



Guest post originally published on the Bouyant blog by Andrew Seigner
This post is a writeup of a talk Andrew gave at KubeCon EU 2020.
Introduction
In mid-2019, the Linkerd project’s continuous integration (CI) took 45 minutes, all tests were serialized on a single Kubernetes cluster, and multi-hour backups were common. A migration onto one-off Kubernetes in Docker (kind) clusters and GitHub Actions got CI below 10 minutes, and made it parallelizable.
This post will detail Linkerd’s CI journey from a single, persistent Kubernetes cluster to theoretically unlimited one-off kind clusters. This journey includes a few detours on what patterns and tools worked well (and not so well) for Linkerd’s use case.
What is Linkerd?
While the goal of this article is to detail an end user story of how to efficiently test Kubernetes applications in CI, some background on Linkerd is helpful. Linkerd is an open source service mesh, and a CNCF member project. To learn more about what a service mesh is, check out The Service Mesh: What Every Software Engineer Needs to Know about the World’s Most Over-Hyped Technology. For the purposes of this post, it’s important to be aware of a few simple facts about Linkerd:
- It’s written in Rust, Go, and Javascript.
- It runs in Kubernetes, as multiple deployments.
- It manages all traffic between your services, via proxies injected into your pods.
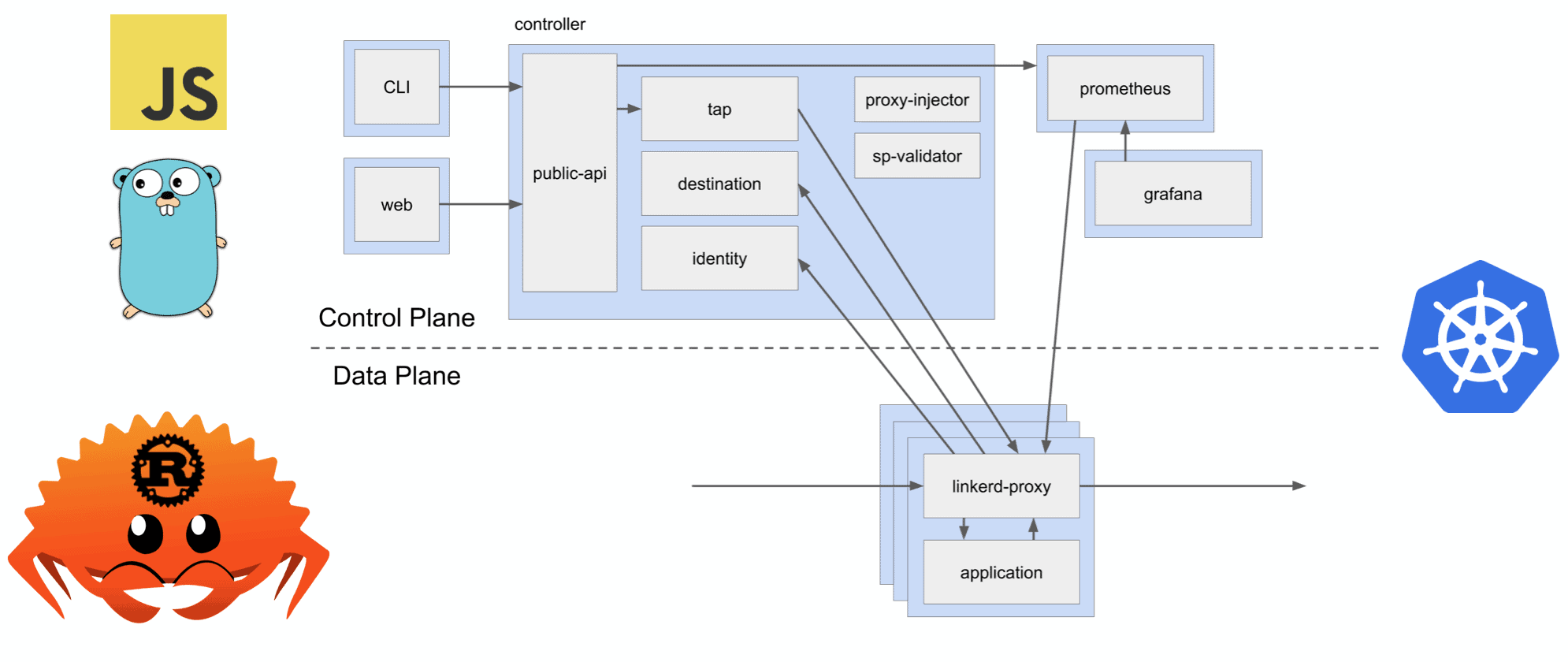
Linkerd Architecture
Testing Linkerd
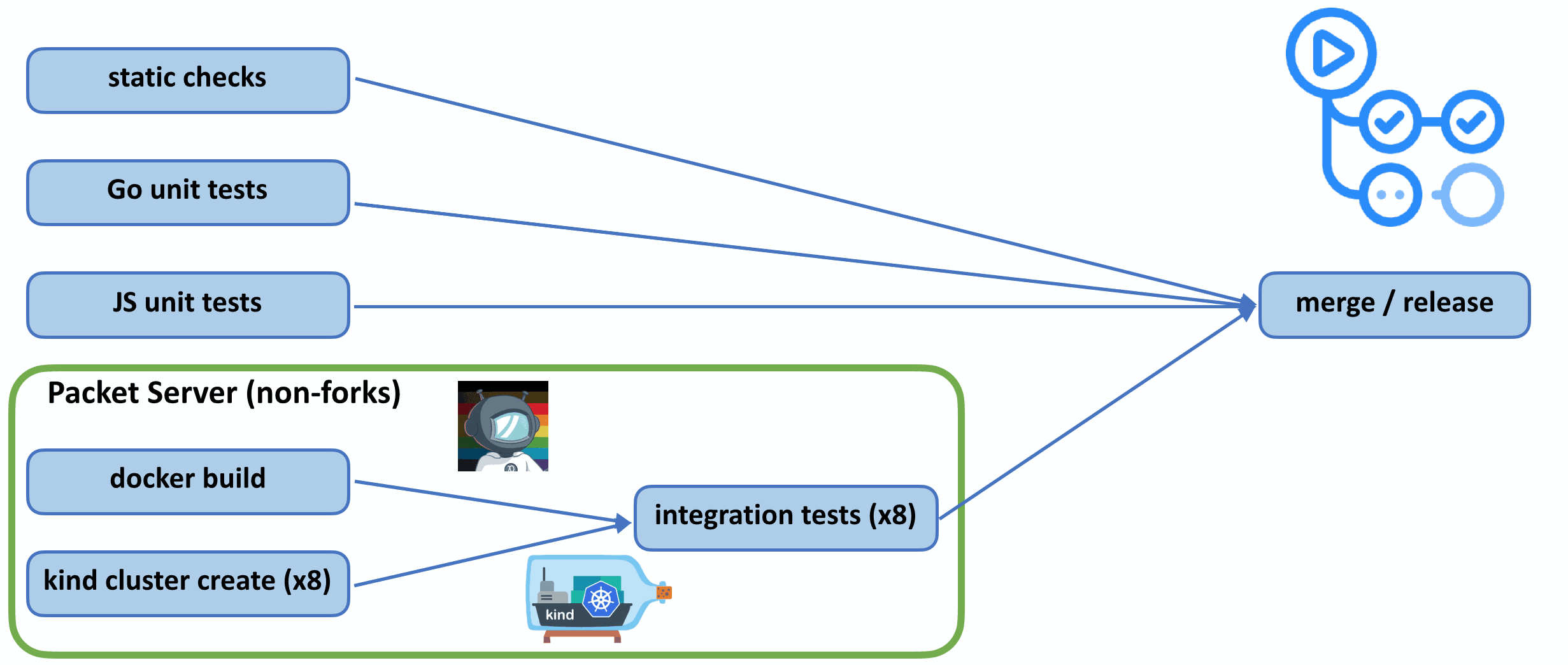
Given that Linkerd is responsible for managing all the traffic in your Kubernetes cluster, it’s critical for Linkerd to be correct and performant. To help ensure this, our CI includes a battery of static, unit, and integration tests, across Rust, Go, and JavaScript. This post primarily focuses on integration tests. We’re going to cover three iterations of these tests.
