


Guest post by Zhimin Tang, Xiang Li and Fei Guo of Alibaba
Abstract
Since 2015, the Alibaba Cloud Container Service for Kubernetes (ACK) has been one of the fastest growing cloud services on Alibaba Cloud. Today, ACK not only serves numerous Alibaba Cloud customers, but it also supports Alibaba’s internal infrastructure and many other Alibaba cloud services.
Like many other container services from world-class cloud vendors, reliability and availability are the top priorities for ACK. To achieve these goals, we built a cell-based and globally available platform to run tens of thousands of Kubernetes clusters.
In this blog post, we will share the experience of managing a large number of Kubernetes clusters on cloud infrastructure, as well as the design of the underlying platform.
Introduction
Kubernetes has become the de facto cloud native platform to run various workloads. For instance, as illustrated in Figure 1, in Alibaba cloud, more and more stateful/stateless applications as well as the application operators now run in Kubernetes clusters. Managing Kubernetes has always been an interesting and a serious topic for infrastructure engineers. When people mention cloud providers like Alibaba cloud, they always mean to point out a scale problem. What is Kubernetes clusters management at scale? In the past, we have presented our best practices of managing Kubernetes with 10,000 nodes. Sure, that is an interesting scaling problem. But there is another dimension of scale – the number of clusters.
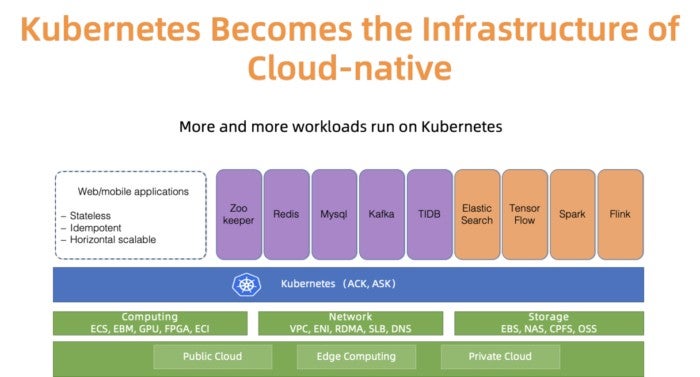
We have talked to many ACK users about cluster scale. Most of them prefer to run dozens, if not hundreds, of small or medium size Kubernetes clusters for good reasons such as controlling the blast radius, separating clusters for different teams, spinning ephemeral clusters for testing. Presumably, had ACK aimed to globally support customers with this usage model, it would need to manage a large number of clusters across over 20 regions reliably and efficiently.
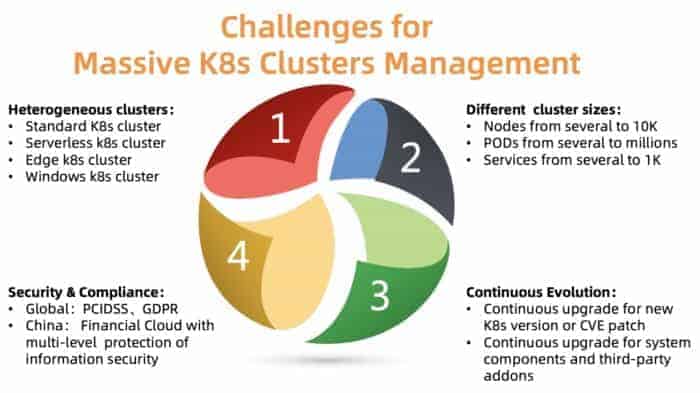
What are the major challenges of managing clusters at scale? As summarized in Figure 2, there are four major issues that we need to tackle:
- Heterogeneous clusters
ACK needs to support different types of clusters, including standard, serverless, Edge, Windows and a few others. Different clusters require different parameters, components, and hosting models. Some of our customers need customizations to fit their use cases.
- Different cluster sizes
Different cluster varies in size, ranging from a few nodes to tens of thousands of nodes, from several pods to thousands of pods. The resource requirements for the control plane of these cluster differ significantly. A bad resource allocation might hurt cluster performance or even cause failure.
- Different versions
Kubernetes itself evolves very fast with a new release cycle every few months. Customers are always willing to try new features. Hence, they may run their test workload against new versions, while running the production workload on stable versions. To satisfy this requirement, ACK needs to continuously deliver new versions of Kubernetes to our customers and support stable versions.
