Project post cross-posted on the Argo blog by Savin Goyal
Yesterday, we released first-class support for Kubernetes as an alternative to AWS-native service integrations in Metaflow. Data scientists can scale out compute to Kubernetes clusters and schedule flows to be executed by Argo Workflows. To get started, read our deployment guide for Kubernetes.
Since the early days of Metaflow, we have believed that data science and machine learning projects should have a frictionless path from prototype to production. This is easier said than done, as the requirements for a delightful prototyping experience are so different from those of production deployments.
We know that prototyping benefits from quick iterations with a human in the loop, whereas production requires scalable, highly available operations with minimal human intervention. Correspondingly, the systems and tools enabling rapid experimentation are fundamentally different from the modern production infrastructure.
We believe that it would be counterproductive to hide the distinction which exists for many valid technical and organizational reasons. A better approach is to make it easy for the data scientists to move between the two worlds.
The Gradual Path to Production
When a project graduates from the confines of a data scientist’s laptop to production, it must be prepared to play nicely with the company’s overall engineering infrastructure. Gone are the days when data science projects could stay inside walled gardens that were purpose-built for small-scale experimentation. The sooner you integrate projects into the rest of the infrastructure, the faster you can start delivering actual business value which should be a key objective of every data science project in the industry.
Following this ethos, Metaflow encourages projects to become increasingly production-ready by going through the following stages:
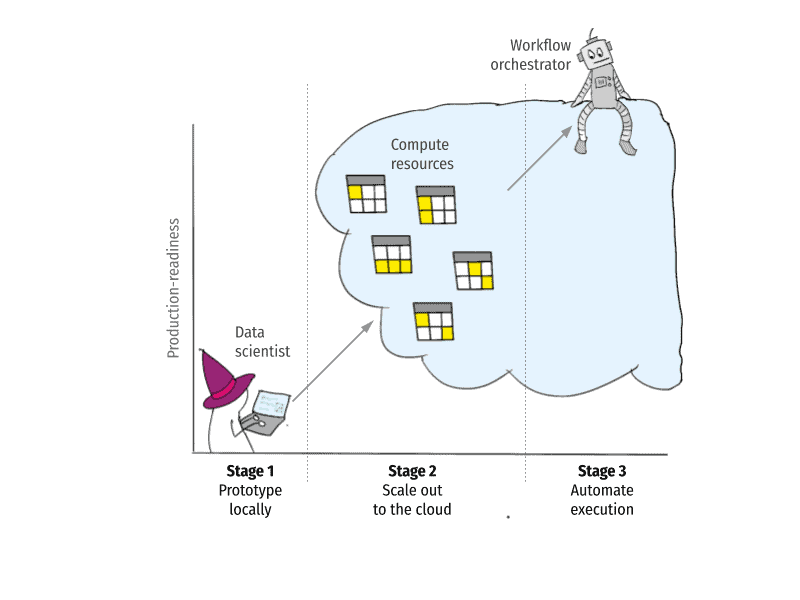
In the first stage, the data scientist prototypes a project on a personal workstation. Metaflow allows them to build and test workflows locally, making sure that no re-implementation or re-architecting is needed when the project is ready to advance to the next stage.
Once Metaflow has been configured to integrate with the company’s cloud infrastructure, often with help from the engineering team, the project can advance to the second stage. Without any changes in the code, the data scientist can test their workflow with much larger scale data and compute, leveraging cloud-based compute resources.
Finally, once the project has proven to work at scale, it can be deployed to a production-grade workflow orchestration system which takes care of keeping the workflow running in a highly-available manner, tightly integrated with the surrounding production systems. At this stage, the project is solidly in production: Models are retrained regularly and fresh predictions are produced without any human intervention.