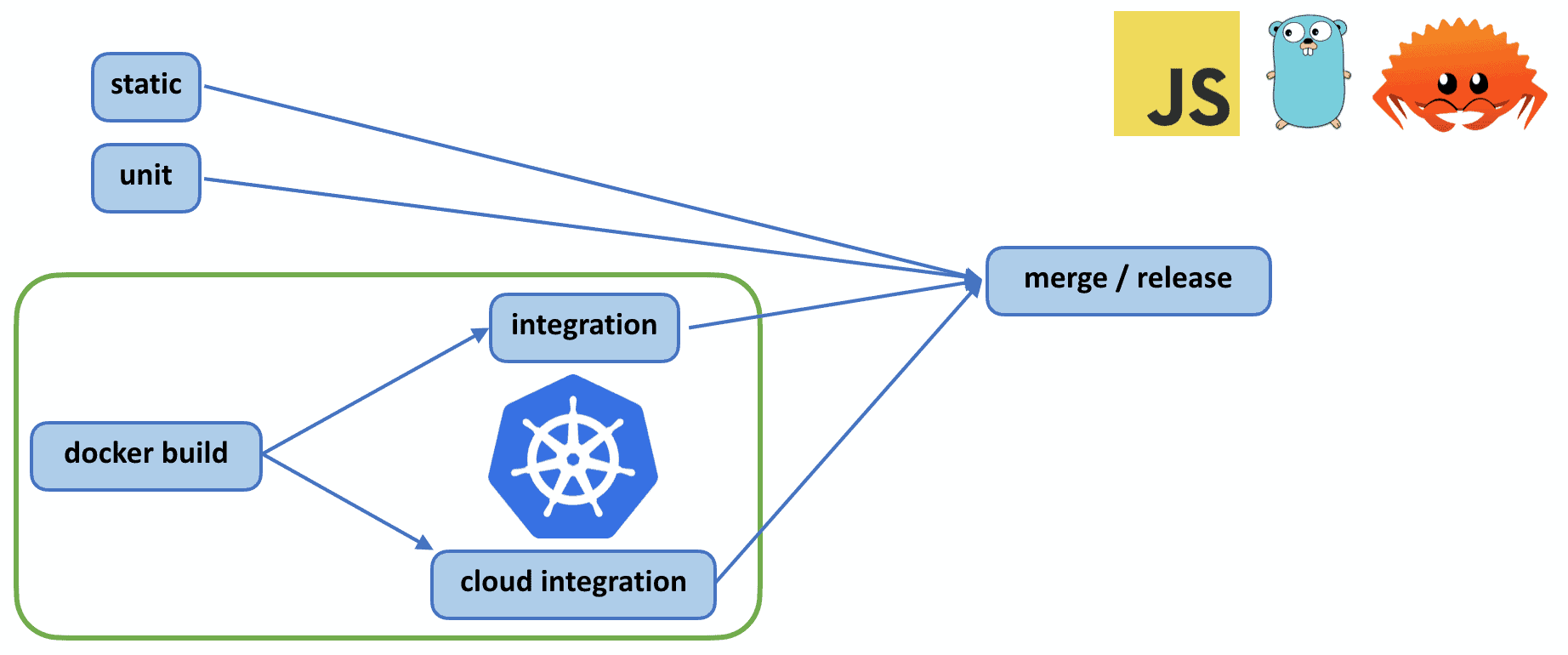
Testing Linkerd. Integration tests can be seen in the green box in the lower left.
