Guest post from Fred Chien (錢逢祥)of Brobridge

Photo by Tobias Fischer on Unsplash
An example of rapid implementation of Open API requirements
Unless your application is in a state where there is no data requirement or no data residency (refer to the old article: “Three Microservice Applications with Different Difficulties“), data decoupling is the ultimate issue cannot be ignored. Since all applications rely on data, data management problems, splitting, and decoupling becomes extremely important. Wrong data splitting or failure to implement data decoupling will make microservice architecture impossible.
In fact, if you are familiar with applying the CQRS model, even without data reconstruction, you can achieve a certain degree of data decoupling. Even if it is used in a non-microservice architecture application, CQRS can still benefit you a lot.
For those who have no idea why data decoupling is required and how to do it, this article will discuss the problems encountered in data decoupling through service splitting. Finally, we use the Open API as an example to illustrate the practical application method of CQRS.
The composition, splitting and decoupling of an application
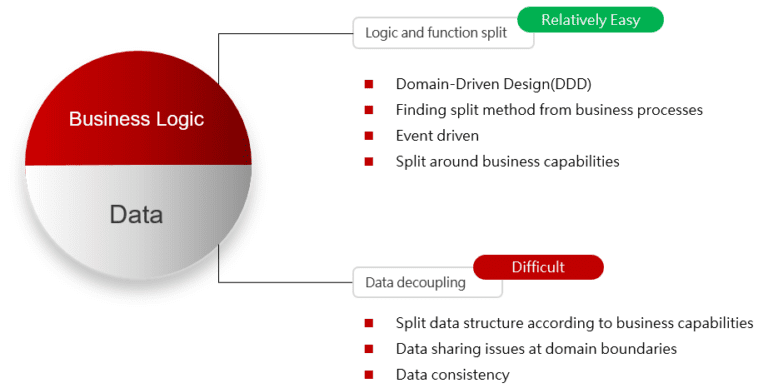
The composition of an application is usually divided into two parts: “Business Logic” and “Data”, both are indispensable. When we are splitting microservices, it is the goal to cut these two parts apart.
Relatively speaking, the splitting of logic and functionality is easier than the decoupling of data. The simple implementation can even be achieved by only working on the code. The most challenging thing is to sort out the business and even be completed by introducing Domain-Driven Design (DDD).
However, splitting and decoupling at the data level is not that easy. In addition to the complexity of the structure, the problem of system efficiency will also be considered. The tasks are not just disassembling and reconstruction. In practice, many risks and data management problems are coming up if the data structure is changed while splitting the old system.
What happens if you just split the logic?
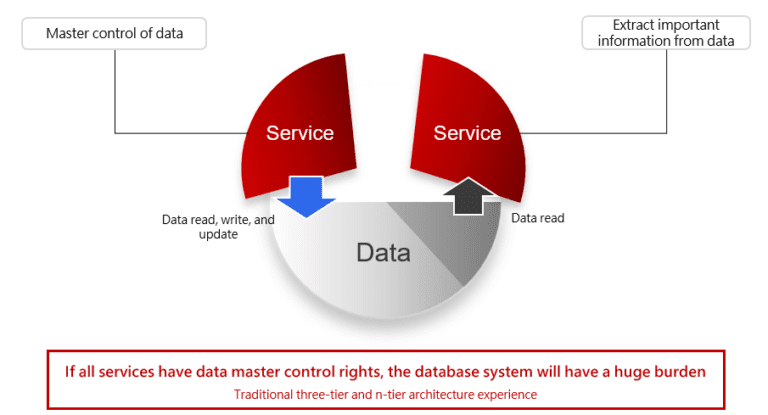
As shown in the figure, in the past, under the three-tier or n-tier architecture, we have experienced the pain of many shared database systems and also faced the physical limit. If you only split the logic, the database will be the first impacted system. If the data exchange between services is performed through a single database, the performance of the database will be the bottleneck of the entire application, and it will be difficult to scale horizontally to adapt to business needs in the future.
From an architectural perspective, if you only split the logic, except for the separation of the code entities, it is essentially not much different from without splitting, but adds more costs and risks for management, deployment, and network connection.
Note:
Sharing a database means that you separate the database into a service that is used to supply data to other services. If we consider this service as an object, which has data such as status and attributes, and its value is mainly derived from information such as status and attributes, then we will find that this directly conflicts with the “The first law of decentralized object design: Don’t distribute your objects”, proposed by master architect Martin Fowler.