Human-Centric Data Science on AWS
When Netflix open-sourced Metaflow in 2019, we provided a graduation path using services provided by Amazon Web Services:
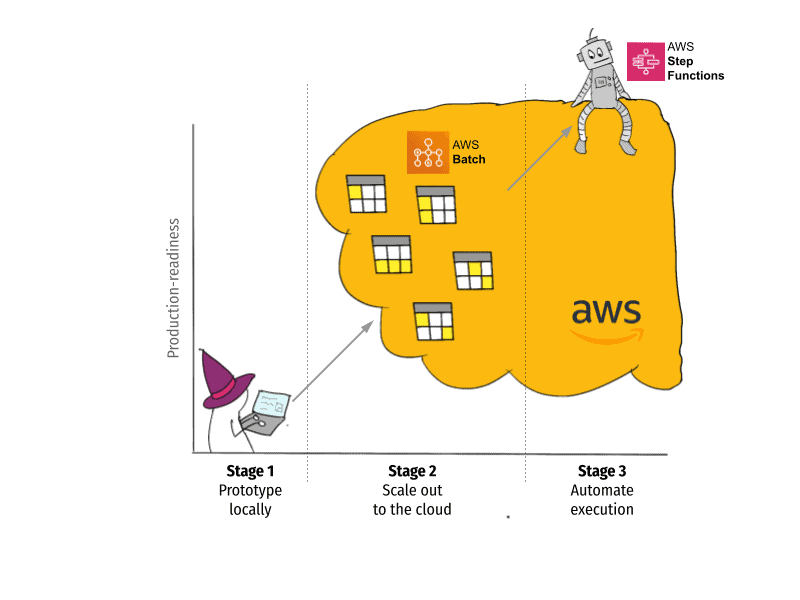
AWS Batch provides a straightforward solution for the second stage. It takes care of launching EC2 instances on the fly whenever a data scientist wants to scale out to the cloud. AWS Batch is easy to set up, it has minimal operational overhead, and no extra cost over the standard EC2 pricing, which makes it a great choice for teams who want to benefit from cloud computing with minimal hassle. The data scientist can simply execute run --with batch to scale out their projects to the cloud.
For production deployments, AWS provides another solid service, AWS Step Functions, which keeps workflows running without any human intervention, and with minimal engineering headache. The data scientist can simply execute step-functions create to deploy their project to production.
In general, these AWS services are a great choice for companies that are already using AWS and want to provide the three-stage graduation path for projects with minimal operational overhead.
New: Metaflow on Kubernetes
The biggest benefit of the AWS-native path — its simplicity — can also be its biggest weakness. While many companies are happy with this path, over the past years we have heard from many large organizations that their infrastructure needs are more demanding and they need more flexibility on their graduation path.
Today, the platform that provides nearly an infinite amount of flexibility for engineers to build custom infrastructure is Kubernetes. Kubernetes is to engineering and data science what flour is to bread. You are not supposed to consume it as such but you can use it as an ingredient to bake something delicious (although it takes some skill and effort):
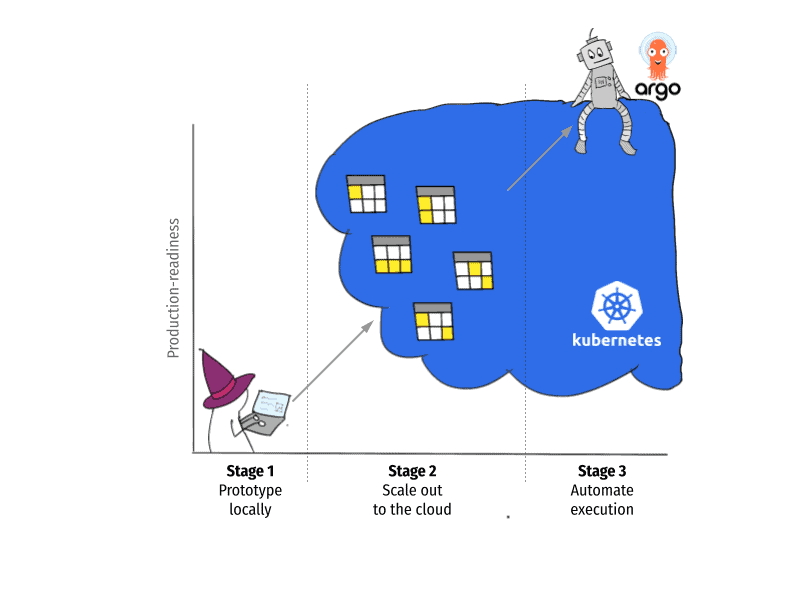
This characteristic makes Kubernetes a great solution for organizations that need more flexibility with their infrastructure than what the AWS-native path can afford. Today, we are happy to announce that Metaflow supports the Kubernetes path natively, as an equal alternative to the AWS-native path:
It is worth emphasizing that the benefits of Kubernetes are targeted at engineers, not data scientists who don’t have to care about the underlying infrastructure when using Metaflow. The data scientist can write their flows as usual and scale-out to the company’s Kubernetes cluster simply by executing run --with kubernetes. In fact, any flow that you used to run --with batch can now be run --with kubernetes without any changes in the code!