Take 1: Running CI on GKE + Travis
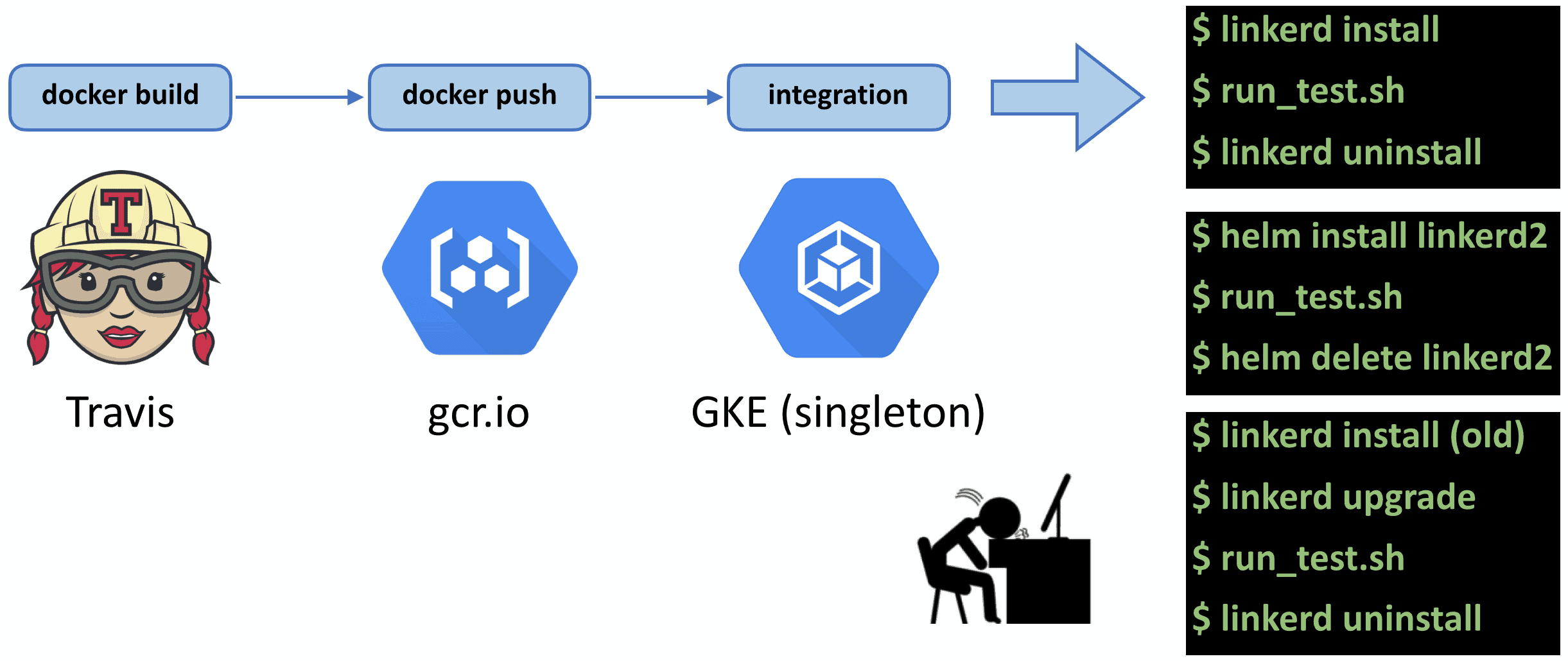
In mid-2019, Linkerd’s integration tests were run as jobs on Travis. Each job would build Linkerd Docker images, push them to gcr.io, and execute the integration tests on a single GKE cluster. Because it was a single Kubernetes cluster, we had to ensure each integration test cleaned up after itself by uninstalling Linkerd. Over time we needed to test installing Linkerd in different configurations. With Helm, for example, or via an upgrade path. This meant we were now installing Linkerd, running integration tests, and uninstalling Linkerd five times per CI run, in series. This whole process took about 45 minutes. Compound this with multiple pull requests (PRs) coming in at the same time, and multi-hour backups become common. It was at this point we took the nuclear option of disabling integration tests for PRs, we would only run them at merge time. Of course the moment we did this, our main branch began consistently failing integration tests, as failures were never caught until merge time.
