
Guest Post from Andy Shi, developer advocate for Alibaba Cloud
As a platform engineer, I often feel like a sandwich: Being squashed between the customer and the underlying infrastructure. The complaint I get most from users is about Kubernetes YAML.
As Kelsey Hightower says, “We like to hate YAML files.”
Yes, YAML has its own problems. But we shouldn’t use YAML as the scapegoat.
We’ve tried to use GUI to simplify the YAML file. But Devops/ operators wanted more options. We’ve also tried all-in-one YAML. Developers really hated those “additional” fields. Finally, I realized the problem is because Kubernetes API is not team centric. In many organizations, developers and Devops/operators are two different roles. Yet when using Kubernetes, they have to work on the same YAML file. And that means trouble. Take a look at this all-in-one YAML:

The developers care about a small part of the fields while the Devops/operators care about the rest. But these fields are tangled together in those APIs.
Even with Kubernetes built-in objects, the problem remains:

Take this Deployment YAML for example. For developers, they only care about the mid-section where it specifies the application. They can’t care less about the other sections. But those sections are there. Similar situation is faced by the operators. And the tension gets worsened when new fields or even new CRDs are introduced. When things don’t work out, they leash out the frustration on YAML.
Talking about the new capabilities installed by CRDs, that’s another problem. Over time, K8s community has more active developers than Linux. Most of them are extending K8s through CRD and customized controller/operator. Right now, almost every extended workload and operational capabilities you can think of there is a CRD or some controllers somewhere in my cluster.
First issue I have is how do I keep track of these capabilities? Can I get a list of them? If I query an individual CRD will it give me the details the users need to know?
And it’s not just the capabilities out of Kubernetes community. There are so many managed services on different cloud vendors like databases, message queues, logging systems, etc. There are also great pieces of functionalities from other technologies such as Terraform and Nomad that we can reuse.
How do we converge these resources and capabilities and offer the users a smooth user experience in a unified approach?
We face the dilemma of the level of abstraction. If we wrap them up really nicely, it’s goanna take a long time and we need to fork it to be really opinionated. That will lead to hefty maintenance cost. If we expose these capabilities raw, we would get more complaints about YAML. This got me thinking: What is the good way to abstract these capabilities, so that they are not too rigid for the users and still allow us to provide added value at the same time?
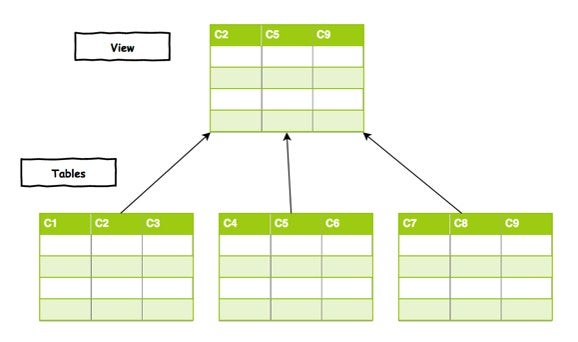
K8s is a declarative system. It means each controller tries to reach the desired state of its objects. The controllers will provide the CRUD operations on the objects. Many call this design “infrastructure as data”. But given such rich source of capabilities, we should call it “infrastructure as database”. Using the database analogy, it’s easier to describe the situation.
The right term in database to describe what I want is a view.
A view is a virtual table. The main purpose of a view is to abstract the complexity of creating a specific result set. This approach has been discussed and tried out in the K8s community for quite some time. A couple months ago, there is a nice blog post on how Pinterest created custom CRDs to abstract and customize several upstream workloads into one. This is an example of the “view” creation.
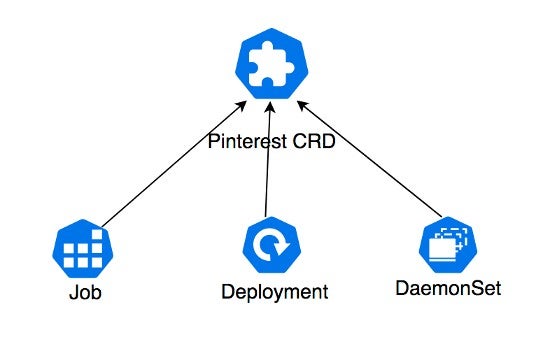
But we need to take it one step further.