Annotation: Martin Fowler is the author of the classic “Patterns of Enterprise Application Architecture” book that enterprise architects must-see.
The real purpose of high-risk data structure splitting
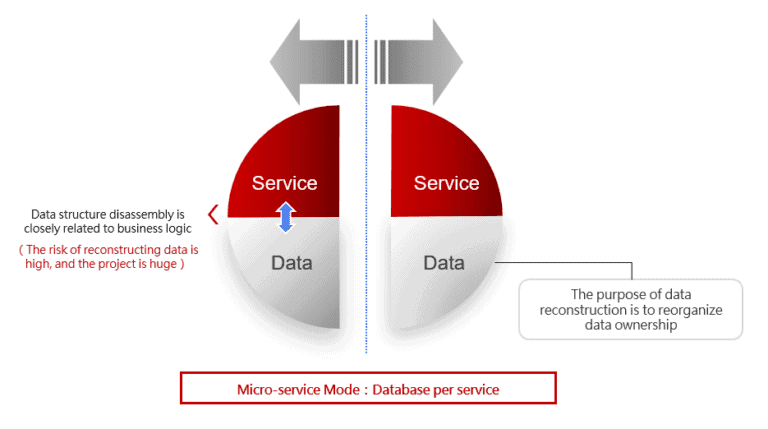
Under the recommendation of the microservice architecture, a database per service is an ideal state. But if you want to disassemble the data according to the superficial meaning, it also means that it is a very large project to dismantle the old system, and it also takes a very big risk. It is a difficult problem and unbearable for all enterprises.
However, our goal is data decoupling, is it necessary to take such great risks to reconstruct the data?
From the perspective of business functions, all data actually have their corresponding owners. Most other business needs for this data are mostly inquiries and “extraction of information”, and are not responsible for management. So usually in the design of microservices splitting, any data must have a dedicated service to handle change management.
To put it bluntly, the purpose of splitting the data structure is to “organize and determine the ownership of the data”. Data splitting is not the focus. When we determine the ownership of the data, there will be no problems with the hydra-headed, and there will be a way to properly implement the method and structure of data management in its corresponding services.
Therefore, if you cannot change the existing database and data structure, it does not mean that you can not decouple the data. Figure out the ownership of each data, each field of data, and its corresponding service. This is what you have to do first.
There must be a need to share information between services
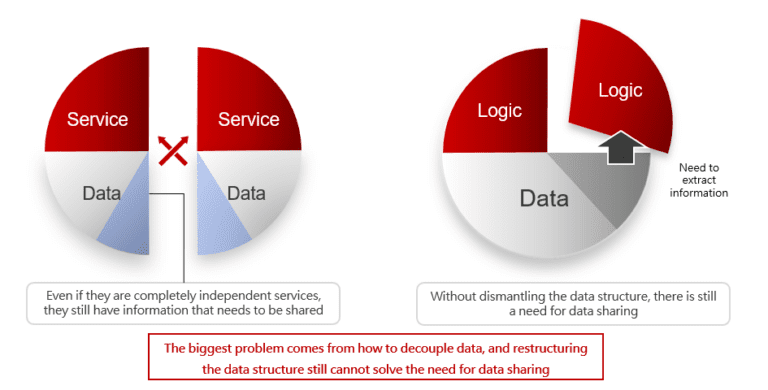
Imagine if you still have to deal with the issue of data sharing after disassembling the data, and it will cause calls between services to be too frequent or even seriously affect the operation of the network or system, then why should it be demolished? However, if it is not dismantled, it will fall back to the circle of the old architecture, and it is impossible to truly implement the microservice architecture.
How to choose whether to dismantle the data structure or not?
In fact, no matter whether you dismantle or not dismantle the information, there must be a need for information sharing between your services. If you have to solve the problem of data sharing no matter how you choose, dealing with “data sharing needs” is the main task of data decoupling, rather than restructuring or physically splitting data.