Prioritized CI Requirements
At this point we realized we needed to step back and reevaluate our life choices around testing Linkerd. We came up with this list of prioritized requirements:
Requirement 1: Reproducible build and test
Linkerd’s integration test suite involves installing lots of resources on a Kubernetes cluster and validating traffic is flowing correctly. If we observed a test failure in CI, it was a top priority to ensure we could easily reproduce that failure both in CI and in local development.
Requirement 2: UI to browse build and test history
A UI to browse test history seems obvious for a CI system, but as we gathered requirements we were not taking anything for granted. We considered other ways to view build and test history, including background jobs and scripts that could email status or post GitHub comments to PRs. Ultimately we knew we needed an easy way to share links of test failures, where we could ping each other with a URL pointing to a specific line in a specific integration test failure.
Requirement 3: GitHub/PR integration
Also seemingly obvious in hindsight, we needed integration with our current PR system, GitHub. We had previously experimented with building these integrations ourselves, but were hopeful we could find something that worked out of the box rather than give ourselves more maintenance work.
Requirement 4: Hermetically sealed build and test
Many of Linkerd’s PRs come from the community, often from folks we’ve never worked with before. We wanted to ensure our tests were run in an as isolated environment as possible, as we were running untrusted code on hardware we were paying for and maintaining. We also wanted this process to happen without requiring a maintainer to spot-check every PR prior to running tests.
Requirement 5: Fast
Turnaround time on tests is always critical for developer productivity. Sometimes it takes five tries or more to fix a test. If each of those test runs takes an hour, you’ve lost nearly a day. This requirement translated into a plan to avoid pushing Docker images across the internet, enabling incremental rebuilds, and building Linkerd on remote machines if possible.
Requirement 6: Cheap or free
Being an open source project, we wanted to satisfy all the above requirements with little to no budget.
Requirement 7: OSS
Being open source maintainers ourselves, we always prefer to use open tools. Note, however, that this is our last requirement. We’d use open source where we could, but would not automatically discount a closed source tool if it satisfied all the other requirements.
CI Tech Evaluation
With the prioritized requirements in mind, we set about evaluating any tools we could find in this space:
k8s Distributions: kind, k3d, k3s, GKE, AKS, EKS, DigitalOcean K8s
Compute: Packet
Job Management: GitHub Actions, Prow, Travis, CircleCI, Azure Pipelines, Jenkins X, Gitlab CI, garden.io
Release/CD: Kubernetes Release, werf.io
We built proof of concepts to varying degrees with all these tools. At the time, we didn’t know if we would select one or five of them and preferred not to discount anything. (Note to any authors of tools we did not select: please know it’s not a knock against any of your works, and that our choice of tech was heavily dependent on our use case, which included the prioritized requirements listed above, our limited time and budget, and our own familiarity with existing tools.)
Near miss: Prow
With that in mind, I’d like to speak about one tool we really like but ultimately did not select: Prow.
Prow is a powerful Kubernetes-based CI/CD system. It is maintained by the Kubernetes community and is used to test Kubernetes itself, via thousands of jobs per day. This was compelling for us. If the tool was good enough for Kubernetes, it could definitely handle Linkerd.
We built an end-to-end proof of concept with Prow with all Linkerd Docker builds and integration tests running on a Prow cluster. Ultimately, we went in a different direction due to concerns around ongoing maintenance and support. Prow is very powerful but, like Kubernetes and most production systems, requires ongoing maintenance to ensure a healthy state. Our CI system is important to us, but we wanted something that could continue running with little to no attention from our small development team. Prow does have a sweet dashboard though:

In the end we selected three tools from our tech evaluation: kind (Kubernetes in Docker), Packet, and GitHub Actions.