- Security compliance
The clusters are distributed in different regions. Thus, they must comply with different compliance requirements. For example, the cluster in Europe needs to follow GDPR, and the financial cloud in China needs to have additional levels of protection. Failing to accomplish these requirements is not an option since it introduces huge risks for our customers.
The ACK platform is designed to resolve most of the above problems and currently manages more than 10K kubernetes clusters globally in a reliable and stable fashion. Let us reveal how this is achieved by going through a few key ACK design principles.
Design
Kube-on-kube and cell-based architecture
Cell-based architecture, compared to a centralized architecture, is common for scaling the capacity beyond a single data center or for expanding the disaster recovery domain.
Alibaba cloud has more than 20 regions across the world. Each region consists of multiple available zones (AZs), and typically maps to a data center. In a large region (such as the HangZhou region), it is quite common to have thousands of customer Kubernetes clusters that are managed by ACK.
ACK manages these Kubernetes clusters using Kubernetes itself, meaning that we run a meta Kubernetes cluster to manage the control plane of our customers’ Kubernetes clusters. This architecture is also known as the Kube-on-kube (KoK) architecture. KoK simplifies the customer cluster management since it makes the cluster rollout easy and deterministic. More importantly, we can now re-use the features that native Kubernetes provides by itself. For example, we can use deployment to manage API Servers, use an etcd operator to operate multiple etcds. Dog-fooding always has its fun.
Within one region, we deploy multiple meta Kubernetes clusters to support the growth of the ACK customers. We call each meta cluster a cell. To tolerate AZ failures, ACK supports multi-active deployments in one region, which means the meta cluster spreads the master components of the customer Kubernetes clusters across multiple AZs, and runs them in active-active mode. To ensure the reliability and efficiency of the master components, ACK optimizes the placement of different components to ensure API Server and etcd are deployed close to each other.
This model enables us to manage Kubernetes effectively, flexibly and reliably.
Capacity planning for meta cluster
As we mentioned above, in each region, the number of meta clusters grows as the number of customers increases. But when shall we add a new meta cluster? This is a typical capacity planning problem. In general, a new meta cluster is instantiated when existing meta clusters run out of required resources.
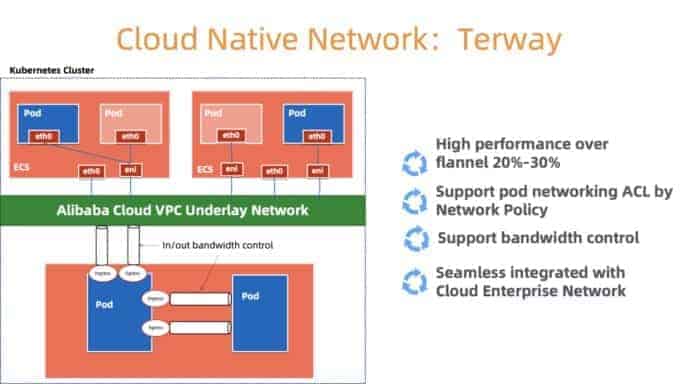
Let’s take network resources for example. In the KoK architecture, customer Kubernetes components are deployed as Pods in meta cluster. We use Terway (Figure 3) – a high performance container networking plugin developed by Alibaba Cloud to manage the container network. It provides a rich set of security policies, and enables us to use the Alibaba Cloud Elastic Networking Interface (ENI) to connect to users’ VPC. To provide network resources to nodes, pods, services in the meta cluster efficiently, we need to do careful allocation based on the network resource’s capacity and utilization inside the meta cluster VPC. When we are about to run out of networking resources, a new cell will be created.
We also consider the cost factors, density requirements, resources quota, reliability requirements, statistic data to determine the number of customer clusters in each meta cluster, and then decide when to create a new meta cluster. Note that small clusters can grow to larger ones, and thus requires more resources even if the number of clusters remain unchanged. We usually leave enough headroom to tolerate the growth of each cluster.
Scaling the master components of customer clusters
The resource requirements of the Kubernetes master components are not fixed. The number relates to the number of nodes, pods in the cluster, and the number of custom controllers and operators that interact with the APIServer.
