

By Jeremy Eder, Red Hat, Senior Principal Software Engineer
Imagine being able to stand up thousands of tenants with thousands of apps, running thousands of Docker-formatted container images and routes, on a self healing cluster. Take that one step further with all those images being updatable through a single upload to the registry, all without downtime. We did just that on Red Hat OpenShift Container Platform running on Red Hat OpenStack on a 1000 node cluster, and this blog tells you how we deployed:
| Kubernetes Object | Quantity |
| Nodes | 1,000 |
| Namespaces (projects) | 13,000 |
| Pods | 52,000 |
| Build Configs | 39,000 |
| Templates | 78,000 |
| Image Streams | 13,000 |
| Deployment Configs and Services | 39,000 (Incl. 13,000 Replication Controllers) |
| Secrets | 260,000 |
| Routes | 39,000 |
The mission of the Cloud Native Computing Foundation (CNCF) is to create and drive the adoption of a new computing paradigm that is optimized for modern, distributed systems environments capable of scaling to tens of thousands of self healing multi-tenant nodes. That’s a great vision, but how do you get there?
The CNCF community is making the CNCF cluster available to advance this mission. Comprised of 1000 nodes, it provides a great utility to the open source community. It’s rare to come across large swaths of high-end bare metal, and over the last 8 weeks engineers at Red Hat have put the environment to great use to stress test our open source solutions for our customers.
Why OpenStack?
We were only granted 300 nodes of the 1000 at CNCF, and as we wanted to test scaling up to 1000 nodes, we made the decision to also deploy OpenStack. We deployed Red Hat OpenStack Platform 8 based on OpenStack Liberty to provide virtual machines upon which we would install Red Hat OpenShift Container Platform 3.3 (based on Kubernetes 1.3, and currently in beta).
OpenShift Container Platform on top of OpenStack is also a common customer configuration and we wanted to put it thru it’s paces as well. We’re looking forward to future testing scenario where we deploy OpenShift on a 1000 node cluster directly onto bare metal, and aim to write up a comparison of deployment, performance, and other issues in a future blog post here.
Many cloud native systems are moving toward being container-packaged, dynamically managed and micro-services oriented. That describes Red Hat OpenShift Container Platform (built on Red Hat Enterprise Linux, Docker and Kubernetes) to a tee. Red Hat OpenShift Container Platform and Red Hat OpenStack Platform are modern, distributed systems capable of deployment at scale.
This blog post documents the first phase of our ongoing testing efforts on the CNCF environment.
We were able to stand up thousands of tenants with thousands of apps, thousands of Docker-formatted container images, pods and routes, on a self healing cluster, that are all updatable with a single new upload to the registry — without taking downtime. It was glorious — a 1,000 node container platform based on the leading Kubernetes orchestration project, that can house an enormous application load from a diverse set of workloads. Even under these incredible load levels, we had plenty of head-room.
Hardware
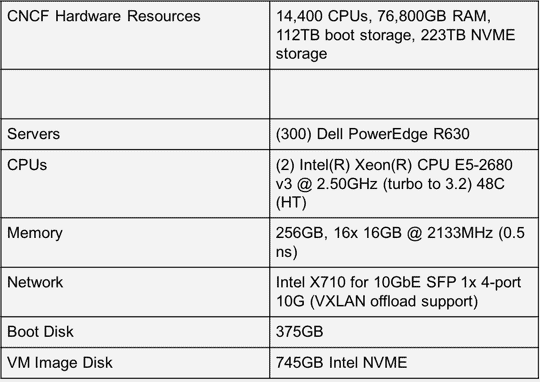
Software

Goals
- 1000 node OpenShift Cluster and Reference Design
- Push system to it’s limit
- Identify config changes and best practices to increase capacity and performance
- Document and file issues upstream and send patches where applicable
Inside the CNCF environment, Red Hat engineers deployed an OpenShift-on-OpenStack environment. Because of our previous experience with scalability and performance of both products, we first set out to implement an OpenStack environment that would meet the needs of the OpenShift scalability tests to be run on top.
We used three OpenStack controllers, and configured OpenStack to place VMs on the local NVME disk in each node. We then configured two host aggregate groups so that we could run two separate 1000-node OpenShift clusters simultaneously in order to parallelize our efforts. We configured Neutron to use VXLAN tunnels, and created image flavors to match our OpenShift v3 Scaling, Performance and Capacity Planning guide.