kind
kind (Kubernetes in Docker) was the first tool we selected. It allows you to boot a Kubernetes cluster in a Docker container in about 30 seconds. This satisfied a number of our requirements. Most importantly, kind is a tool that can easily be scripted and run locally as well as in CI. This meant we could run integration tests on our development machines the same way our CI system would. It provides a self-contained Kubernetes cluster, which we could throw away after each test. It’s also very fast to spin up and delete, and it allows us to run Kubernetes wherever we are building our Docker images. No more pushing images across the internet. Also a huge bonus: it’s a core piece of technology for testing the Kubernetes project itself, and it’s open source! Even before we had selected other tools, we knew we wanted to build our CI system around kind.
Packet
Packet, who provides high performance bare metal servers, may seem like a surprising choice. Through a partnership with the CNCF, Packet provides free on-demand hardware for CNCF projects. This meant we could run fast, cached Docker builds and kind clusters on a single, high-performance Packet host. These hosts were performant enough that we could run all integration tests in parallel, and multiple PRs in parallel on top of that.
GitHub Actions
GitHub Actions was just emerging from beta as we were evaluating technologies. Several properties motivated our selection here. Most immediately, it was already integrated with our PRs in GitHub, which meant one less integration point. It supported matrix builds, where we could easily parameterize our eight integration tests, one per kind cluster. It also supported flexible dependencies between tasks. For example, we could have two tasks running in parallel, one to boot a kind cluster another to do a Docker build. When both were complete, we could kick off our integration tests. Also, GitHub Actions is free for open source projects. While not open source itself, this was the next best thing.
Take 2: CI with kind + Packet + GitHub Actions
With the technology selected, we implemented and rolled out our second generation CI system:
Take 2: kind + Packet + GitHub Actions
GitHub Actions provided PR integration and job management, and we used their matrix builds to boot our eight kind clusters:
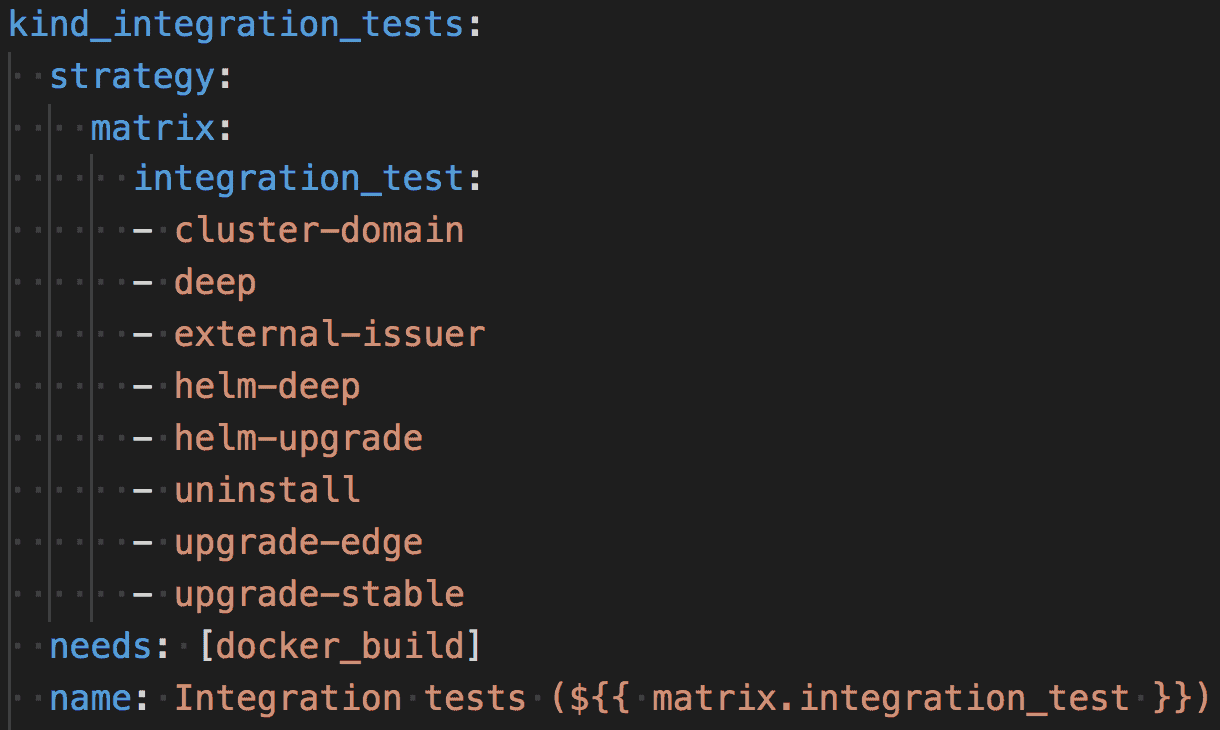
Booting 8 kind clusters via GitHub Actions matrix builds
This whole setup allowed all integration tests (and PRs) to run in parallel, using fast, cached Docker builds on Packet. Our CI time decreased from hours to about 10 to 15 minutes!