The flexibility of Kubernetes is also its biggest drawback: Kubernetes is a complex ecosystem of a myriad of tools and approaches. The Metaflow-Kubernetes integration doesn’t make too many assumptions about how your cluster is configured. Still, operating a production-grade Kubernetes cluster tailored for your ML workloads can require making a lot of choices, tradeoffs, and engineering efforts.
We provide a baseline Terraform configuration that allows you to deploy Metaflow-ready Kubernetes resources on the AWS-managed Kubernetes service, EKS with a few commands but we anticipate that most serious organizations want to customize their security policies, autoscaling policies, and observability systems. If you are curious to learn how, join our Slack to chat about best practices.
New: Metaflow on Argo Workflows
To support production-grade workflow orchestration natively on Kubernetes — stage 3 — we turned into Argo Workflows. Argo Workflows is arguably the most popular Kubernetes-native workflow orchestrator which, amongst other use cases, powers Kubeflow Pipelines under the hood.
Argo Workflows checks all the boxes we require from a production-grade orchestrator: It scales well, it is highly available, and it has an excellent UI to help with observability. Similar to Kubernetes, it is not a tool that a data scientist should need to use directly, but it provides a powerful backend for a human-centric tool like Metaflow.
To benefit from Argo Workflows, a data scientist needs to know only a single command: argo-workflows create. The command schedules the workflow for automated execution on production-grade Kubernetes infrastructure without any changes in the scientist’s Python code.
To get an idea of what the graduation path looks like on Kubernetes, including Argo Workflows, take a look at the short screencast below (no sound):https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2FmscaF4KrMDY%3Ffeature%3Doembed&display_name=YouTube&url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DmscaF4KrMDY&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2FmscaF4KrMDY%2Fhqdefault.jpg&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=youtubeMetaflow on Kubernetes & Argo Workflows
The Metaflow-Argo Workflows integration was originally started by SAP, a quintessential example of a large organization with demanding infrastructure needs. Here’s how Roman Kindruk at SAP, who has been closely involved in the integration project describes their motivation for using Argo Workflows with Metaflow:
Our data scientists appreciate the simple, straightforward Python interface provided by Metaflow. At the same time, our engineers are deeply committed to using Kubernetes and Argo Workflows, so we wanted a solution that provides the best of both worlds. We are excited to see that a humble pull request we started a while ago has evolved into a first-class support for Argo Workflows and Kubernetes in Metaflow!
Roman Kindruk / SAP
After SAP’s initial contribution, we worked closely with the Argo Workflows community to make sure the integration aligned with their long-term roadmap. Yuan Tang, a maintainer of Argo Workflows, commented:
We have been very happy to work with the Outerbounds team to provide a first-class integration between Metaflow and Argo Workflows. We are committed to making sure that Argo Workflows is the most robust and scalable workflow orchestrator on Kubernetes, capable of satisfying the needs of even the most demanding organizations.
Yuan Tang / Argo Workflows & Akuity
Today, after over a year of extensive development, testing, and validation, the integration passes our high bar of production readiness. We are happy to invite you to deploy it in your environment and give it a try!
Next Steps
If you want to make your existing Kubernetes infrastructure easily accessible by data scientists, Metaflow is a great choice. They can rely on Kubernetes to scale out their projects and deploy to production confidently without being exposed to the complexities of modern infrastructure.
To get started, take a look at the Deployment Guide for Kubernetes. If you are wondering whether the AWS-native or the Kubernetes path is right for you, join the Metaflow support Slack for more information and guidance. In either case, your feedback and feature requests are highly appreciated!