

In this blog series originally posted on Heptio, Joe Beda (CTO of Heptio and starter of Google Compute Engine, Kubernetes and Google Container Engine) dives into some of the inner workings of Kubernetes.
Meet Joe Beda in-person and catch his presentation “The Road to More Usable Kubernetes” at KubeCon + CloudNativeCon North America, December 6-8 in Austin.
Core Kubernetes: Jazz Improv over orchestration
By Joe Beda, CTO of Heptio
This is the first in a series of blog posts that details some of the inner workings of Kubernetes. If you are simply an operator or user of Kubernetes you don’t necessarily need to understand these details. But if you prefer depth-first learning and really want to understand the details of how things work, this is for you.
This article assumes a working knowledge of Kubernetes. I’m not going to define what Kubernetes is or the core components (e.g. Pod, Node, Kubelet).
In this article we talk about the core moving parts and how they work with each other to make things happen. The general class of systems like Kubernetes is commonly called container orchestration. But orchestration implies there is a central conductor with an up front plan. However, this isn’t really a great description of Kubernetes. Instead, Kubernetes is more like jazz improv. There is a set of actors that are playing off of each other to coordinate and react.
We’ll start by going over the core components and what they do. Then we’ll look at a typical flow that schedules and runs a Pod.
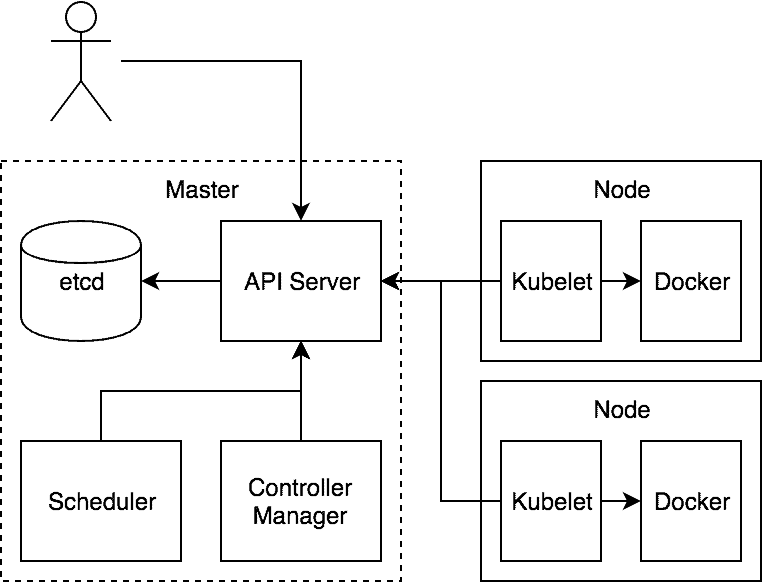
Datastore: etcd
etcd is the core state store for Kubernetes. While there are important in-memory caches throughout the system, etcd is considered the system of record.
Quick summary of etcd: etcd is a clustered database that prizes consistency above partition tolerance. Systems of this class (ZooKeeper, parts of Consul) are patterned after a system developed at Google called chubby. These systems are often called “lock servers” as they can be used to coordinate locking in a distributed systems. Personally, I find that name a bit confusing. The data model for etcd (and chubby) is a simple hierarchy of keys that store simple unstructured values. It actually looks a lot like a file system. Interestingly, at Google, chubby is most frequently accessed using an abstracted File interface that works across local files, object stores, etc. The highly consistent nature, however, provides for strict ordering of writes and allows clients to do atomic updates of a set of values.
Managing state reliably is one of the more difficult things to do in any system. In a distributed system it is even more difficult as it brings in many subtle algorithms like raft or paxos. By using etcd, Kubernetes itself can concentrate on other parts of the system.
The idea of watch in etcd (and similar systems) is critical for how Kubernetes works. These systems allow clients to perform a lightweight subscription for changes to parts of the key namespace. Clients get notified immediately when something they are watching changes. This can be used as a coordination mechanism between components of the distributed system. One component can write to etcd and other componenents can immediately react to that change.
