

By Xingyu Chen, Software Engineer at Alibaba Cloud
Abstract
etcd is an open source distributed kv storage system that has recently been listed as a sandbox incubation project by CNCF. etcd is widely used in many distributed systems. For example, Kubernetes uses etcd as a ledger for storing various meta information inside the cluster. This article first introduces the background of the optimization. It then describes the working mechanism of the etcd internal storage and the specific optimization implementation. The evaluation results are presented in the end.
Background
Due to the large Kubernetes cluster size in Alibaba, there is a remarkably high capacity requirement for etcd which exceeds the supported limit. Therefore, we implemented a solution based on the etcd proxy by dumping the overflowed data to another Redis like KV storage system. Although this solution solves the storage capacity problem, the drawbacks are obvious. The operation delay is much larger than the native etcd since etcd proxy needs to move data around. In addition, operation and maintenance costs are higher due to the use of another KV storage system. Therefore, we’d like to understand the fundamental factor that determines the etcd storage supported limit and try to optimize it for higher capacity limit.
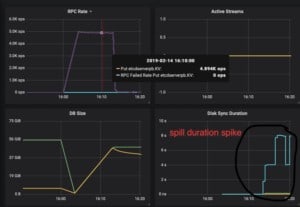
To understand the etcd capacity problem, we first carried out a stress test which keeps injecting data to etcd. When the amount of data stored in etcd exceeded 40GB, after a compact operation, we found that latency of put operation increases significantly and many put operations are timed out. Looking at the monitoring tool closely, we found that the latency increase is due to slow down of the internal spill operation of boltdb (see below for definition) which takes around 8 seconds, much higher than the usual 1ms. The monitoring results are presented in Figure 1. The experiment results are consistent across multiple runs which means once etcd capacity goes beyond 40GB, all read and write operations are much slower than normal which is unacceptable for large scale data applications.
etcd Internal
The etcd storage layer consists of two major parts, one is in-memory btree-based index layer and one boltdb-based disk storage layer. We focus on the underlying boltDB layer in the rest of the document because it is the optimization target. Here is the introduction of boltDB quoted from https://github.com/boltdb/bolt/blob/master/README.md
Bolt was originally a port of LMDB so it is architecturally similar.
Both use a B+tree, have ACID semantics with fully serializable transactions, and support lock-free MVCC using a single writer and multiple readers.
Bolt is a relatively small code base (<3KLOC) for an embedded, serializable, transactional key/value database so it can be a good starting point for people interested in how databases work.
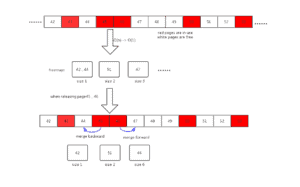
As mentioned above, bolteDB has a concise design, which can be embedded into other software used as a database. For example, etcd has built-in boltDB as the engine for storing k/v data internally. boltDB uses B+ tree to store data, and the leaf node stores the real key/value. It stores all data in a single file, maps it to memory using mmap syscall. It reads and updates the file using write syscall. The basic unit of data is called a page, which is 4KB by default. When page deletion occurs, boltdb does not directly reclaim the storage of the deleted page. Instead, it saves the deleted pages temporarily to form a free page pool for subsequent use. This free page pool is referred to as freelist in boltDB. Figure 2 presents an example of boltDB page meta data.

The red page 43, 45, 46, 50 pages are being used, while the pages 42, 44, 47, 48, 49, 51 are free for later use.
Problem
When user data is frequently written into etcd, the internal B+ tree structure will be adjusted (such as rebalancing, splitting the nodes). The spill operation is a key step in boltDB to persist the user data to the disk, which occurs after the tree structure is adjusted. It releases unused pages to the freelist or requests pages from the freelist to save data.
Through an in-depth investigation of the spill operation, we found the performance bottleneck exists in the following code in the spill operation:
// arrayAllocate returns the starting page id of a contiguous list of pages of a given size.
// If a contiguous block cannot be found then 0 is returned.
func (f *freelist) arrayAllocate(txid txid, n int) pgid {
...
var initial, previd pgid
for i, id := range f.ids {
if id <= 1 {
panic(fmt.Sprintf("invalid page allocation: %d", id))
}
// Reset initial page if this is not contiguous.
if previd == 0 || id-previd != 1 {
initial = id
}
// If we found a contiguous block then remove it and return it.
if (id-initial)+1 == pgid(n) {
if (i + 1) == n {
f.ids = f.ids[i+1:]
} else {
copy(f.ids[i-n+1:], f.ids[i+1:])
f.ids = f.ids[:len(f.ids)-n]
}
...
return initial
}
previd = id
}
return 0
}
The above code suggests that when boltDB reassigns the pages in freelist, it tries to allocate consecutive n free pages for use, and returns the start page id if the consecutive space is found. f.ids in the code is an array that records the id of the internal free page. For example, for the case illustrated in Figure 3, f.ids=[42,44,47,48,49,51]
This method performs a linear scan for n consecutive pages. When there are a lot of internal fragments in freelist, for example, the consecutive pages existing in the freelist are mostly small sizes such as 1 or 2, the algorithm will take a long time to perform if the request consecutive page size is large. In addition, the algorithm needs to move the elements of the array. When there are a lot of array elements, i.e., a large amount of data is stored internally, this operation is very slow.
