
Today’s post is by Reda Benzair, CNCF Ambassador and VP of Engineering at Streamroot. This was originally posted on the Streamroot techdeveloper’s blog.
In this post, I’d like to share some high-level takeaways for engineering managers and backend teams to help them successfully scale their operations while avoiding some of the most common pitfalls and short-sighted decisions.
This article follows up on a first post published by Jordan Pittier, lead backend engineer at Streamroot, and a presentation of our journey at HighLoad Moscow this past November. These shared our experience and the challenges we faced throughout the process of moving from a VM-based to a container-based architecture and migrating our infrastructure to Kubernetes running on Google Cloud.
Introduction and context
Let me start by giving you a little bit of context about Streamroot and why we take the time to tune our Kkubernetes Engine architecture not only to scale but also to make our architecture more resilient.
Streamroot is a technology provider that serves major content owners – media groups, television networks, and video platforms. Our peer-to-peer video delivery solution offers broadcasters improved quality and lower costs, and works in tandem with their existing CDN infrastructure.
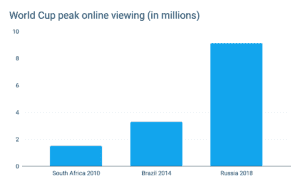
One of our (and our customers’) biggest challenges last year was scaling to the record-breaking audiences of the FIFA World Cup. The 2018 World Cup proved to be the largest live event of all time, with Akamai registering 22 Tbps on peak and more than doubling the previous traffic record set by the Super Bowl (1).
Streamroot delivered the World Cup for TF1, the largest private broadcaster in France, as well as national television networks in South America. To be able to serve our customers at this scale, we needed to scale our own Kubernetes engines and be able to scale faster. We needed to:
- Handle massive traffic, with hundreds of thousands of requests per minute to our backend
- Scale to huge spikes in minutes, at the beginning of each World Cup game
- Ensure a 100% fail-proof, entirely resilient, robust backend able to withstand any failure. As a sports lover, I know that it is completely unacceptable to have even two minutes of downtime during live sports…
And last but not least, we had to do all of this with a startup scale team of only a few backend engineers…
If you are interested in our scaling journey over the past few months and you wish to dig more into the technical details, you can have a look at our talk at the HighLoad++ conference in Moscow made by Jordan Pittier and Nikolay Rodionov and our slides here.
Takeaway # 1: new things are not always good things: tread lightly with cloud native technology.
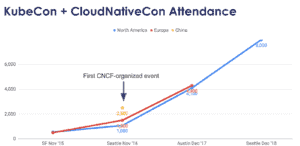
Kubernetes has seen exponential growth since joining the Cloud Native Computing Foundation (CNCF) and there is increasing interest in this complex solution, which is a combination of open-source cloud native technologies. Last December, tThe CNCF’s KubeCon+CloudNativeCon gathered more than 8,000 attendees from all over the world in Seattle.
Kubernetes is one of the Cloud Native technology components. Many other components also exist, some part of the CNCF foundation (https://landscape.cncf.io/) and some outside the foundation, such as Istio.
Cloud native technology is still young, and there are various new components springing up in a different field every month: storage, security, service discovery, package management, etc.
Our advice: use these new components with caution, and keep it simple (, stupid). These technologies are new, sometimes still rough around the edges, and are evolving at an incredible pace. There is no point in trying to use all the latest shiny technologies, especially in production, unless these are motivated by a real need. Even if you have a large team of talented engineers, you need to take into consideration the cost (in resources and time) to maintain, operate and debug these new technologies which can sometimes lack stability.
As a manager and CNCF ambassador, I recommend following the CNCF classification (https://www.cncf.io/projects/) to select the native components withhaving a sufficient maturity level. The CNCF-defined criteria include a rate of adoption, longevity and whether the open-source project can be relied upon to build production tools. Today, Streamroot harnesses only 3 projects (Kubernetes, Prometheus and Envoy), which are at these maturity levels and have “graduated” according to the CNCF foundation. A large number of the components out there are still at the incubating or sandbox stages. You can still use these, but keep in mind that you will face some risks: stability, bugs, limited community, learning curve, etc.
Most importantly, understand that even if there may be widespread confidence that all native projects in the incubating or the sandbox stage may be able to fill in the blanks and become mature for production, it is also a question of not multiplying the complexity of your architecture. Make sure to ask yourself the following before adding any new components from the CNCF or outside the CNCF:
- Do I really need this component?
- Am I solving a real problem in my infrastructure?
- Are my engineers going to be able to handle it now and in the long run?
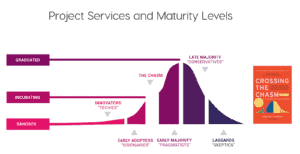
Figure: CNCF classification
Takeaway # 2: control your costs
When starting a significant project like moving your service from a VM-based to a container-based architecture supported by Kubernetes, your primary focus is likely not cost but having a successful migration. While the cost of your backend may not be an immediate or medium-term concern, it is something to take into account from day one. I highly recommend that you track as early as possible your Kubernetes Engine scaling costs for the following reasons:
- To have a clear vision of your resource usage and the efficiency of your software. A backend team’s primary concern is delivery, and it is often difficult from a management perspective to relay the importance of efficient software and resource usage.
- To discover room for improvement in your architecture. Triangulating the information from monitoring and cost progression helped us identify improvements in our architecture. In particular, we were able to reduce our costs by 22% by simply better adapting our instances to our usage, and understand better how the resources are used and consumed.
- To take advantage of volume-based cost savings. Most cloud providers, including Google Cloud and Amazon AWS, offer interesting discounts for commited instances. Don’t hesitate to use infrastructure cost accounting (and reduction) to your benefit. Once you reach a certain spend, even a 10% cost reduction can add a few thousand, or even dozens of thousands of dollars back into your budget, which can be used to send your teams to conferences, or even hire a new resource to build your product faster!