In ACK, each customer Kubernetes cluster varies in size and runtime requirements. We cannot use the same configuration to host the master components for all user clusters. If we mistakenly set a low resource request for big customers, they may perform poorly. If we set a conservative high resource request for all clusters, resources are wasted for small clusters.
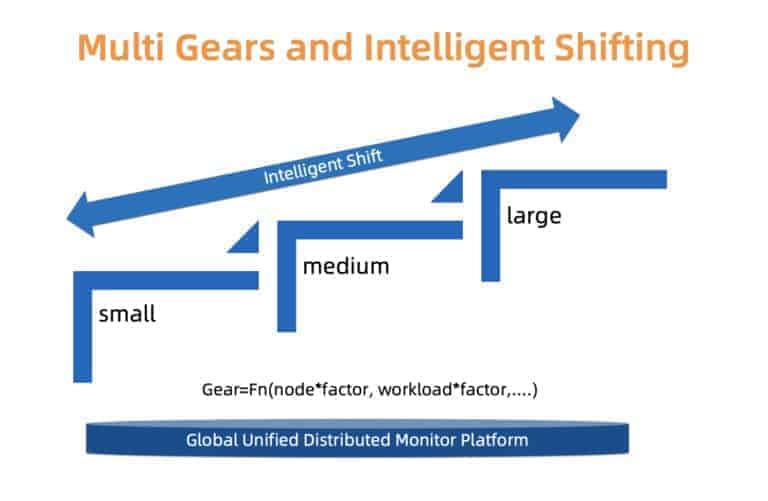
To carefully handle the tradeoff between reliability and cost, ACK uses a type based approach. More specifically, we define different types of clusters: small, medium and large. For each type of clusters, a separate resource allocation profile is used. Each customer cluster is associated with a cluster type which will be identified based on the load of the master components, the number of nodes, and other factors. The cluster type may change overtime. ACK monitors the factors of interest constantly, and might promote/demote the cluster type accordingly. Once the cluster type is changed, the underlying resources allocation will be updated automatically with minimal user interruption.
We are working on both finer grained scaling and in place type updates to make the transition more smooth and cost effective.
Evolving customer clusters at scale
Previous sections describe some aspects on how to manage a large number of Kubernetes clusters. However, there is one more challenge to solve: the evolution of clusters.
Kubernetes is “Linux” in the cloud native era. It keeps on getting updated and is more modular. We need to continuously deliver new versions of Kubernetes in a timely fashion, fix CVEs and do upgrades for the existing clusters, and manage a large number of related components (CSI, CNI, Device Plugin, Scheduler Plugin and many more) for our customers.
Let’s take Kubernetes component management as an example. We first develop a centralized system to register and manage all these pluggable components.
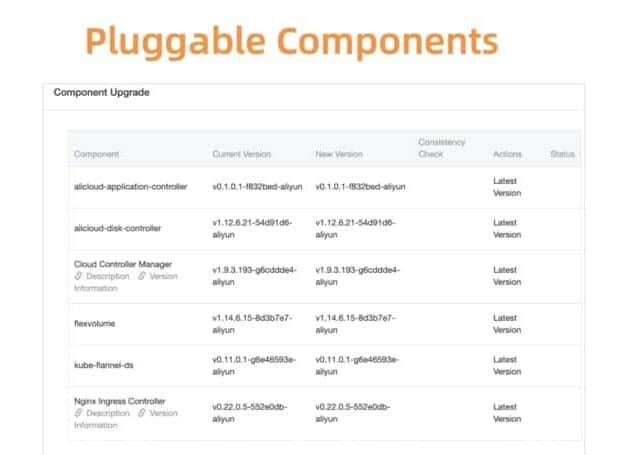
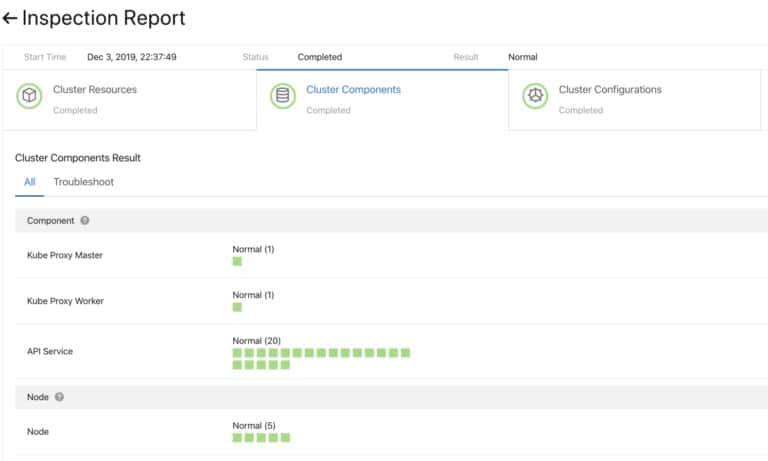
To ensure that the upgrade is successful before moving on, we developed a health checking system for the plugin components and do both per-upgrade check and post-upgrade check.