Here is a logical diagram of the environment. We deployed a single director (TripleO) node that also served as our jumpbox/utility node, and three OpenStack controllers which served images to the 300 OpenStack nodes from the image service (Glance).
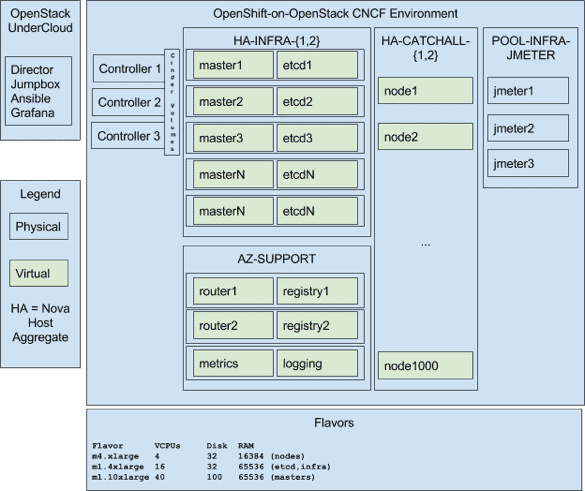
This deployment topology represents best practices for large scale OpenShift-on-OpenStack deployments.
To help speed installation and reduce burden on support systems (i.e. yum repos and docker registries), we pre-pulled the necessary OpenShift containers onto each node.
Standing up this cloud took less time and effort than anticipated, thanks in part to the open source communities around OpenStack, Ansible, and Kubernetes. Those communities are working to push, pull and contort these projects in every possible direction, as well as generate tools to make customers happy — the community around Ansible is incredibly helpful and fast moving.
Once we had the tenants, host aggregates, networks, and base images imported into glance, we were able to begin deploying OpenShift Container Platform. Here is an architectural diagram of what we built:
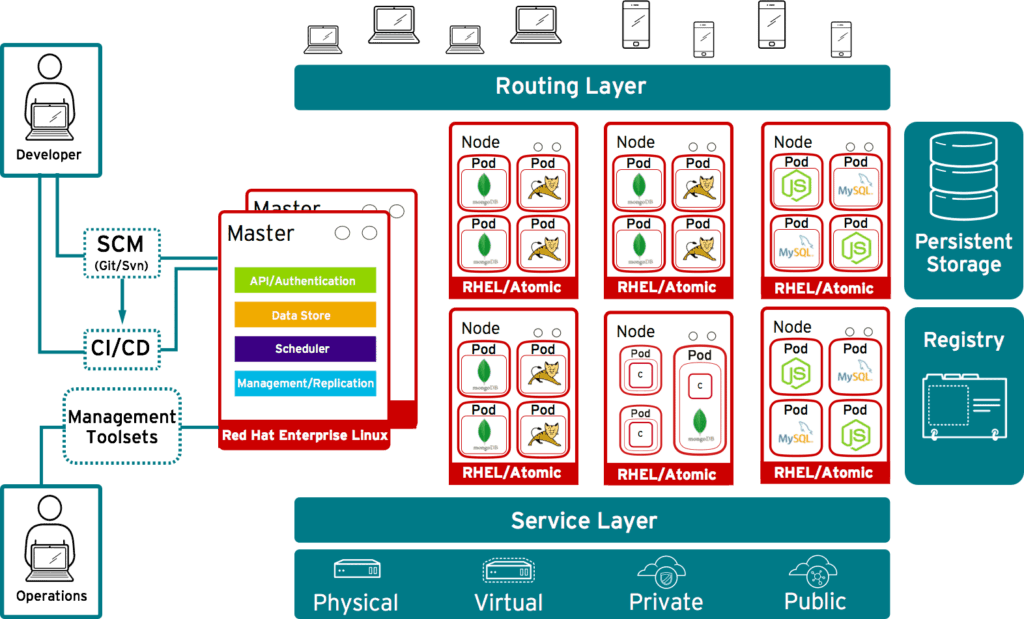
More concretely, we deployed the following inside each of the two host aggregates:
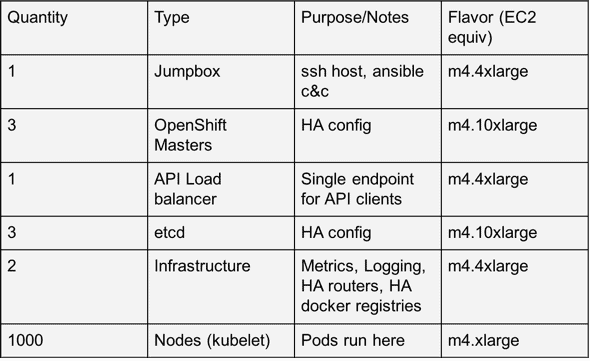

Workloads
To deliver on our main objectives to scale OpenShift up to 1000 nodes, Red Hat’s OpenShift performance and scalability team has written test harnesses (open source of course) to drive Kubernetes and OpenShift.