The real goal of data decoupling
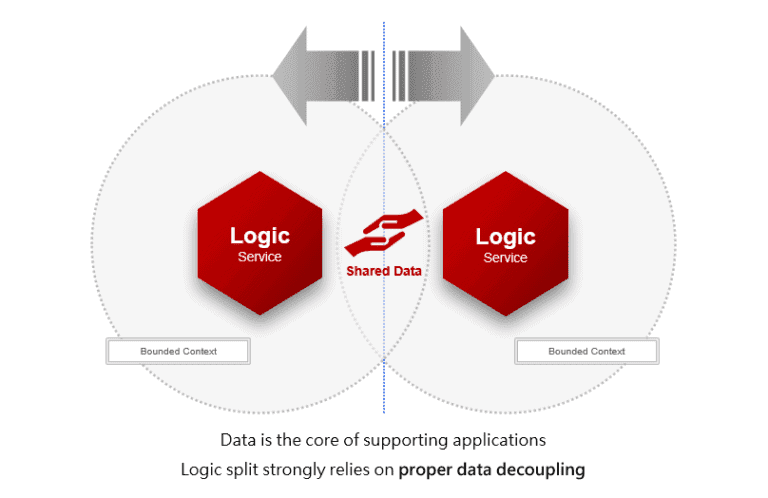
The goal of data decoupling is to solve the data overlapping in two business areas. Because the two areas have associated data that needs to be shared. How can external services obtain the required information to meet the business needs without excessive impacting the existing system performance is the most important issue.
Introduce CQRS for data decoupling
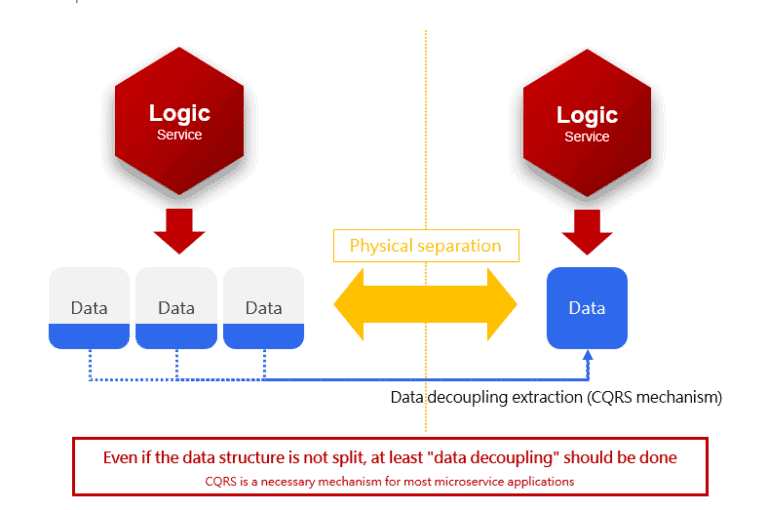
To meet the needs of data sharing without impacting system performance, the CQRS model will be proposed to solve this problem. CQRS is used to separate query operations without the need to copy the entire data set but to extract partial data required by another business logic and cache design.
The extracted data at this time the ownership has changed, not belong to the original service, but owned by another service. If necessary, the extracted data can be further processed in conjunction with the design of the data pipeline to generate a new piece of data for business needs.
It is the use of CQRS in this situation to reduce the impact on existing systems and improve the efficiency of data reading and querying by the principle of “repetition is greater than reuse”, which is common in such distributed systems.
Note:
For more explanation and introduction of CQRS, you can refer to the other article “About the implementation method of CQRS“.
How to quickly implement Open API requirements
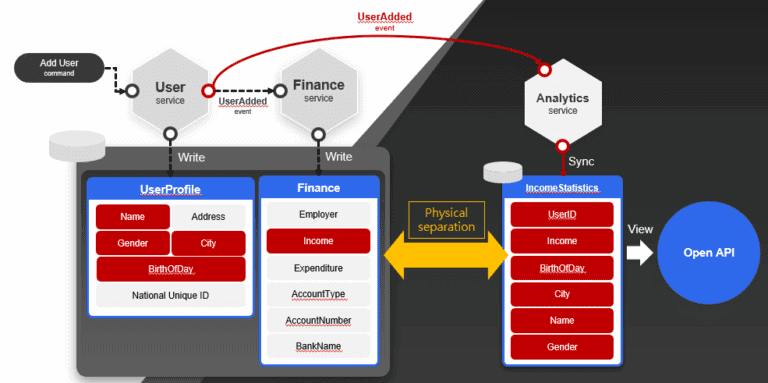
We have discussed a lot of the importance of data decoupling and how to use CQRS to solve its related problems, in practice, in which applications or requirements can we actually import CQRS? In fact, the public Open API is one of the best introduction fields, and it can be fully realized or improved by taking advantage of the CQRS mechanism.