To upgrade these components fast and reliably, we support continuous deployment with grayscale, pausing and other functions. The default Kubernetes controllers do not serve us well enough for this use case. Thus, we developed a set of custom controllers for cluster components management, including both plugin and sidecar management.
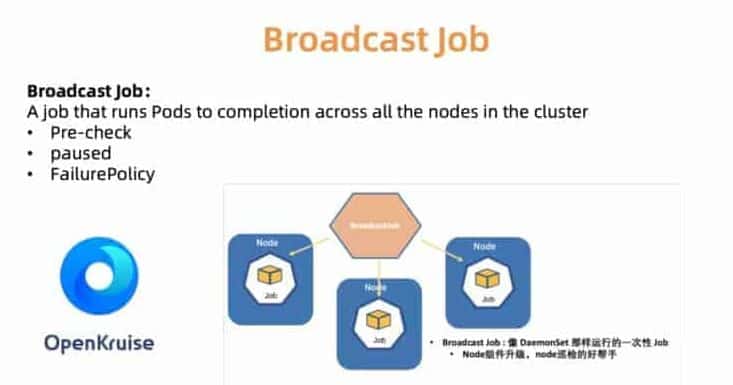
For example, the BroadcastJob controller is designed for upgrading components on each worker machine, or inspecting nodes on each machine. The Broadcast Job runs a pod on each node in the cluster until it ends like DaemonSet. However, DaemonSet always keeps a long running pod on each node, while the pod ends in BroadcastJob. The Broadcast controller also launches pods on newly joined nodes as well to initialize the node with required plugin components. In June 2019, we open sourced cloud native application automation engine OpenKruise we used internally.
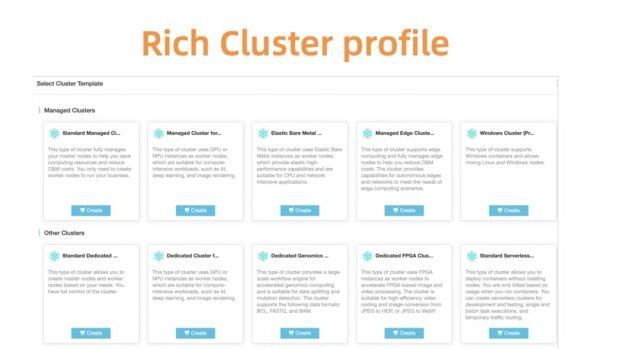
To help our customers with choosing the right cluster configurations, we also provide a set of predefined cluster profiles, including Serverless, Edge, Windows, and Bare Metal setups. As the landscape expands and the needs of our customers grow, we will add more profiles to simplify the tedious configuration process.
Global Observability Across Datacenters
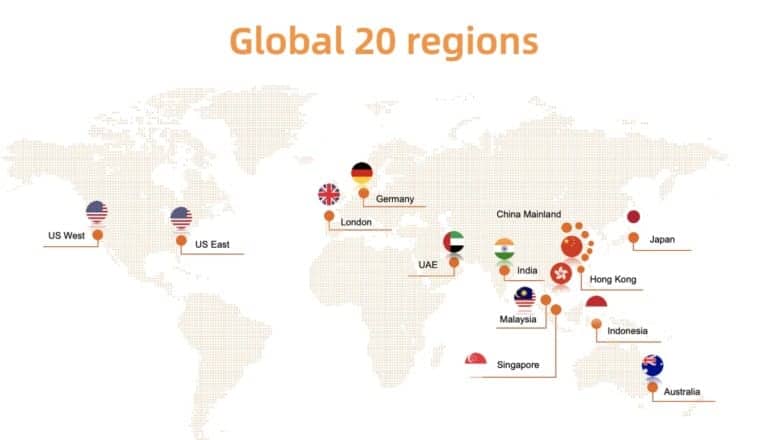
As presented in Figure 9, the Alibaba Cloud Container service has been deployed in 20 regions around the world. Given this kind of scale, one key challenge to ACK is to easily observe status of running clusters so that once a customer cluster runs into trouble, we can promptly react to fix it. In other words, we need to come up with a solution to efficiently and safely collect the real-time statistics from the customer clusters in all regions and visually present the results.
