

By Zhipeng Huang, open source community manager, Mindspore, Huawei
Hello World, MindSpore
MindSpore[0] is a new open source deep learning training/inference framework from Huawei that could be used for mobile, edge and cloud scenarios.
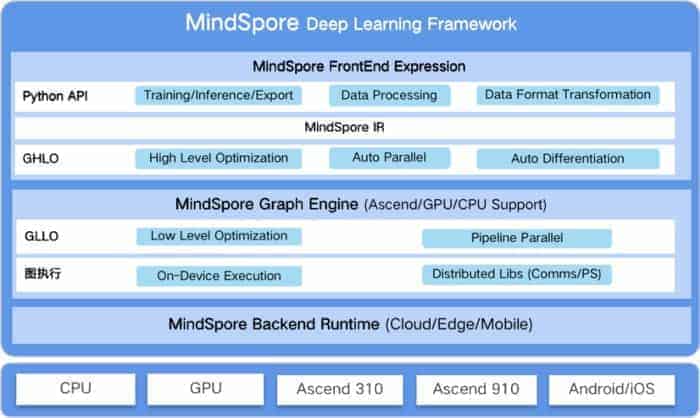
MindSpore is designed to provide development experience with friendly design and efficient execution for the data scientists and algorithmic engineers, native support for Ascend AI processor, and software hardware co-optimization.
In the meantime, MindSpore as a global AI open source community, aims to further advance the development and enrichment of the AI software/hardware application ecosystem
When Cloud Native Meets AI Newcomer
Learning from the best, MindSpore is also utilizing the cloud native ecosystem for deployment and management. With the recent Kubeflow 1.0 and Kubernetes 1.18 release, we can experiment with the latest cloud native computing technology for agile MLOps.
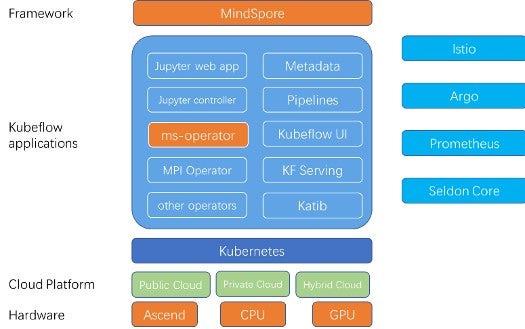
In order to take advantages of the prowess of Kubeflow and Kubernetes, the first thing we did is to write the operator for MindSpore, i.e ms-operator, and also define a MindSpore CRD. The current version of ms-operator is based on an early version of PyTorch Operator [1] and TF Operator [2].
The implementation of ms-operator contains the specification and implementation of MSJob custom resource definition. We will demonstrate running a walkthrough of making a ms-operator image, creating a simple msjob on Kubernetes with MindSpore “`0.1.0-alpha“` image. The whole MindSpore community is still working on implementing distributed training on different backends so that users can create and manage msjobs like other built-in resources on Kubernetes in the near future.
The MindSpore CRD submitted to the Kubernetes API would look something like this:
```
apiVersion: "kubeflow.org/v1"
kind: "MSJob"
metadata:
name: "msjob-mnist"
spec:
backend: "tcp"
masterPort: "23456"
replicaSpecs:
- replicas: 1
replicaType: MASTER
template:
spec:
containers:
- image: leonwanghui/mindspore-cpu:0.1.0-alpha
imagePullPolicy: IfNotPresent
name: msjob-mnist
command: ["/bin/bash", "-c", "python /tmp/test/MNIST/main.py"]
volumeMounts:
- name: training-result
mountPath: /tmp/result
- name: ms-mnist-local-file
mountPath: /tmp/test
restartPolicy: OnFailure
volumes:
- name: training-result
emptyDir: {}
- name: entrypoint
configMap:
name: dist-train
defaultMode: 0755
restartPolicy: OnFailure
- replicas: 3
replicaType: WORKER
template:
spec:
containers:
- image: leonwanghui/mindspore-cpu:0.1.0-alpha
imagePullPolicy: IfNotPresent
name: msjob-mnist
command: ["/bin/bash", "-c", "python /tmp/test/MNIST/main.py"]
volumeMounts:
- name: training-result
mountPath: /tmp/result
- name: ms-mnist-local-file
hostPath:
path: /root/gopath/src/gitee.com/mindspore/ms-operator/examples
restartPolicy: OnFailure
volumes:
- name: training-result
emptyDir: {}
- name: entrypoint
configMap:
name: dist-train
defaultMode: 0755
restartPolicy: OnFailure
```
The MSJob currently is designed based on the TF Job and PyTorch Job, and is subject to change in future versions.
“Backend” defines the protocol the MS workers will use to communicate when initializing the worker group. MindSpore supports heterogeneous computing including multiple hardware backends (CPU, GPU, Ascend, etc.), and the device_target of MindSpore is Ascend by default.
The MindSpore community is driving to collaborate with the Kubeflow community as well as making the ms-operator more complex, well-organized and up-to-date. All these components make it easy for machine learning engineers and data scientists to leverage cloud assets (public or on-premise) for machine learning workloads.
Governance Also Matters
Not only MindSpore benefits from the technological ecosystem of cloud native, it also built the community’s governance modeled after Kubernetes. MindSpore borrowed concepts like Technical Steering Committee, Special Interest Groups and Working Groups to have an open and efficient community governance. The first term TSC members consists of experts from various universities, institutions and startups.[3]
Looking Forward
MindSpore is also looking forward to enabling users to use Jupyter to develop models. Users in the future can use Kubeflow tools like fairing (Kubeflow python SDK) to build containers and create Kubernetes resources to train their MindSpore models.
Once training completed, users can use KFServing[4] to create and deploy a server for inference thus completing the life cycle of machine learning.
Distributed training is another field MindSpore is focusing on. There are two major distributed training strategies nowadays: one based on parameter servers and the other based on collective communication primitives such as allreduce. MPI Operator[5] is one of the core components of Kubeflow which makes it easy to run synchronized, allreduce-style distributed training on Kubernetes. MPI Operator provides a crd for defining a training job on a single CPU/GPU, multiple CPU/GPUs, and multiple nodes. It also implements a custom controller to manage the CRD, create dependent resources, and reconcile the desired states. If MindSpore can leverage MPI Operator together with the high performance Ascend AI processor, it is possible that MindSpore will bring distributed training to an even higher level.
[0] https://gitee.com/mindspore/
[1] https://github.com/kubeflow/pytorch-operator
[2] https://github.com/kubeflow/tf-operator
[3] https://www.mindspore.cn/community/en
[4] https://github.com/kubeflow/kfserving
[5] https://github.com/kubeflow/mpi-operator
*** Zhipeng Huang currently serve as open source community manager for MindSpore. Zhipeng is now the TAC member of LFAI, TAC and Outreach member of the Confidential Computing Consortium, co-lead of the Kubernetes Policy WG, project lead of CNCF Security SIG, founder of the OpenStack Cyborg project, and co-chair of OpenStack Public Cloud WG. Zhipeng is also leading a team in Huawei that works on ONNX, Kubeflow, Akraino, and other open source communities