
Originally published on Medium.
By Tom Gallacher, Staff Engineer at YLD
It doesn’t need to be hard
Getting to grips with Kubernetes can be extremely difficult, with so much information floating around on the seas of the internet, it is sometimes very difficult to find the “core” pieces of information to understand Kubernetes, especially when seeing how dense the information is on kubernetes.io’s concepts pages and documentation. In part one of this “Kubernetes” blog series, we will explore the core concepts of Kubernetes to gain a base level of knowledge, so that we can together demystify Kubernetes.
What is Kubernetes?
Kubernetes provides the fundamentals and building blocks to construct a usable platform for your team to develop and release to. Users can administer their Kubernetes clusters through a graphical user interface as well as an imperative and declarative command line interface, designed to manage the entire life-cycle of your containerised applications and services.
It is possible to scale your applications up and down, perform rolling deployments and manage which services should respond to certain requests. It also provides an extensible framework to develop on to allow your team to extend the core kubernetes primitives to their hearts’ delight! As well as the option to create their own concepts.
As with most frameworks, One of the downsides though is that it is missing a lot of specific pieces of functionality out of the box to be classified as a turn-key solution. In the standard distribution, It doesn’t include a method on how services speak to each other (it doesn’t include a networking component even!) still other distributions exists and it is also possible to build your own.
Containers
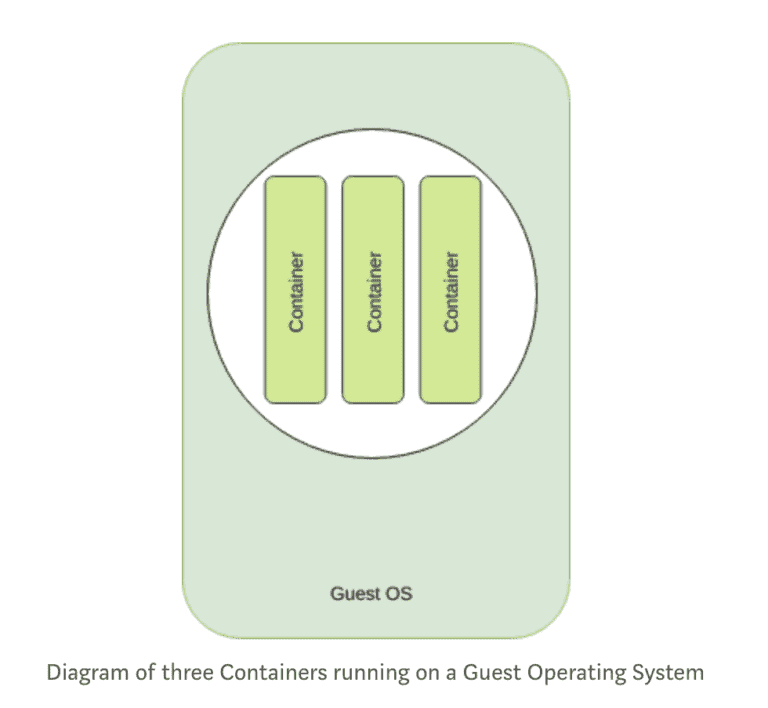
A container is a stand-alone, executable piece of software which includes everything that is required to run it. Such as code, libraries and any external dependencies. It ensures that what is running is identical, even when running in a different environment. This is achieved by isolating the running code from its execution context.
This is achieved in Linux by carving a subset of the Linux Kernel using an API called cgroups. This provides a high amount of isolation from the operating system, but without the runtime performance hit of virtualised environments such as VMWare, KVM, etc.
