by Yoav Landman, CTO, JFrog
What’s in a function?
Creating serverless applications is a multi-step process. One of the critical steps in this process is packaging the serverless functions you want to deploy into your FaaS (Function as a Service) platform of choice.
Before a function can be deployed it needs two types of dependencies: direct function dependencies and runtime dependencies. Let’s examine these two types.
Direct function dependencies – These are objects that are part of the function process itself and include:
- The function source code or binary
- Third party binaries and libraries the function uses
- Application data files that the function directly requires
Runtime function dependencies
– This is data related to the runtime aspects of your function. It is not directly required by the function but configures or references the external environment in which the function will run. For example:
- Event message structure and routing setup
- Environment variables
- Runtime binaries such as OS-level libraries
- External services such as databases, etc.
For a function service to run, all dependencies, direct and runtime, need to be packaged and uploaded to the serverless platform. Today, however, there is no common spec for packaging functions. Serverless package formats are vendor-specific and are highly dependent on the type of environment in which your functions are going to run. This means that, for the most part, your serverless applications are locked-down to a single provider, even if your function code itself abstracts provider-specific details.
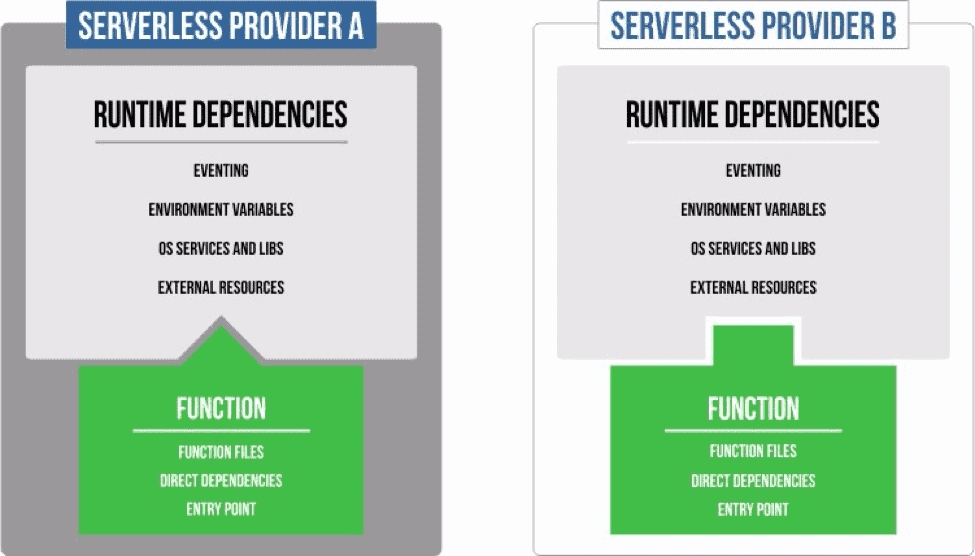
This article explores the opportunity to create a spec for an open and extensibile “Function Package” that enables the deployment of a serverless function binary, along with some extra metadata, across different FaaS vendors.
Function runtime environments
When looking at today’s common runtime FaaS providers, we see two mainstream approaches for running functions: container function and custom function runtimes. Let’s have a closer look at each type.
Container function runtimes
This method uses a container-based runtime, such as Kubernetes, and is the common runtime method for on-prem FaaS solutions. As its name suggests, it usually exposes container runtime semantics to users at one level or another. Here’s how it works.
A container entry-point is used as a function, together with an eventing layer, to invoke a specific container with the right set of arguments. The function is created with docker buildor any other image generator to create an OCI container image as the final package format.
Examples of serverless container-based runtimes include: Google’s Knative, Bitnami’s Kubeless, Iguazio’s Nuclio and Apache’s OpenWhisk.
The main issue with container functions is that developing a function often requires understanding of the runtime environment; developers need to weave their function into the container. Sometimes this process is hidden by the framework, but it is still very common for the developer to need to write a Dockerfile for finer control over operating system-level services and image structure. This leads to high coupling of the function with the runtime environment.
Custom function runtimes
Custom function runtime are commonly offered by cloud providers. They offer a “clean” model where functions are created by simply writing handler callbacks in your favorite programming language. In contrast to container-based functions, runtime details are left entirely to the cloud provider (even in cases where, behind-the-scenes, the runtime is based on containers).
Examples of serverless custom function runtimes are: AWS Lambda, Azure Functions and Google Cloud Functions.
Custom runtime environments use a language-centric model for functions. Software languages already have healthy packaging practices (such as Java jars, npm packages or Go modules). Still, no common packaging format exists for their equivalent functions. This creates a cloud-vendor lock-in. Some efforts have been made to define a common deployment model, (such as AWS Serverless Application Model (SAM) and the open-source Serverless Framework), but these models assume a custom binary package already exists or they may include the process of building it to each cloud provider standards.
The need for a function package
To be able to use functions in production, we need to use stable references to them to enable repeatability in deploying, upgrading and rolling back to a specific function version. This can be achieved with an immutable, versioned, sealed package that contains the function with all its direct dependencies.
Container images may meet these requirements because they offer a universal package format. However, there’s a side effect of “polluting” the function by tightly coupling it with details of the container runtime. Custom runtimes also exhibit coupling with their function packages. While they offer clean functions, they use proprietary package formats that mix the function dependencies with the runtime dependencies.
What we need is a clear separation: a clean function together with its dependencies in a native “Function Package” separate from external definitions of runtime-specific dependencies. This separation would allow us to take a function and reuse it across different serverless platforms, only adding external configuration as needed.