One way to think of this is as an inversion of the common pubsub mechanisms. In many queue systems, the topics store no real user data but the messages that are published to those topics contain rich data. For systems like etcd the keys (analogous to topics) store the real data while the messages (notifications of changes) contain no unique rich information. In other words, for queues the topics are simple and the messages rich while systems like etcd are the opposite.
The common pattern is for clients to mirror a subset of the database in memory and then react to changes of that database. Watches are used as an efficient mechanism to keep that cache up to date. If the watch fails for some reason, the client can fall back to polling at the cost of increased load, network traffic and latency.
Policy Layer: API Server
The heart of Kubernetes is a component that is, creatively, called the API Server. This is the only component in the system that talks to etcd. In fact, etcd is really an implementation detail of the API Server and it is theoretically possible to back Kubernetes with some other storage system.
The API Server is a policy component that provides filtered access to etcd. Its responsibilities are relatively generic in nature and it is currently being broken out so that it can be used as a control plane nexus for other types of systems.
The main currency of the API Server is a resource. These are exposed via a simple REST API. There is a standard structure to most of these resources that enables some expanded features. The nature and reasoning for that API structure is left as a topic for a future post. Regardless, the API Server allows various components to create, read, write, update and watch for changes of resources.
Let’s detail the responsibilities of the API Server:
- Authentication and authorization. Kubernetes has a pluggable auth system. There are some built in mechanisms for both authentication users and authorizing those users to access resources. In addition there are methods to call out to external services (potentially self-hosted on Kubernetes) to provide these services. This type of extensiblity is core to how Kubernetes is built.
- Next, the API Server runs a set of admission controllers that can reject or modify requests. These allow policy to be applied and default values to be set. This is a critical place for making sure that the data entering the system is valid while the API Server client is still waiting for request confirmation. While these admission controllers are currently compiled in to the API Server, there is ongoing work to make this be another extensibility mechanism.
- The API server helps with API versioning. A critical problem when versioning APIs is to allow for the representation of the resources to evolve. Fields will be added, deprecated, re-organized and in other ways transformed. The API Server stores a “true” representation of a resource in etcd and converts/renders that resource depending on the version of the API being satisfied. Planning for versioning and the evolution of APIs has been a key effort for Kubernetes since early in the project. This is part of what allows Kubernetes to offer a decent deprecation policy relatively early in its lifecycle.
A critical feature of the API Server is that it also supports the idea of watch. This means that clients of the API Server can employ the same coordination patterns as with etcd. Most coordination in Kubernetes consists of a component writing to an API Server resource that another component is watching. The second component will then react to changes almost immediately.
Business logic: Controller manager and scheduler
The last piece of the puzzle is the code that actually makes the thing work! These are the components that coordinate through the API Server. These are bundled into separate servers called the Controller Manager and the Scheduler. The choice to break these out was so they couldn’t “cheat”. If the core parts of the system had to talk to the API Server like every other component it would help ensure that we were building an extensible system from the start. The fact that there are just two of these is an accident of history. They could conceivably be combined into one big binary or broken out into a dozen+ separate servers.
The components here do all sorts of things to make the system work. The scheduler, specifically, (a) looks for Pods that aren’t assigned to a node (unbound Pods), (b) examines the state of the cluster (cached in memory), (c) picks a node that has free space and meets other constraints, and (d) binds that Pod to a node.
Similarly, there is code (“controller”) in the Controller Manager to implement the behavior of a ReplicaSet. (As a reminder, the ReplicaSet ensures that there are a set number of replicas of a Pod Template running at any one time) This controller will watch both the ReplicaSet resource and a set of Pods based on the selector in that resource. It then takes action to create/destroy Pods in order to maintain a stable set of Pods as described in the ReplicaSet. Most controllers follow this type of pattern.
Node agent: Kubelet
Finally, there is the agent that sits on the node. This also authenticates to the API Server like any other component. It is responsible for watching the set of Pods that are bound to its node and making sure those Pods are running. It then reports back status as things change with respect to those Pods.
A typical flow
To help understand how this works, let’s work through an example of how things get done in Kubernetes.