To illustrate my third point, GCP provides a sustained use discounts option that offers significant discounts for long term committed instances. For example, if you commit a resource for an entire year, you get a flat 30% discount (for once, it’s actually nice to see the bill at the end of the month!). Those discounts can run up to 57% (!) for a 3-year commitment. Of course, I suggest waiting at least 6 months before committing anything, in order to identify the average CPU & RAM resources you are using at minimum.
Don’t fear! You do not need to be an expert in corporate finance or billing to track your costs effectively. For example, you can enable cost alerting per project by default if you would like to track your monthly usage, and then use the CSV export to feed into your favorite spreadsheet tool. Alternatively, on GCP, you can enable the Bigquery Billing Export option for a daily export of all of the details of your resource consumption. Then, take a few minutes to build a simple dashboard with an SQL export or Excel (do not forget to ask your engineers to set the resource labels correctly in order to identify the different lines).
Takeaway # 3: isolate and keep your production safe
Many blogs and articles recommend that you use only one K8s cluster but use different namespaces for your different environments (Dev, Staging & Production for instance). Namespaces are a very powerful feature that can help you organize your Kubernetes resources and increase the velocity of your teams. But that kind of setup doesn’t come easily: you need to make sure to have a polished CI/CD environment in place, to avoid any interferences between your staging & prod environments, as well as “stupid” mistakes like deploying the wrong component in the wrong namespace. When reading this, you might think: “sure, but we have a super smart team, so we’ll be able to handle it.” Stop right there: everyone makes stupid mistakes, and the more stupid the mistake is, the more chance it has to happen… So unless you want to spend your most stressful days extinguishing fires in production because you pushed a staging build there, you MUST spend a few weeks building a top notch CI/CD workflow if go with the namespaces option.
On our side, we chose another option to keep our environments separated: we decided to create fully autonomous clusters for our staging and production environments. This eliminates all risks of human error and security failure propagation, as both clusters are completely isolated. The downside of this approach is that it increases your fixed costs: you need more machines to keep both clusters up and running. But the safety and peace of mind it brings is more than worth it for us.
Moreover, you can mitigate the cost overhead by using ephemeral instances with GCP, which are 80% less expensive than normal instances. Of course this comes with a catch: those instances can get shut down at any time if Google Cloud needs them for another customer. But as we use them for our staging environment only, losing one machine doesn’t really impact us, and we even learned to use it at our advantage. It is for us the perfect test to see how our architecture reacts to a random failure of one of our components: a sort of perfectly unpredictable red team trying to destroy the system, given you for free by Google Cloud
Takeaway # 4: unify and automate your workflow from the start
When you start a new project, the last thing you want to think about is how you will be sharing your code with other developers, or how you will be pushing your builds between production and staging when you need to do an emergency rollback. It’s normal and very wise: there’s no need to over-optimise before you have actually built anything that you can show to the world. But on the other hand, it’s a common mistake to let these questions sit latent for eternity because you don’t have time and need to release the next feature that is going to make your product finally cross the chasm and magically bring millions of users. My advice on this would be to take the time to create a simple and efficient workflow as early as possible.
First, as soon as you start collaborating with other people, you should take a step back to create a unified and easily transferable development environment. 10 years ago, that wasn’t an easy feat: you needed to configure special VMs on everyone’s computers, or hack together conversions between your Mac & Windows users. It was a real nightmare and caused a lot of unnecessary and undebuggable issues. Today, thanks to containerization tools like Docker, it can be done in less than a few days, so why not implement it from the start? This will greatly simplify the lives of all your developers and make the onboarding of new employees easy and straightforward. It’s a very small investment for all the weeks of debugging and setting up that you will save.
Second, as soon as you have production traffic, you should think about creating a simple but efficient QA/CI/CD workflow. No need to over engineer too early, but we are very lucky to live in the golden age of automation & CI tools that give you the possibility to implement an automated first class CI & CD without trouble. The list is long of tool CI compliant with kubernetes API, example in version 10.1 GitLab introduced integration with Kubernetes or Jenkins X. Most of those companies offer low cost plans for small scale projects, and free plans for open-source projects, so you really don’t have any excuse not to use them! It’s not rocket science, and will save you both time, energy, and numerous headaches, and make your developers’ life a lot easier!
Summing it all up
Kubernetes and Cloud Native offer great technologies that bring simplicity and support to build a scalable and resilient solution on the cloud. It won’t be long until we take Kubernetes for granted as a ubiquitous part of the cloud technology as we do technologies like Linux and TCP/IP today.
Thanks to our successful migration to these services, we were able to durably scale our infrastructure to World Cup audiences and beyond. During the biggest sporting event in history, we delivered more than 1.2 Tbps of traffic with zero minutes of downtime – and all of this with a team of only two backend engineers. We are now able to handle video streams with millions of viewers, with tens of thousands of new requests arriving per second on peak.
Thanks to the best practices that I have discussed in this article, we were not only able to achieve our short-term delivery goals but also the long-term scalability of our infrastructure from an architecture, cost and resource perspective. To sum up our key takeaways:
- Use Kubernetes and cloud native carefully and pragmatically, when the tool corresponds to a real need.
- Think about the future today, whether it comes to cost, separating environments or putting in place automated workflows. The more effectively these challenges are incorporated into your project from day one, the less time and fewer resources you will waste adjusting later on when these considerations become mission critical.
As a startup, we are always striving to keep on improving our tech and workflows, and after all the lessons learned during our scaling journey, we are looking forward to tackling our next challenge: building a multi-cloud architecture!
- Akamai measured a peak volume of over 22 Tbps. That’s 3 times the peak they saw in the 2014 edition