Optimization
From above analysis, we understand the linear scan of empty pages is not a scalable algorithm. Inspired by Udi Manber, former yahoo’s chief scientist, who once said that the three most important algorithms in yahoo are hashing, hashing and hashing!, we attempt to use multiple hashes to solve the scalability problem.
In our optimization, consecutive pages of the same size are organized by set, and then the hash algorithm is used to map different page sizes to different sets. See the freemaps data structure in the new freelist structure below for example. When user needs a continuous page of size n, we just query freemaps to find the first page of the consecutive space.
type freelist struct {
...
freemaps map[uint64]pidSet // key is the size of continuous pages(span), value is a set which contains the starting pgids of same size
forwardMap map[pgid]uint64 // key is start pgid, value is its span size
backwardMap map[pgid]uint64 // key is end pgid, value is its span size
...
}
In addition, when consecutive pages are released, we need to merge as much as possible into a larger consecutive page. The original algorithm uses a time-consuming approach(O(nlgn)). We optimize it by using hash algorithms as well. The new approach uses two new data structures, forwardMap and backwardMap, which are explained in the comments above.
When a page is released, it tries to merge with the previous page by querying backwardMap and tries to merge with the following page by querying forwardMap. The specific algorithm is shown in the following mergeWithExistingSpan function.
// mergeWithExistingSpan merges pid to the existing free spans, try to merge it backward and forward
func (f *freelist) mergeWithExistingSpan(pid pgid) {
prev := pid - 1
next := pid + 1
preSize, mergeWithPrev := f.backwardMap[prev]
nextSize, mergeWithNext := f.forwardMap[next]
newStart := pid
newSize := uint64(1)
if mergeWithPrev {
//merge with previous span
start := prev + 1 - pgid(preSize)
f.delSpan(start, preSize)
newStart -= pgid(preSize)
newSize += preSize
}
if mergeWithNext {
// merge with next span
f.delSpan(next, nextSize)
newSize += nextSize
}
f.addSpan(newStart, newSize)
}
The new algorithm is illustrated in Figure 3. When page 45, 46 are released, the algorithm tries to merge with page 44, and then merge with pages 47, 48, 49 to form a new free page span.
The above algorithm is similar to the segregated freelist algorithm used in memory management. It reduces the page allocation time complexity from O(n) to O(1), and the release from O(nlgn) to O(1).
Evaluation
The following tests are conducted in a one-node etcd cluster in order to exclude other factors such as the network. The test simulates 100 clients put 1 million kv pairs to etcd at the same time. The key/value contents are random, and we limit the throughput to 5000 op/s. The test tool is the etcd official benchmark tool. The latency results are presented.
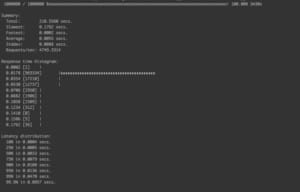
Performance of using new segregated hashmap
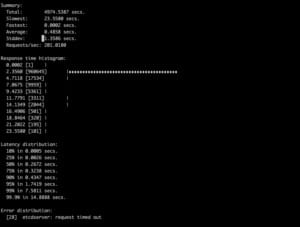
Performance of old algorithm
There are some timeouts that have not completed the test,
Comparison
The less time, the better performance. The performance boost factor is the run time normalized to the latest hash algorithm.
| Scenario | Completion Time | Performance boost |
| New hash algorithm | 210s | baseline |
| Old array algorithm | 4974s | 24x |
The new algorithm’s performance will be even better in larger scale scenarios.
Conclusion
The new optimization reduces time complexity of the internal freelist allocation algorithm in etcd from O(n) to O(1) and the page release algorithm from O(nlgn) to O(1), which solves the performance problem of etcd under the large database size. Literally, the etcd’s performance is not bound by the storage size anymore. The read and write operations when etcd stores 100GB of data can be as quickly as storing 2GB. This new algorithm is fully backward compatible, you can get the benefit of this new algorithm without data migration or data format changes! At present, the optimization has been tested repeatedly in Alibaba for more than 2 months and no surprise happened. It has been contributed to the open source community link. You can enjoy it in the new versions of boltdb and etcd.
About the Author
Xingyu Chen (github id: WIZARD-CXY) is a software engineer works in Alibaba Cloud. He is the owner of the etcd cluster management in Alibaba and an active etcd/kubernetes contributor. His main interest is the performance and stability of etcd cluster.