The primary workload utility we use to deploy content into an OpenShift environment is called the “cluster-loader“. The cluster loader takes as input a yaml file (that describes a complete environment as you’d like to to be deployed):
I’d like an environment with thousands of deployment configs (which include services and replication controllers), thousands more routes, pods (each with a persistent storage volume automatically attached), secrets, image streams, build definitions, etc.
Cluster-loader provides flexible, sophisticated and feature-rich scalability test capabilities for Kubernetes. You only need to vary the content of the yaml file to represent what you expect your environment to look like. If you have created templates for your own in-house application stack and have workload generators), it’s easy to point cluster-loader at them, and optionally feed them test-specific variables in the yaml config.
In addition to cluster-loader, we have also written application performance, network performance, reliability and disk I/O performance automation in the same repository.
The cluster-loader yaml configuration we used for the 1000-node test is below:
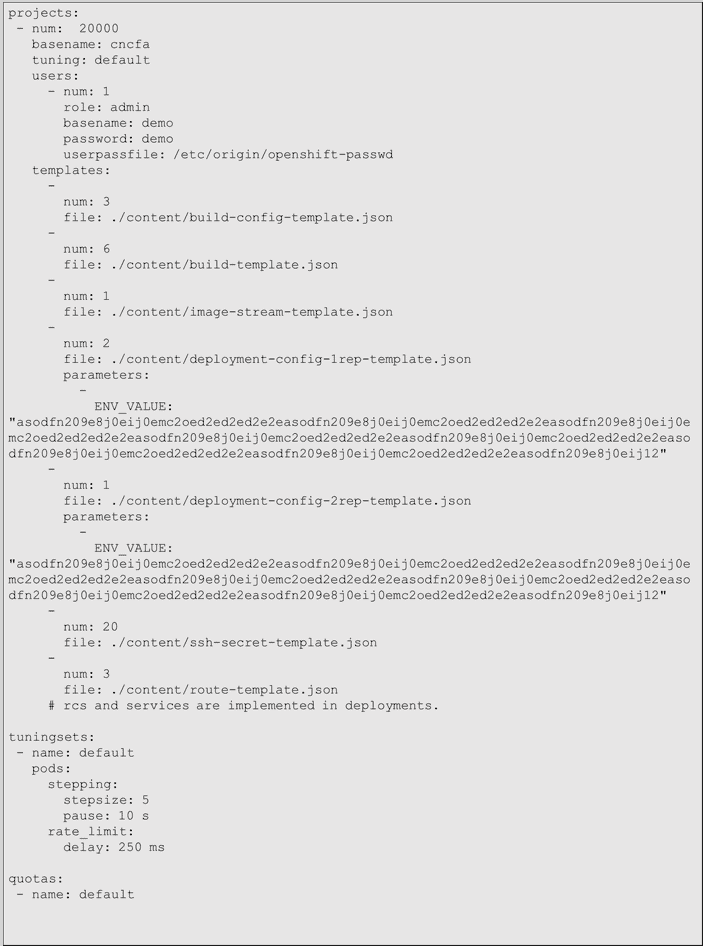
What this says is that we want to create:
- 20000 projects (namespaces), and within each project also create
- 1 user
- 3 build configs
- 6 templates
- 1 image stream
- 2 deploymentconfigs, each with a 256byte environment variable
- 1 deploymentconfig, with 2 replication controllers and a 256byte environment variable
- 20 secrets
- 3 routes
This config represents a reasonable mix of features used by developers in a shared web hosting cluster.
The last stanza of the configuration is a “tuningset” (our rate-limiting mechanism for the cluster-loader) where it’s creating 5 projects, waiting 250ms between each, and 10 seconds in between each step of 5. However due to the scale we were trying to achieve, this stanza was not used in this test.
