
Member Blog Post
Guest post originally published on DoiT International’s blog by Joshua Fox
Kubernetes makes it easy to orchestrate the pods that run your applications. But what about the clusters that the pods run on? These need a lot more hands-on care to configure correctly across the clouds, and in particular, to clone a configuration of a cluster from one cloud to another.
In this article, I compare cluster models across Azure, Google, and Amazon and present a tool for cloning clusters within one cloud or cross-cloud.

With Kubernetes, managing your application is easy: The Kubernetes controller makes sure that your application has the resources needed, including memory, disk, load balancers, and redundant instances of your servers. Everything is standardized and automated, and you can switch infrastructure providers with hardly a change.
The Kubernetes’ abstraction insulates you from the infrastructure level, but the infrastructure is still there. A cluster’s nodes are just VMs, which are not standardized across cloud providers. For a newcomer, this is frustrating. Why do we have to figure out the necessary resources and APIs as modeled differently on the various clouds, when everything else about Kubernetes is so standard and automated?
Serverless container architectures like AWS Fargate, Google Cloud Run, and Azure Container Instances make it easier to deal with the infrastructure (at the cost of less control), but they do not give the cross-cloud standardization you expect from Kubernetes. If you are launching standard Kubernetes clusters, you need to understand the non-standard cluster infrastructure models.
This brings us to Cluster Cloner, an open-source tool that can copy clusters from cloud to cloud, or inside a single cloud. I will use it to compare the implementations of clusters in Google Kubernetes Engine, Azure Kubernetes Service, and AWS’s Elastic Kubernetes Service.
Meet Cluster Cloner
If you want to clone your cluster’s Kubernetes configuration, you can use Heptio Velero. The Kubernetes etcd makes this straightforward, as the full configuration is stored there. But before you do that, you need to copy the cluster’s virtual machines and the other resources on which Kubernetes runs. Cluster Cloner is a command-line tool that I developed in Go, available both as a Docker image and as a standalone application.
If you use Terraform or other infrastructure-as-code tools, copying clusters is not a problem: Just run the same code (with appropriate adjustments). But when a cluster has been created in other ways, you need a tool that can understand the cluster as modeled in one cloud, and translate it to another cloud’s model.
You can use Cluster Cloner in one of two ways: Either by directly copying a cluster, or else as “dry run,” with an intermediate step allowing you to tweak the process.
Option #1: Direct clone
To copy clusters, run clustercloner, specifying the input cloud and the “scope”. (The scope is the Google project or Azure Resource Group; it is not needed in AWS.)
Also, specify the input location. In AWS and Azure, that is the region. In Google, give the zone name for zonal clusters and the regional name for multizonal regional clusters.
Likewise, specify the output cloud; and the output scope for Azure or GCP.
Because every action can take many minutes ( details below), creation is by default a dry run. Specify --nodryrun to actually create the clusters.
Cluster Cloner copies all the clusters in the given location, but you can restrict the copying by specifying --labelfilter with a comma-separated list of key-value pairs. In this case, all labels must match for a cluster to be copied.
An example command line:
clustercloner --inputcloud GCP --inputscope my-google-project --inputlocation us-central1-c --outputcloud AWS --key-a=value-a,key-b=value-b --nodryrun
Documentation about the command line is available through clustercloner --help. Documentation on developing, running the unit and integration tests, and building the binary and Docker image are in the README file.
Option #2: Customize the cloning
You can also customize the process. Cluster Cloner always outputs a description of the target cluster in JSON. So, do a dry run by omitting --nodryrun, and edit the output JSON as a specification of the cluster you want. Then run clustercloner again, providing the JSON filename as an argument for the --inputfile option. The clusters defined in the file will then be created.
EKS, AKS, and GKE: Similarities & Differences
Cluster Cloner is built to bridge between the three very different models for cluster infrastructure. Next, let’s compare the basic elements that make up a cluster in Google, AWS, and Azure.
We will not, however, compare advanced features, since the three cloud providers are always racing ahead to keep up with each other. Also, this article is based on Cluster Cloner, which is focused on transforming the compatible parts of the core models. Some aspects of the models are not copied because they are specific to the design of a specific cloud, like GKE’s master authorized networks and Alpha clusters.
Comparing the cluster models
Terminology
Let’s start with the terminology, the easiest part of the comparison of the cluster models, as expressed in the APIs.
In the three clouds, we have the following terms. Inside Cluster Cloner, GKE terminology is generally used, recognizing the origin of the Kubernetes project within Google.
