config file in your secrets).
- List out the cluster resources: deployments, pods, etc.
- Install useful k8s tools such as NGINX ingress (allow external connections) or grafana (provide observability performance metrics dashboard).
- Deploy new or update existing applications in your cluster.
For additional detail, check out the registry page for the Op with additional content and videos to better represent the features available.
What’s Next?
I hope that this post provides you with enough of an understanding of Kubernetes to help you get started with it.
If there is enough interest in this post (let me know on Twitter if it was helpful), we will be sure to publish follow ups showing new extensions to make Kubernetes work and managment even easier and provide more details into how you can eke out more power from this tool.
You can also join our Slack Community to get help from the CTO.ai team and bounce ideas off other DevOps enthusiasts.
Also, some quick resources:
- Browse our Docs to better understand The Ops Platform.
- Get Started running these Ops or build your own based on their source code.