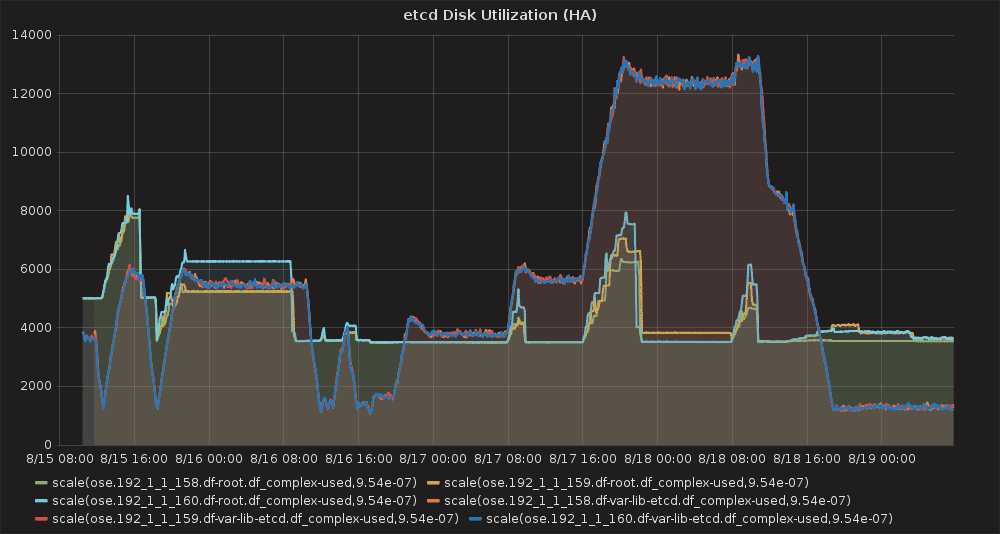
Because of the amount of Kubernetes “objects” this test run creates, we noted that etcd was using a fair amount of disk space, and thus our guidance for large environments has increased to 20GB (max during our test was 12.5GB, shown below).
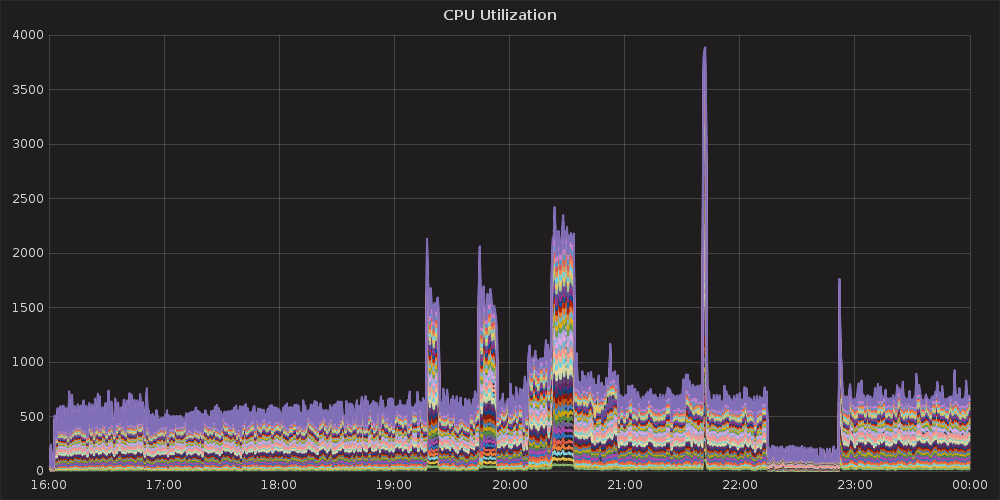
Another issue encountered during test runs was https://github.com/kubernetes/kubernetes/pull/29093 which you can see below as a cycle of panics/restarts of the kubernetes master service, occuring around 19:00 (approx 13,000 cluster-loader projects, 52,000 pods). This issue has already been resolved upstream and in the OpenShift 3.3 product.
A brief detour through Ansible
Somewhat surprisingly, our use of CNCF took a brief detour through ansible-land. The product installer for OpenShift is written in Ansible, and is great reference of truly sophisticated roles and playbooks in the field. To meet the needs of customers, OpenShift 3.3 includes Ansible 2.1, which adds advanced certificate management among other capabilities. As with any major version upgrade, lots of refactoring and optimization occurred not only inside Ansible but the in the OpenShift installer as well.