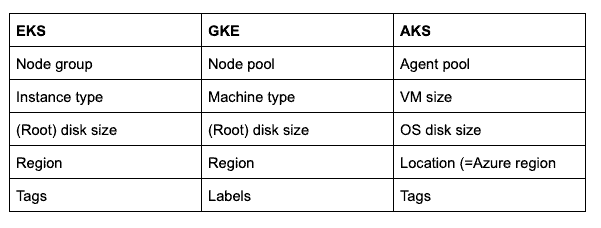
Cluster and node pool model
Kubernetes Versions
- GKE and AKS support a list of patch versions, available through APIs which Cluster Cloner uses.
- Cluster Cloner never tries to change the major and minor version. To choose a patch version in AKS and GKE, Cluster Cloner looks for the least patch version that is the same or greater than the source cluster’s version, or if that is not possible, the largest patch version.
- EKS is simpler, supporting four minor versions, currently 1.12, 1.13, 1.14. 1.15, which Cluster Cloner hard-codes.
Regions
- GKE supports clusters in all Google regions.
- EKS supports clusters in all but a few regions.
- AKS only supports a specified list of regions.
- Still, each cloud supports Kubernetes in geographies around the globe. Cluster Cloner automatically chooses a nearby region based on a conversion table.
Zones
- In EKS and AKS, clusters are defined regionally, but clusters can be assigned to availability zones by choosing the subnets for each node group.
- GKE lets you create zonal clusters or multi-zonal regional clusters.
- Cluster Cloner supports zone choice only in GKE.
Machine types
- Cluster Cloner uses a simple approach for conversion, finding the least-upper-bound machine (instance) type in the target cloud — in other words, a machine type that has the least possible CPU and RAM, while still having no less of each than the source machine type. (The choice is not necessarily uniquely defined.)
- Machine types are difficult to convert, as they vary in other characteristics than CPU and RAM, including choice of CPU and GPU model, IO, and importantly, trade-offs like memory-optimized and CPU-optimized types. Taking these characteristics into account is on Cluster Cloner’s to-do list.
Speeds
Cluster Cloner provides an excellent opportunity to measure speeds given that the same action is performed in each cloud. See the chart below.
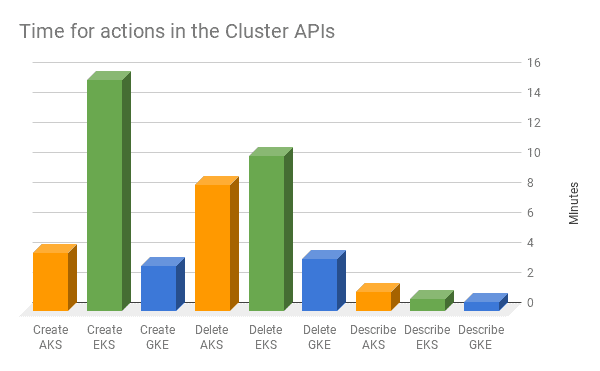
Waiting a few more minutes does not have to be a showstopper, but it does affect your ability to treat clusters as you are used to treating pods — as “cattle not pets,” to be deleted and recreated at will.
The ins and outs of EKS APIs
Cluster Cloner uses eksctl for creating and deleting clusters and node groups. Since eksctl is a command-line tool not designed for API use, Cluster Cloner wraps it at the command-line entry point. We use eksctl for creation because it is smart enough to generate all the underlying resources needed for a cluster. This includes a VPC, subnets across availability zones, and security groups. Just as importantly, eksctl can tear down these resources, in the right order: First network interfaces, then VPC, and only then the EC2 VM instances.
For reading the clusters, Cluster Cloner does not use eksctl, which cannot describe the full detailed model of clusters and node groups. This is surprising, given that eksctl is now AWS’s recommended tool for managing clusters. The limitation comes from the fact that in EKS, the infrastructure layer (EC2 with instances, subnets, and VPCs) is more clearly visible than the other clouds, and less hidden by Kubernetes-related abstractions like nodes and node groups. Still, the information is available: Cluster Cloner uses the AWS SDK for Go to get all the data needed to characterize clusters and node groups.
What lies ahead
The cluster model, in all three providers, is rich and provides configuration options that are not yet supported by Cluster Cloner.
The features list shows what Cluster Cloner knows how to copy, as well as unimplemented aspects, for example:
- Kubernetes versions and tags should be copied on the node pool level, not just on the cluster level.
- Autoscaling definitions should be copied.
- Spot instances should be supported in EKS, not just GKE and AKS, and today.
If you want a feature, feel free to contribute a pull request on GitHub or add a GitHub issue.
Work with Joshua at DoiT International! Apply for Engineering openings on our careers site.