Pods
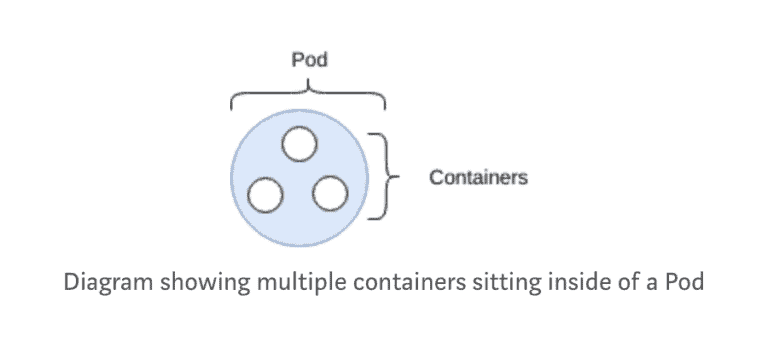
The pod is the most basic of objects that can be found in Kubernetes.
A pod is a collection of containers, with shared storage and network, and a specification on how to run them. Each pod is allocated its own IP address. Containers within a pod share this IP address, port space and can find each other via localhost.
A pod should be seen as an ephemeral primitive.
Replicaset
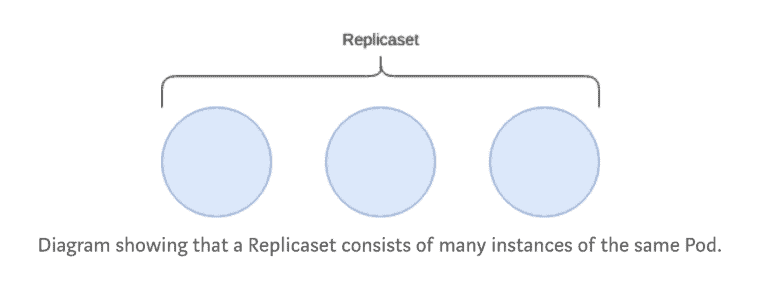
A replicaset runs n number of pods, based on the provided template.
Replicasets are not used directly, however the resource needs to be understood as it is the based building block for building applications on Kubernetes.
Replicasets can (when instructed to) scale up or down the number of pods which are desired.
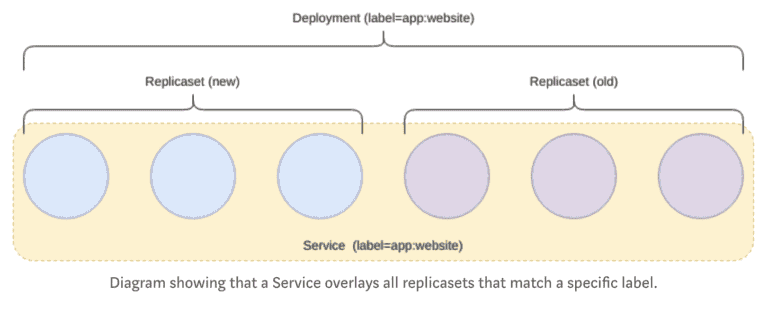
Service
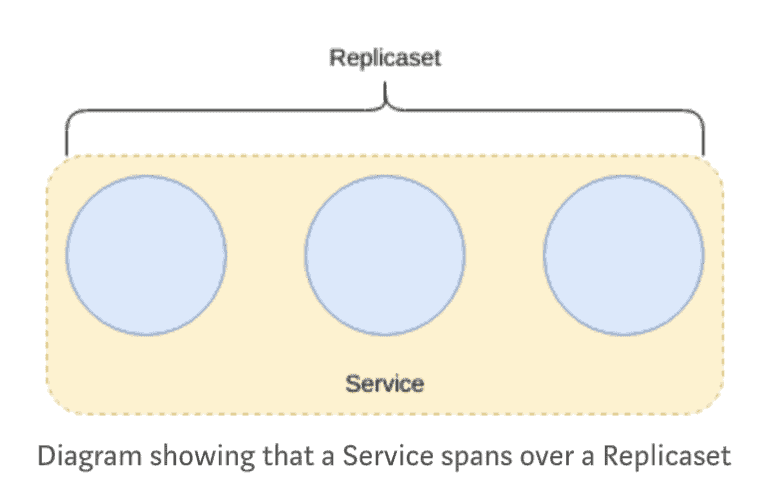
As pods are ephemeral (replicasets enforce this by scaling the number of pods up and down), a problem presents itself; it now becomes almost impossible to reference an individual pod without complex logic to track topology changes.