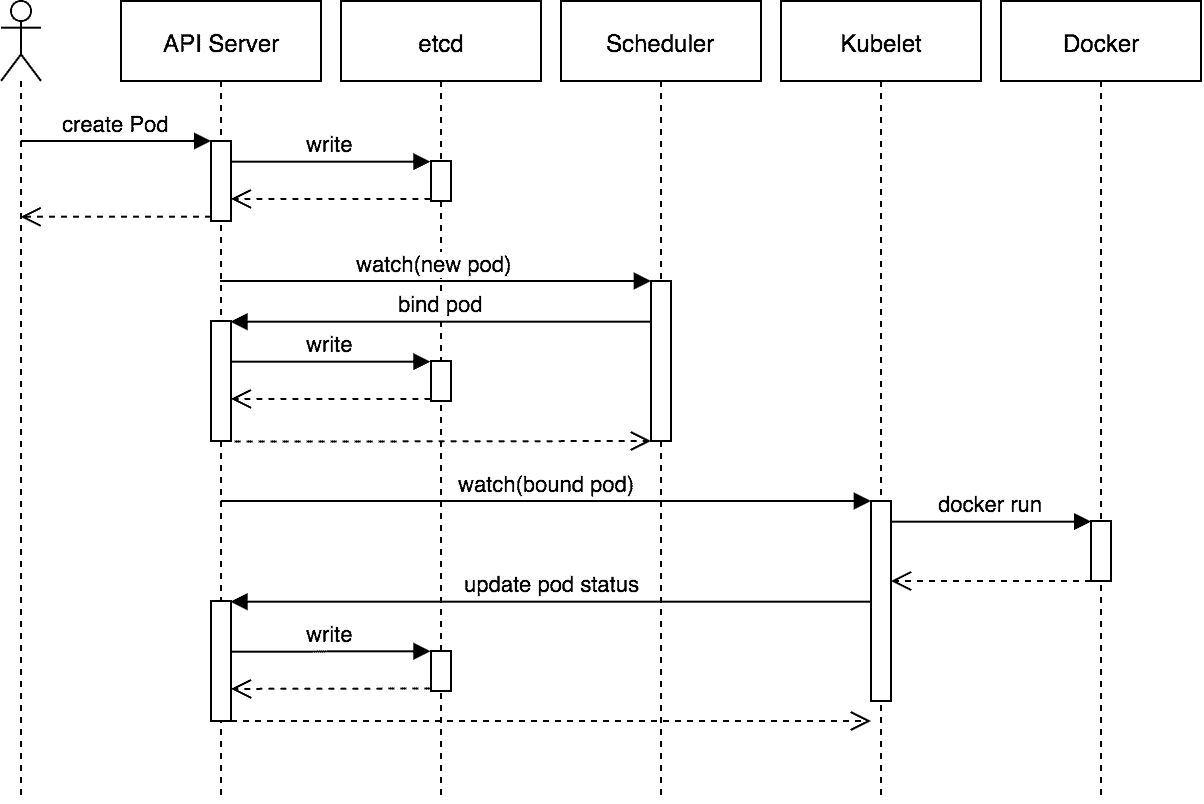
This sequence diagram shows how a typical flow works for scheduling a Pod. This shows the (somewhat rare) case where a user is creating a Pod directly. More typically, the user will create something like a ReplicaSet and it will be the ReplicaSet that creates the Pod.
The basic flow:
- The user creates a Pod via the API Server and the API server writes it to etcd.
- The scheduler notices an “unbound” Pod and decides which node to run that Pod on. It writes that binding back to the API Server.
- The Kubelet notices a change in the set of Pods that are bound to its node. It, in turn, runs the container via the container runtime (i.e. Docker).
- The Kubelet monitors the status of the Pod via the container runtime. As things change, the Kubelet will reflect the current status back to the API Server.
Summing up
By using the API Server as a central coordination point, Kubernetes is able to have a set of components interact with each other in a loosely coupled manner. Hopefully this gives you an idea of how Kubernetes is more jazz improv than orchestration.