Note that while the job is managed by GitHub, the heavy lifting is happening on the Packet host. To enable this, we employed a clever (hacky) technique to create and interact with remote kind clusters. To connect to a remote Docker over SSH, you can set the DOCKER_HOST environment variable to ssh://[PACKET_HOST]. This allows you to create a kind cluster on a remote host. However, the local kubectl config still expects the kind cluster to be on localhost. To work around this, we read the remote kind cluster’s port from the kubectl config, and port forward to it. Here’s a demo video demonstrating this.
We weren’t sure if this was a known pattern, or if there was a better way, so I jumped into the #kind channel on Kubernetes Slack to ask. Fortunately the creator of kind replied immediately to let us know that while what we were doing was not totally expected, it looked relatively sane:

#kind FTW
A big shout out to the kind community (and its creator) for fostering a welcoming and supportive environment. These interactions are what make open source great, and something we try to emulate in our Linkerd community.
Take 3: CI with kind + buildx + GitHub Actions
The astute reader may have noticed that in take two, we were only running non-forked PRs in Packet. This was due to our earlier requirement that we did not want untrusted code running on hardware we were responsible for. This was not ideal as it meant forked PRs still took a very long time to pass CI, not a great experience for developers new to the project. A few months passed and our team started experimenting with Docker Buildx. This tool enabled us to save our Docker build cache to a file, for reuse in subsequent GitHub Actions jobs. This allowed us to remove the dependency on Packet, and run all builds at full speed directly on the GitHub Actions hosts:
Take 3: kind + buildx + GitHub Actions
Here’s a video demonstrating Linkerd’s end-to-end experience of pushing a commit and observing eight Kubernetes clusters all boot in parallel
Lessons learned
Some key takeaways after all this work:
Use kind
Kind is a great tool, not only for CI but for local development as well. There are similar flavors of Kubernetes, such as Minikube and k3d. We selected kind because it’s used heavily by the Kubernetes community for testing Kubernetes itself. Also a huge shout out to the #kind channel in Kubernetes Slack.
Cache your [docker] builds
Caching our Docker builds between CI runs was a key ingredient in speeding up our CI turnaround time – this applies to all forms of build caching.
DOCKER_HOST=ssh://
Using Docker over SSH is quite handy. I personally haven’t run Docker on my own development system in months.
Docker Buildx
Docker Buildx not only provides caching, but enables cross-platform builds. This enabled Linkerd to recently begin building, testing, and distributing an arm build.
Shoutouts to Packet and GitHub Actions for supporting OSS
While not open source themselves, the support companies like Packet and GitHub provide to open source projects is invaluable in keeping projects like Linkerd moving. A big thank you to them!
One More Thing: Linkerd CI Metrics
One thing we really liked about Prow was it’s great dashboard for displaying build history. We wanted something similar, so one of our maintainers Alejandro cooked up a Linkerd CI Metrics dashboard. Check it out.
