



Guest post by Uma Mukkara, COO, MayaData
Extending cloud native principles to chaos engineering
Faults are bound to happen no matter how hard you test to find them before putting your software into production – clouds and availability zones will have issues, networks will drop, and, yes, bugs will make their presence felt. Resilience is how well a system withstands such faults – a highly resilient system, for example, one built with loosely coupled microservices that can themselves be restarted and scaled easily, overcomes such faults without impacting users. Chaos Engineering is the practice of injecting faults into a system before they naturally occur. Chaos Engineering is now accepted as an essential approach for ensuring that today’s frequently changing and highly complex systems are achieving the resilience required. Through chaos engineering, unanticipated failure scenarios can be discovered and corrected before causing user issues.
Broad adoption has made Kubernetes one of the most important platforms for software development and operations. The word “Cloud Native” is an overloaded term that has been co-opted by many traditional vendors to mean almost anything; even CNCF has allowed the use of the term cloud native to describe technologies that predate the cloud native pattern by, in some cases, decades. For the purposes of this blog, I’d like to use a more technical definition of cloud native; cloud native is here defined as an architecture where the components are microservices that are loosely coupled and, more specifically, are deployed in containers that are orchestrated by Kubernetes and related projects.
In this blog, I would like to introduce a relatively new or less frequently used term called “Cloud Native Chaos Engineering”, defined as engineering practices focused on (and built on) Kubernetes environments, applications, microservices, and infrastructure.
CNCF is, first and foremost, an open-source community (while some projects may not be strictly cloud native, they are all open-source). If Kubernetes had not been open-source, it would not have become the defacto platform for software development and operations. With that in mind, I’d like to stake the claim that Cloud Native Chaos Engineering is necessarily based on open source technologies.
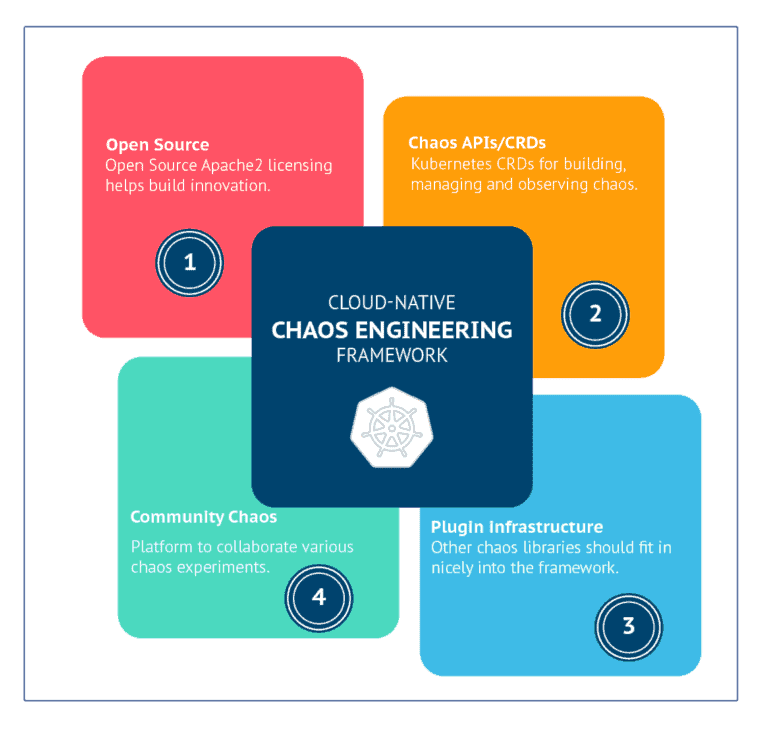
4 principles of a cloud native chaos engineering framework
- Open source – The framework has to be completely open-source under the Apache2 License to encourage broader community participation and inspection. The number of applications moving to the Kubernetes platform is limitless. At such a large scale, only the Open Chaos model will thrive and get the required adoption.
- CRDs for Chaos Management – Kubernetes native – defined here as using Kubernetes CRDs as APIs for both Developers and SREs to build and orchestrate chaos testing. The CRDs act as standard APIs to provision and manage the chaos.