Services fix this problem by providing an abstraction over Pods and provide an addressable method of communicating with pods.
Services operate on “layer 4” (TCP/UDP over IP) in the OSI model.
Deployment
Deployments manage replicasets and can be used to run rolling upgrades between versions of your applications.
This is the most common resource type that is used and provides an abstraction over replicasets and pods through a single interface.
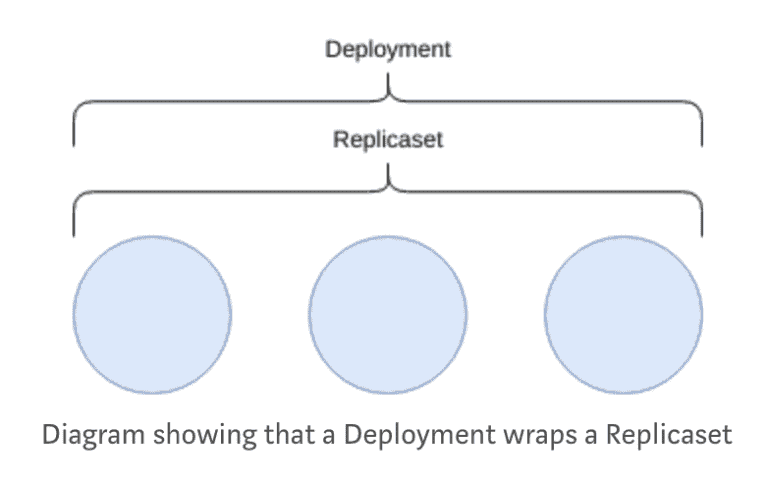
In the case of updating this Deployment, to say, deploy a new version of an application, the deployment controller will create a new replicaset and manage the rolling upgrade from the old to the new.
As of the Kubernetes 1.11 release, deployments do not currently handle rollback automatically.
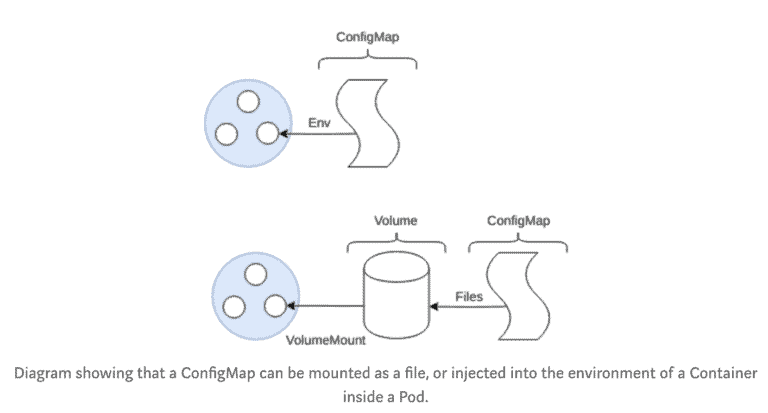
ConfigMap
Well designed applications should try to follow the 12-factor app manifesto, for configuration of your applications, this should store configuration in the “environment”. Although common security practices now state that storing config in the environment can cause accidental leakage of secrets as some applications spew their environment on failure, nevertheless configuration should be stored separately from the built application as configuration changes per environment. (development, staging, production).
ConfigMaps solve the problem by allowing to mount configuration files into a Pod as an Environment variable or as a file system mount.
