

By the Harbor team, originally posted on the Harbor blog
On the heels of the announcement that Harbor is now a Graduated project in CNCF, the team is preparing for another big event—the upcoming release of Harbor v2.1. Harbor v2.1 focuses on better image distribution through integrating with P2P providers like Uber’s Kraken and Alibaba’s Dragonfly, enabling Proxy Cache capabilities, and a vastly improved non-blocking Garbage Collection capability. But in keeping with the spirit of open source innovation, v2.1 also sees Harbor making headway in AI / ML as the container registry of choice for hosting Machine Learning models used in Kubernetes deployments. Let’s dive in.
Machine Learning and Deep Learning on Kubernetes have made rapid gains in recent years with projects like KubeFlow that aim to deploy ML models on any Kubernetes cluster either on-prem or in the cloud. Already utilizing native Kubernetes concepts like loosely-coupled microservices and automatic scaling and scheduling to their fullest, it was time to use the best registry for Kubernetes to round out the entire Machine Learning pipeline.
ByteDance, one of the leading cloud providers working on KubeFlow and one of its early founders, has teamed up with the Harbor team to deliver a solution for managing and distributing Machine Learning / Deep Learning models.
Why do you need to distribute models
Relative to traditional applications that are delivered as binaries or other self-contained, well packaged formats, Machine Learning workloads require an additional Model Inference Server in addition to the actual models for iterating and publishing these workloads.
The Model Inference Server is to ML applications as Tomcat is to Java Web Applications.
The Machine Learning model itself contains only the parameters of the model including the weight and structure, and relies on that Model Inference Server to provide RESTful or gRPC-based services to connect to the outside world. Any request to use or deploy the ML model will be routed to the Model Inference Server first, whereupon it will employ the model to perform forward calculations and return the results to the caller.
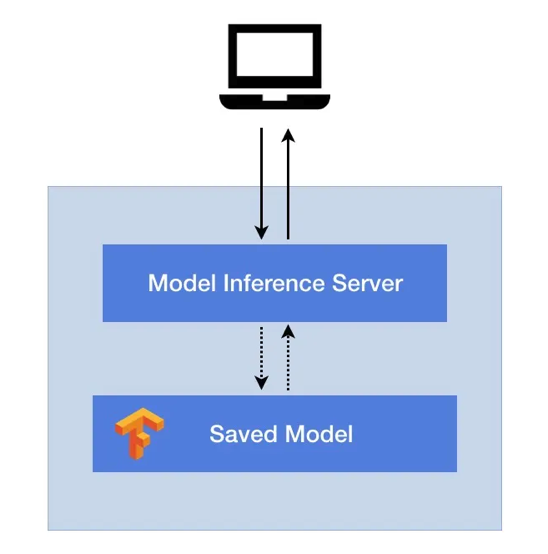
To solve the problem of ML model distribution, an initial attempt was made by ByteDance to package the Model Server as well the models together as a single container image for publishing.
But several problems quickly manifested:
- First, the model server itself is almost an immutable infrastructure and is usually maintained by the Infrastructure team whereas the models are maintained by the Algorithms team. The model server is often quite hefty and taking the Nvidia Triton Inference Server version 20.03 as an example, its Docker image consists of 43 layers and occupies 6.3 GB when fully decompressed. There was no existing P2P distribution frameworks that could efficiently move these around.
- Second, the model is updated very frequently. If the packaging process cannot be automated, algorithm engineers must always be involved and thus adding to the cost of deployment.
- Third, the inability to properly capture crucial metadata of the model such as hyperparameters, training indicators, and storage formats in the image means it’s difficult to scale well as the number of models and their versions multiply.
Leveraging Image Registry for better distribution
To decouple the model inference server from the model itself and adhering to the Docker mantra of ‘Build Once, Deploy Anywhere’, ByteDance chose the Harbor registry as the warehouse as well the distribution platform for these models. Users can easily store and retrieve their models using similar ’docker push’ and ’docker pull’ commands and fully leverage Harbor’s Role Based Access Control, identity integration, security policies around image deployment, and lifecycle management features like creating retention policies and immutability policies for managing these models.
To interact with the Harbor registry, ByteDance created a dedicated tool called ORMB (OCI-based Registry for ML/DL Model Bundle) mimicking the Docker client that can easily create, version, and publish Machine Learning / Deep Learning models to OCI registries. It can pull down these models, repackage with new versions, and redeploy onto a Kubernetes cluster directly from Harbor, similar to how Seldon Core deploys directly to Kubernetes from S3 storage. This works with popular model formats such as SavedModel used in TensorFlow and potentially many others. ORMB is designed to work with any OCI distribution and the team at ByteDance chose Harbor in part because of its total compliance with the OCI image specification as well as the distribution specification. A Machine Learning model is packaged as an OCI image with its own manifest mediaType and Image Config mediaType so that they can be interpreted by Harbor and the image layers can be correctly persisted in storage.