Since most Open APIs are mainly query-based, they are mainly open to third-party services and applications. Unlike the development scenario in the past, the Open API connections are almost opened to external services. Most of these external services are not under our control, so it is quite difficult to predict the use of the API. Under this circumstance, the design of the API and the operation control usually require more attention.
Generally speaking, while considering the design of the Open API, there are probably three key points:
- Security and Management: For many companies, direct connecting to existing systems may lead to many security concerns. By bridging the old and new systems, more organizational and management issues will exist.
- System efficiency, stability and scalability: Because of the open API, it is impossible to accurately estimate how many external systems and how many query requirements there are actually. Even, due to special festivals and conditions, the problem of a sharp increase in traffic may be one of the troubles. Therefore, in design, we will ask to increase the throughput of the API as much as possible, and try to make it maintain the flexibility of horizontal expansion to meet the possibility of future demand increase.
- The influence of the old system: Because the data source of Open API comes from the existing system, this is an impact on the existing system. A large number of access requests will come straight, which directly affects the existing system and related business performance and operations.
These factors have caused us too much trouble in the Open API design, deployment and maintenance. How can we meet these considerations and rapidly implement the Open API with scalability?
As shown in the example in the figure, if there is an Open API to obtain the query data of the average income of a certain age group and a certain gender, it can be imagined that the impact of the existing database caused by the relational query is very terrifying.
However, if CQRS and event-based design are introduced, by extracting, aggregating, and caching the required fields and data, and finally separating the entity, and storing data outside the old system, we can meet the needs of a large number of external queries with minimum affection of the old system operation. This method of using CQRS, which is a method of multiple views, is a fairly common design under the microservices architecture.
Note:Even better, during the process of data extraction, even a mechanism to desensitize data can be implemented, so that the data released outside has an absolute security and privacy data protection.
Under this architecture,the Open API’s design and maintenance are relatively simple: select the data that needs to be extracted from the source, decouple the data and store in its own database system. Then you can query your own database to meet the query needs. The key point is that because the data is decoupled and correlated in advance, you don’t need to use too complicated correlation queries to improve query performance. If the throughput demand increases in the future, it is only necessary to horizontally expand the database or the service itself, which has nothing to do with the old system and does not affect the old system.
Besides, except for the work of extracting data from the incident, the service itself can entirely operate independently, and because there is no other way to connect back to the existing system, it can be decoupled from the old system to the greatest extent and maintain a distance. You can even put the service in a public cloud or other data center to implement a hybrid cloud architecture.
Is it difficult to implement CQRS? Is there a solution out of the box?
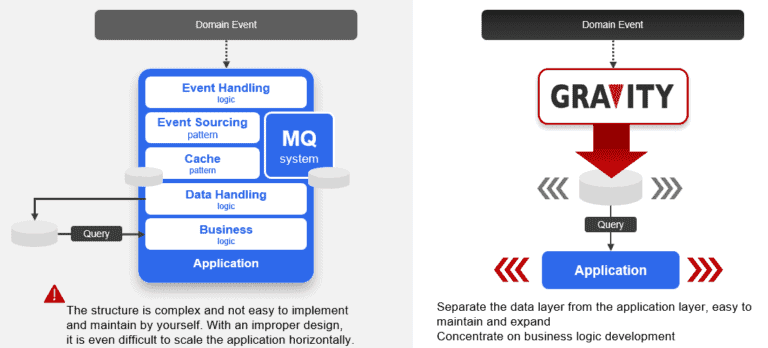
Implementing CQRS is not difficult, but there are quite a few issues that need to be addressed. Anyone can design a minimalist approach, but considering the requirements of data integrity, rapid recovery, and the problems of customization, deployment and maintenance, it is a very troublesome headache for developers. Without proper design, it may even result in the birth of another large-scale monolithic application. It is not impossible and must be cautious.
That’s why Broadbridge provides “Gravity, a out-of-the-box CQRS solution” so that customers can concentrate on service splitting and the implementation of their own business logic without worrying about the problem of data decoupling.
—
The materials and sources of this article are all from Brobridge’s microservice architecture design education and training courses. If you want to know more about microservice
architecture design issues, you can contact us. If you are interested in the issue of CQRS solution Brobridge Gravity and its data decoupling, please feel free to contact us.