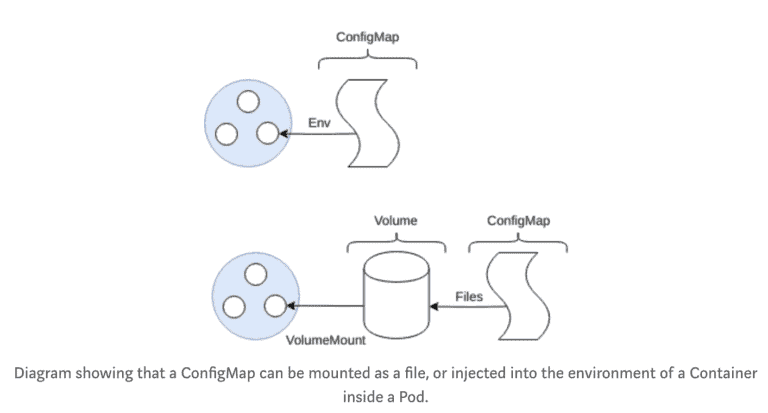
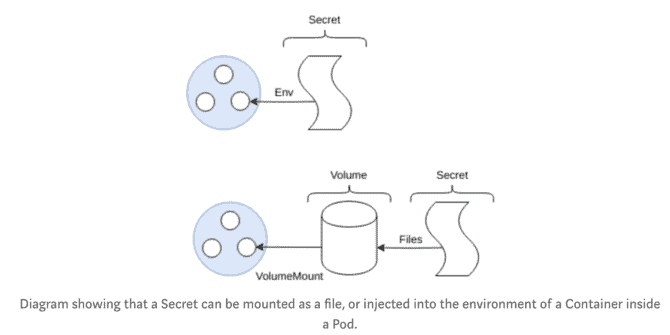
Secrets
Secrets are very similar to ConfigMaps, they are, by their name, “secret” [3][4].
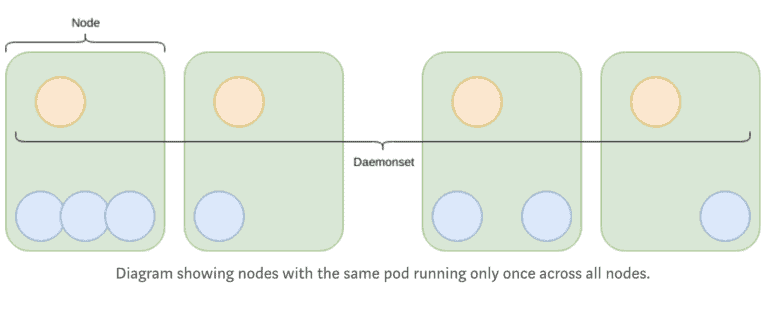
Daemonset
A Daemonset ensures that all Nodes run a specific Pod. This is useful for running something such as a logging agent like fluentd on all Nodes.
It is also possible to ignore certain Nodes by using Taints.
Ingress
In most circumstances, services and pods have IP addresses which are only accessible from within the Kubernetes cluster. With the services being isolated from internet traffic.
“An Ingress is a collection of rules that allow inbound connections to reach the cluster services.”
It can be used for load balancing, to terminate TLS, provides external routable URLs and much more. An ingress is just another Kubernetes resource, however, in most cases, it is required to have an Ingress Controller Such as Nginx or Træfik.
Kubernetes is a platform for automating the orchestration of containers, enabling applications to run at scale on a myriad of platforms, that could contain a mix of processor architectures and operating systems at the discretion of the implementor.
Using these core concepts, Kubernetes can schedule pods onto appropriate Nodes to ensure the greatest possible density of pods, controlled by Kubernetes implementing multiple algorithms such as Bin Packing allowing you to achieve higher hardware capacity utilisation.
[1] https://medium.com/google-cloud/kubernetes-configmaps-and-secrets-68d061f7ab5b
[2] https://medium.com/google-cloud/kubernetes-configmaps-and-secrets-part-2-3dc37111f0dc
[3] https://kubernetes.io/docs/concepts/configuration/secret/
[4] https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
Written by Tom Gallacher — Staff Engineer at YLD.