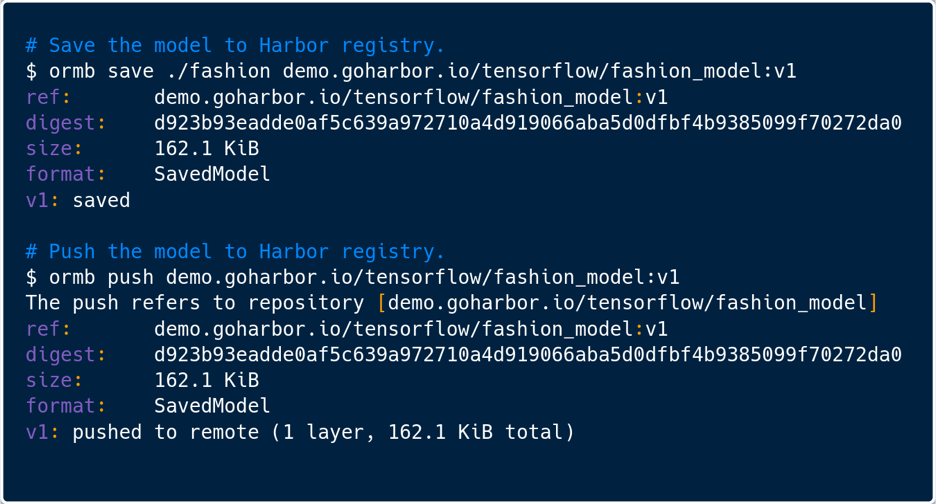
Specifically, following the guidelines for authoring OCI artifacts in the OCI artifact project, the Harbor team worked with ByteDance to define a new Config schema and a process by which to capture these attributes on Harbor’s UI and API.
The bonus effect is that this schema can be leveraged by not only ByteDance’s Machine Learning models artifacts or general ML / DL artifacts, but is also easily customizable to capture critical metadata for any other user-defined artifacts. You can read the detailed proposal here. The reason behind enriching the content within the manifest.config is to offer additional instructions on how the layers are to be instantiated and to provide meaningful top-level information. For example, OCI Image Config by default stores OS, Architecture, and Platform that some registry operators may wish to display. In this case, the Config will contain typical TensorFlow model-specific information such as the framework (“TensorFlow”), format (“SavedModel”), signature, training, datasets and more. The config object is also easy to pull and parse and does not require retrieving all the layers from a URL to pull, decompress, and parse.
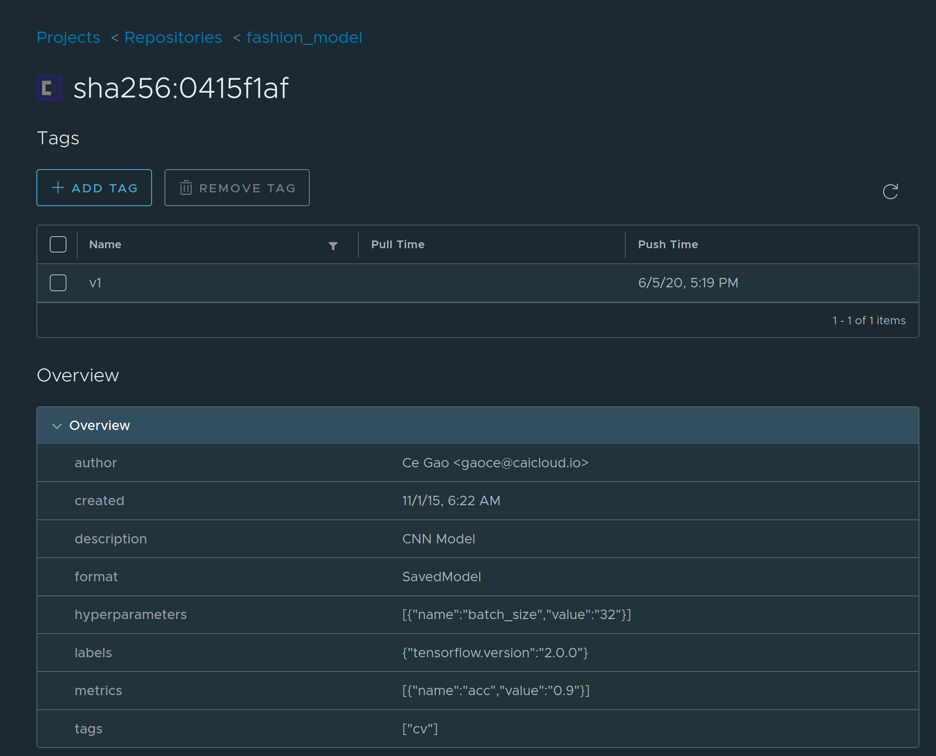
Furthermore, leveraging Harbor’s webhooks, a notification can be triggered each time the model is updated and pushed to Harbor so that a redeploy of the model can immediately follow. Harbor replication is then used extensively to synchronize models between various registries in the model training environment as well as the model production environment. This marks the first instance of Harbor being used for storing Machine Learning related artifacts and rests heavily on the work we did to become an OCI compliant registry. Stay tuned as we look for more ways to contribute to the ML / DL and Kubernetes communities!
About Harbor
Harbor is an open source registry that secures OCI artifacts with policies and role-based access control, ensures images are scanned and free from vulnerabilities, and signs images as trusted. Harbor extends the open-source Docker Distribution, adds two-way replication to third-party registries, and can be fully managed through a web console or a rich set of APIs. Harbor, a CNCF Graduated project, delivers compliance, performance, and interoperability to help you consistently and securely manage artifacts across cloud native compute platforms like Kubernetes and Docker
Collaborate with the Harbor Community!
Get updates on Twitter ( @project_harbor) Chat with us on Slack ( #harbor on the CNCF Slack) Collaborate with us on GitHub: github.com/goharbor/harbor Attend the community meetings: https://github.com/goharbor/community/wiki/Harbor-Community-Meetings
Alex Xu
Harbor Maintainer
@xaleeks
Yiyang Huang
Harbor Contributor
@hyy0322