- Extensible and pluggable – One lesson learned why cloud native approaches are winning is that their components can be relatively easily swapped out and new ones introduced as needed. Any standard chaos library or functionality developed by other open-source developers should be able to be integrated into and orchestrated for testing via this pluggable framework.
- Broad Community adoption – Once we have the APIs, Operator, and plugin framework, we have all the ingredients needed for a common way of injecting chaos. The chaos will be run against a well-known infrastructure like Kubernetes or applications like databases or other infrastructure components like storage or networking. These chaos experiments can be reused, and a broad-based community is useful for identifying and contributing to other high-value scenarios. Hence a Chaos Engineering framework should provide a central hub or forge where open-source chaos experiments are shared, and collaboration via code is enabled.
Introduction to Litmus
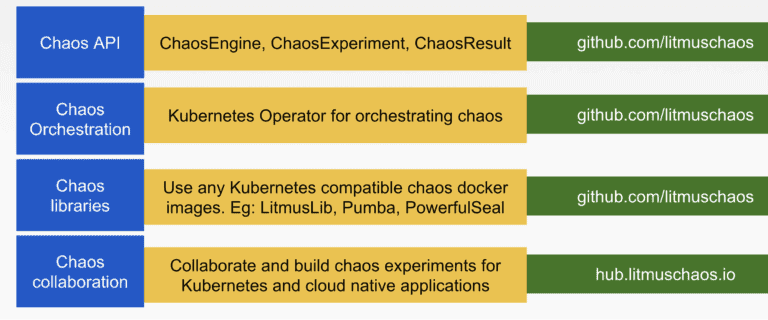
Litmus is a cloud native chaos Engineering framework for Kubernetes. It is unique in fulfilling all 4 of the above parameters. Litmus originally started as a chaos toolset to run E2E pipelines for the CNCF SandBox project OpenEBS – powering, for example, OpenEBS.ci – and has evolved into a completely open-source framework for building and operating chaos tests on Kubernetes based systems. It consists of four main components:
- Chaos CRDs or API
- Chaos Operator
- Chaos libraries and plugin framework
- Chaos Hub
Chaos API
Currently, Litmus provides three APIs:
- ChaosEngine
- ChaosExperiment
- ChaosResult
ChaosEngine:
ChaosEngine CR is created for a given application and is tagged with appLabel. This CR ties one or more ChaosExperiments to an application.
ChaosExperiment: ChaosExperiment CR is created to hold and operate the details of actual chaos on an application. It defines the type of experiment and key parameters of the experiment.
ChaosResult: ChaosResult CR is created by the operator after an experiment is run. One ChaosResult CR is maintained per ChaosEngine. The ChaosResult CR is useful in making sense of a given ChaosExperiment. This CR is used for generating chaos analytics which can be extremely useful – for example when certain components are upgraded between the chaos experiments, and the results need to be easily compared
Chaos Operator
The Litmus Operator is implemented using the Operator-SDK. This operator manages the lifecycle of the chaos CRs. The lifecycle of Litmus itself can be managed using this operator as it follows the lifecycle management API requirements. The chaos operator is also available at operatorhub.io
Chaos libraries and external plugins
The actual injection of chaos is done by chaos libraries or chaos executors. For example, the Litmus project has already built a chaos library called “LitmusLib”. LitmusLib is aware of how to kill a pod, how to introduce a CPU hog, how to hog memory or how to kill a node, and several other faults and degradations. Like LitmusLib, there are other open-source chaos projects like Pumba or PowerfulSeal. The CNCF landscape has more details of various chaos engineering projects. As shown below, the Litmus plugin framework allows other chaos projects to make use of Litmus for chaos orchestration. For example, one can create a chaos chart for the pod-kill experiment using Pumba or PowerfulSeal and execute it via the Litmus framework.