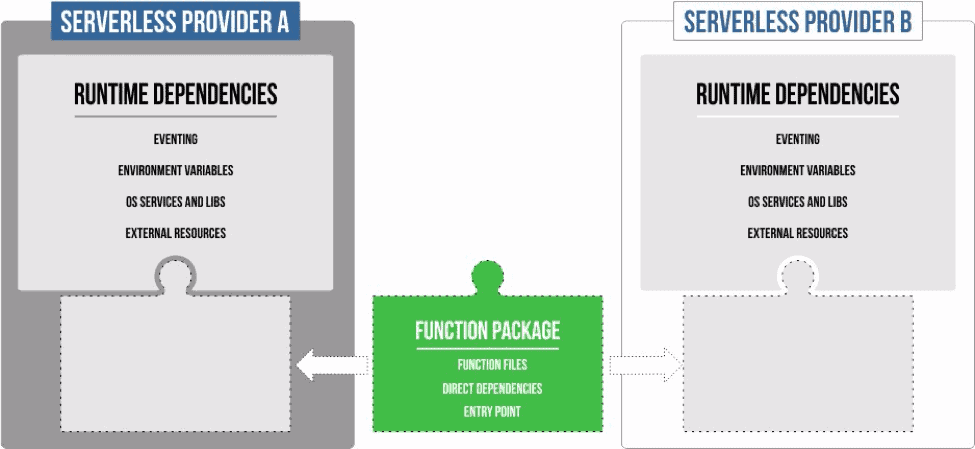
Getting a function to run
Let us reexamine for a moment the steps required to build and run a container-based function. We can look at this as a four step process:
| (1) Packaging | Build a container image together with (direct + runtime) function dependencies and entry point definition |
| (2) Persisting | Push the image to a container registry so that we have a stable reference to it |
| (3) Installing | Pull the image to the runtime and configure it according to runtime-specific dependencies |
| (4) Running | Accept function events at the defined entry point |
This process works pretty well for container runtimes. We can try to formulate it into a more generalized view:
| (1) Packaging | Build a function package that contains its direct dependencies (or references to them) and entry point definition |
| (2) Persisting | Upload the package to a package registry |
| (3) Installing | Download the package (and its direct dependencies) to the runtime and configure runtime-specific dependencies |
| (4) Running | Accept function events at the defined entry point |
Creating a function package
This general process can be applied across many serverless providers! Developers only need to worry about creating a clean Function Package and keeping it persistent. Runtime configuration can be provided upon installation and can be vendor-specific.
A Function Package would contain:
- Function files – in source code or binary format
- Direct dependencies – libraries and data files
- Entry point definition
The experience for the developer is simple and programming-focused, and therefore we can create spec “profiles” that map to a specific language type. For example:
| Java Profile | Golang Profile | Docker Profile | |
| Function files | JAR file | Go module source files | Build file references to generic files run by the entry-point |
| Direct dependencies | Generated pom file for the jar with a full flat list of dependencies + data files | go.mod file containing the dependencies + data files | Build file references to base image + other service files and data |
| Entry point definition | Class reference | “main” package reference | Build file references to image entry point |
What about dependencies?
A function package does not necessarily have to physically embed binary dependencies if they can be reliably provided by the runtime prior to installation. Instead, only references to dependencies could be declared. For example, external JAR coordinates declared in a POM file, or go packages declared in a go.modfile. These dependencies would be pulled by the runtime during installation – similar to how a container image is pulled from a docker registry by function runtimes.
By using stable references, we guarantee repeatability and reuse. We also create lighter packages that allow for quicker and more economic installation of functions by dependencies from a registry closer to the runtime, not having to reupload them each time.
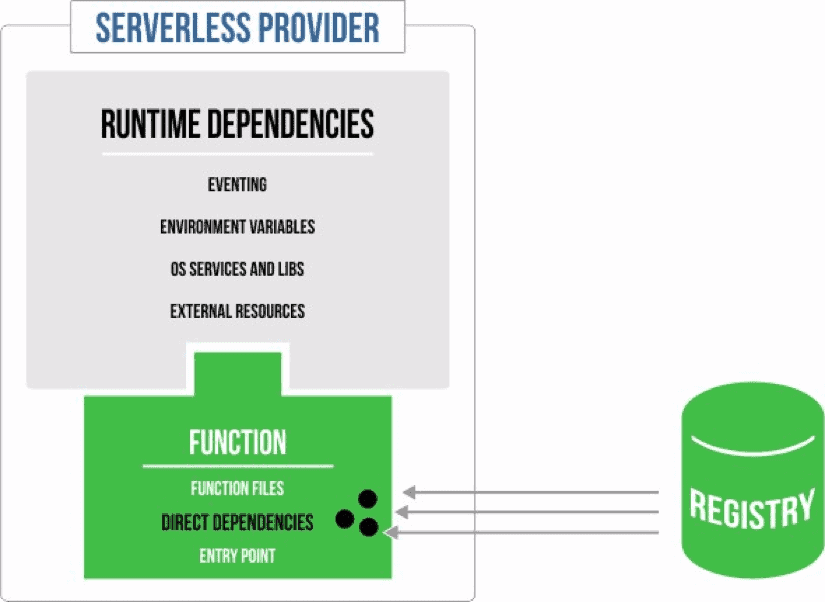
Summary
Creating profiles for common runtime languages allows functions to be easily moved across different serverless FaaS providers, adding vendor-specific information pertaining to runtime configuration and eventing only at the installation phase. For application developers, this means they can avoid vendor lock-in and focus on writing their applications’ business logic without having to become familiar with operational aspects. This goal can be achieved more quickly by creating shareable Function Packages as a CNCF Serverless spec. If you are interested in discussing more – let’s talk!