Like many other Kubernetes monitoring solutions, we use Prometheus as the primary monitoring tool. For each meta cluster, the Prometheus agents collects the following metrics:
- OS metrics, such as node resources (CPU, memory, disk, etc.) and network throughput;
- Metrics for meta and guest K8s cluster’s control plane, such as kube-apiserver, kube-controller-manager, and kube-scheduler;
- Metrics from kubernetes-state-metrics and cadvisor;
- etcd metrics, such as etcd disk write time, DB size, peer throughput, etc.
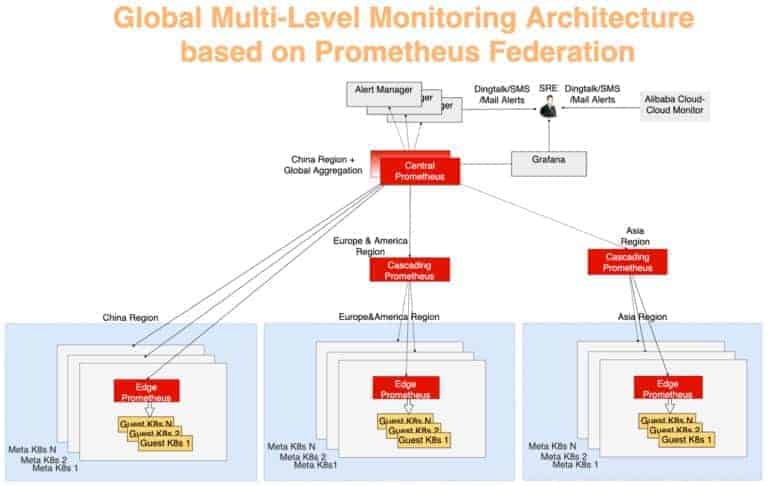
The global stats collection is designed using a typical multi-layer aggregation model. The monitor data from each meta cluster is first aggregated in each region, and the data is then aggregated to a centralized server which provides the global view. To do this, we use Prometheus federation. Each data center has a Prometheus server to collect the data center’s metrics, and the central Prometheus is responsible for aggregating the monitoring data. An AlertManager connects to the central Prometheus and sends various alert notifications, by means of DingTalk, email, SMS, etc. The visualization is done by using Grafana.
In Figure 10, the monitoring system can be divided into three layers:
- Edge Prometheus Layer
This layer is furthest away from the central Prometheus. An edge Prometheus server existing in each meta cluster collects metrics of meta and customer clusters within the same network domain.
- Cascading Prometheus Layer
The function of cascading Prometheus is to collect monitoring data from multiple regions. Cascade Prometheus servers exist in larger regions such as China, Asia, Europe, and America. As the cluster size of each larger region grows, the larger region can be split into multiple new larger regions, and always maintain a cascade Prometheus in each new large region. Using this strategy, we could achieve flexible expansion and evolution of the monitoring scale.
- Central Prometheus Layer
Central Prometheus connects to all cascading Prometheus servers and performs the final data aggregation. To improve reliability, two central Prometheus instances are deployed in different AZs and connect to the same cascading Prometheus servers.
Summary
With the development of cloud computing, Kubernetes based cloud-native technologies continue to promote the digital transformation of the industry. Alibaba Cloud ACK provides secure, stable, and high-performance Kubernetes hosting services. Which has become one of the best carriers for running Kubernetes on the cloud. The team behind Alibaba Cloud strongly believes in open source and its community. In the future, we will share our insights in operating and managing cloud native technologies.