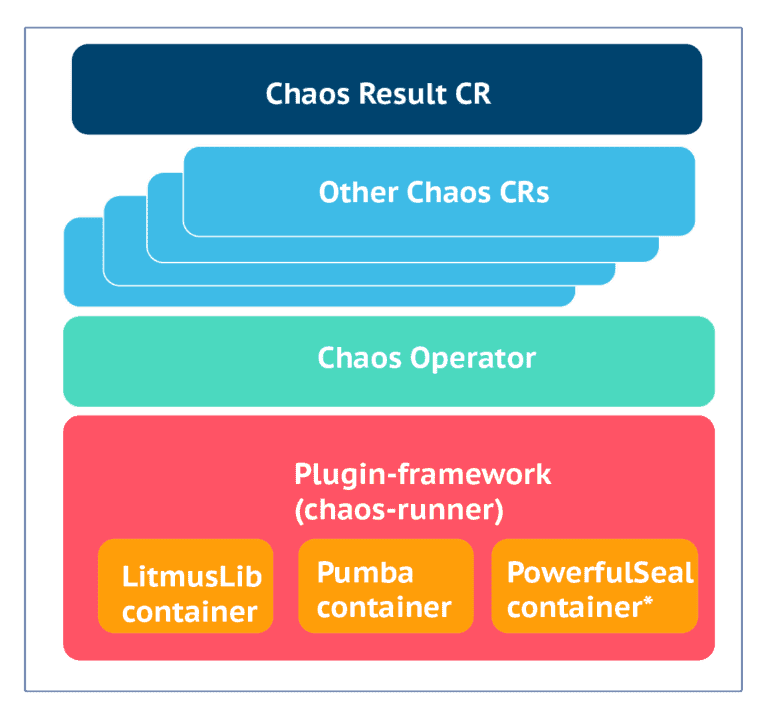
* PowerfulSeal and Pumba are shown as examples.
Chaos Hub
Chaos charts are located at hub.litmuschaos.io. ChaosHub brings all the reusable chaos experiments together. Application developers and SRE share their chaos experiences for others to reuse. The goal of the hub is to have the developers share the failure tests that they are using to validate their applications in CI pipelines to their users, who are typically SREs.
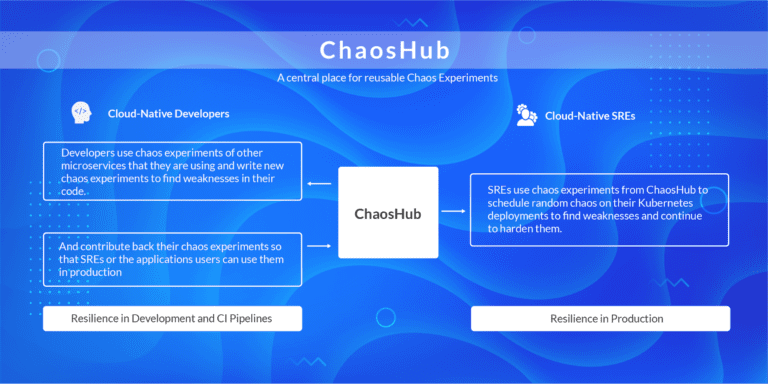
Currently, the chaos hub contains charts for Kubernetes chaos and OpenEBS chaos. We expect to receive more contributions from the community going forward.
Example use cases of Litmus:
The most simple use case of Litmus is application developers using Litmus in the development phase itself. Chaos Engineering has been limited to the Production environment, and lately, we are seeing this practice being adopted in CI pipelines. But with Litmus, chaos testing is possible during development as well. Like Unit Testing, Integration Testing, and Behavior-Driven Testing, Chaos Testing is a test philosophy for developers to carry out the negative test scenarios to test the resiliency of the code before the code is merged to the repository. Chaos testing can be appended very easily to the application, as shown below:

Other use cases of Litmus are for inducing chaos in CI pipelines and production environments.
Summary
With the introduction of chaos operator, chaos CRDs, and chaos hub, Litmus has all the key ingredients of cloud native Chaos Engineering.
Important links:
GitHub: github.com/litmuschaos
Twitter: @litmuschaos
Chaos Charts: hub.litmuschaos.io
Community Slack: #litmus channel on K8S Slack