To make all the capabilities manageable, we need a standard on them so that we can collect, query and share them in a unified approach. That calls for a spec. The benefit of a spec is beyond manageability, though. It also enables reusability of the views we created. The Pinterest CRDs may benefit other platforms and vice versa. In the end, this will create an ecosystem of CRDs, a CRD market that will flourish.
This Spec should also take into account of the previous requirement, i.e. being team centric. It should make the life of developers and operators/DevOps easier as well. I’m glad to introduce Open Application Model: the solution that I’m searching for.
OAM is a spec. It is proposed by Alibaba Cloud and Azure. The latest version of the spec is Alpha 0.2. The spec focuses on the definition of Component and Trait. And how they are combined together.
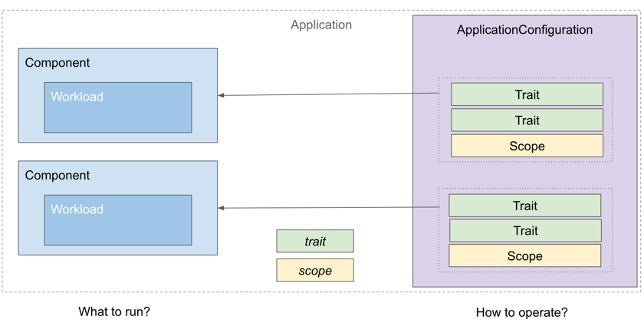
OAM is team centric. It separates application definition into two parts: Components and Traits. Components are natural pieces of application. They are the front end, the back end, the database, the storage, and other dependencies of your applications. They define applications from developer’s view. The component has only application related configurations and are filled in by developers.
Traits defines operational capabilities. Your workloads, rollout strategy, your update policy, ingress, etc. By assembling components and traits together, you will get the whole picture of the application, which is called application configuration. This modularized design can ensure the developers and operators focus on their own concerns.
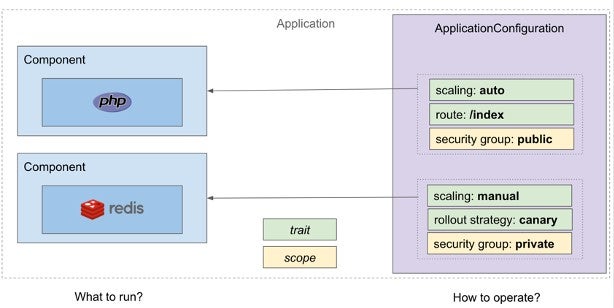
And for us platform builders, OAM will help us create a view layer for my platform with the idea of separate concerns.
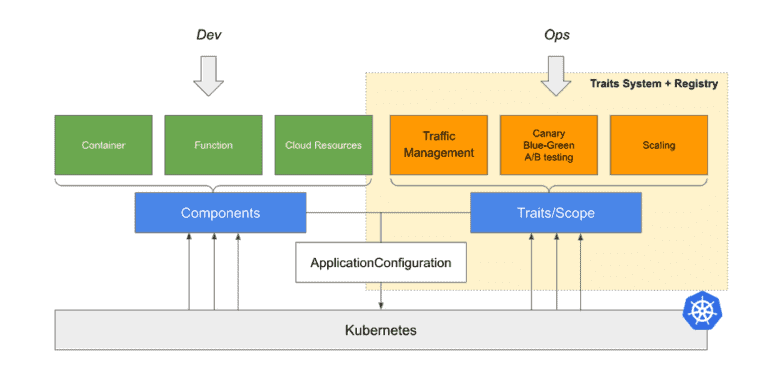
OAM is also a framework. The standard OAM framework for Kubernetes is co-maintained by OAM and Crossplane community. If you are intrigued by how we do it, please check out the git repo (https://github.com/crossplane/oam-kubernetes-runtime).
Author: Andy Shi is a developer advocate for Alibaba Cloud. He works on the open source cloud native platform technologies. He is passionate about making devops’ tasks easier and platforms more powerful.