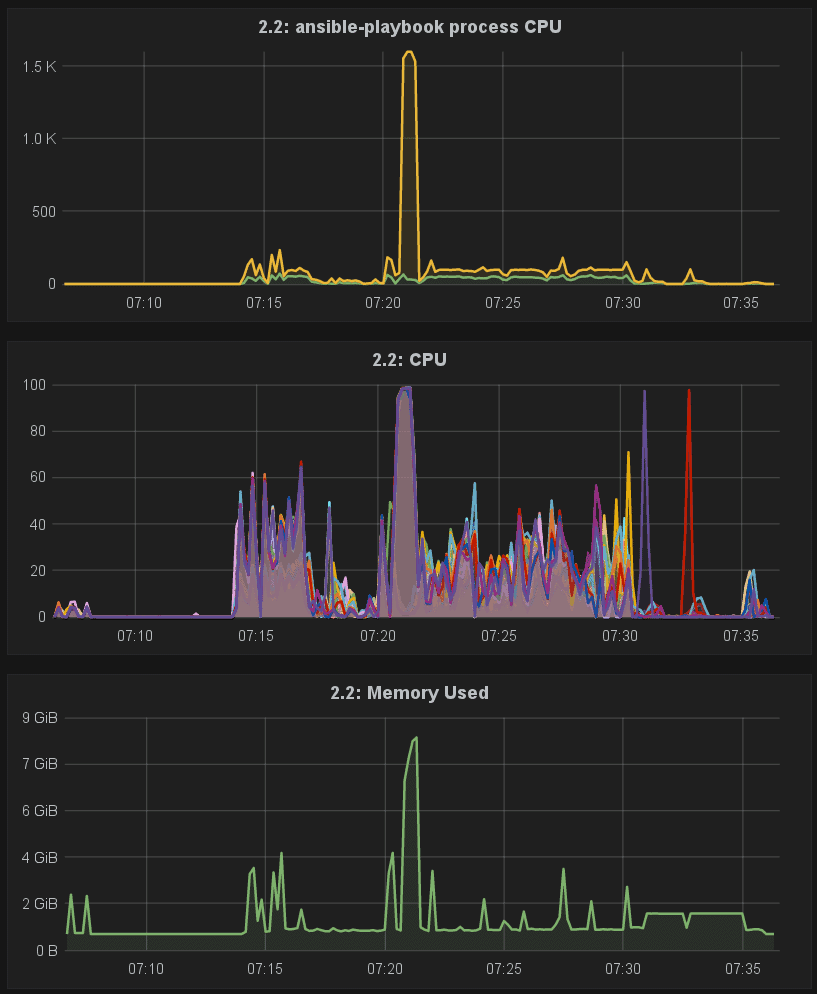
When we began scale testing the first builds of OpenShift 3.3 we first noticed that large installs (100+ nodes) took longer than they had in the past. In addition, we also saw Ansible’s memory usage increase, and even hit a few OOMs along the way.
We did some research, and found that users had reported the issue to Ansible a few weeks earlier, and work was underway to resolve the issue. We collaborated with James Cammarata and Andrew Butcher from Ansible on performance optimizations to both Ansible core, as well as how OpenShift used it.
With the updated code merged into Ansible and OpenShift, 100-node Installs of the OpenShift 3.3 alpha were now back to normal — around 22 minutes, and were down to the expected memory usage, in-line with the resource requirements of Ansible 1.9.
Summary
Working with the CNCF cluster taught us a number of important lessons about some key areas where we can add value to Kubernetes moving forward, this includes:
- Adding orchestration-level support for additional workloads,
- Moving aggressively to a core+plugin model,
- Working on more elegant support for high performance workloads
- and continuing to refine developer-friendly workflows that deliver on the promise of cloud-native computing.
Benchmarking on CNCF’s 1000 node cluster provided us with a wealth of information. While there were some teething pains as we brought this new lab gear online, we worked very closely with Intel’s lab support folks to get our environment successfully deployed. We’ll be sending in a Pull Request soon to cncf/cluster, continuing testing out bare metal scenarios and posting the results in a follow blog post (Part 2).
Want to know what Red Hat’s Performance and Scale Engineering team is working on next? Check out our Trello board. Oh, and we’re hiring!
Follow us on Twitter @jeremyeder @timothysc @mffiedler @jtaleric @thejimic @akbutcher