Guest post by Evan Powell, CEO at MayaData
Or, how can cloud services not be cloud-native?
KubeCon EU was great in many ways. One pleasant surprise is that because KubeCon was a virtual event, this led to me having more conversations with various storage vendors and projects than I have had at prior KubeCons. The KubeCon storage channel pulled together a lot of smart vendors generally cooperating in trying to unpack issues for end-users; I was inspired and tried to do my part to keep up.
That’s where this thread kicked off, and as the original author of the Container Attached Storage (CAS) definition, it only made sense to follow up with a blog for the broader community.
The question that triggered this update came from an engineer at a traditional storage vendor who asked – I’m paraphrasing a bit: “so if loosely coupled is so important to cloud native architectures, does that mean that relying on a given cloud is itself not cloud native? In other words – can cloud services themselves not be cloud native?” To which I had to answer – yes – but there is more to the story.
Reminder – what is CAS?
Container Attached Storage is a pattern very much in line with the trend towards disaggregated data and the rise of small, autonomous teams running small, loosely coupled workloads. In other words, my team might need Postgres for our microservice, and yours might depend on Redis and MongoDB. Some of our use cases might require performance, some might be gone in 20 minutes, others are write intensive, others read intensive, and so on. In a large organization, the tech that teams depend on will vary more and more as the size of the org grows and as organizations increasingly trust teams to select their own tools. Kubernetes supports this pattern – sometimes discussed as a data mesh and the rise of polyglot data – which has been written about by Zhamak Dehghani from ThoughtWorks and others[1].
Some good sources to learn more about CAS include:
- The blog in which I originally coined the term CAS on the CNCF’s site back in April of 2018: https://www.cncf.io/blog/2018/04/19/container-attached-storage-a-primer/
- July’s CNCF webinar by the leader of the OpenEBS project, Kiran Mova: https://www.cncf.io/webinars/kubernetes-for-storage-an-overview/
Here’s a canonical image from Kiran’s community webinar, with some explanation:
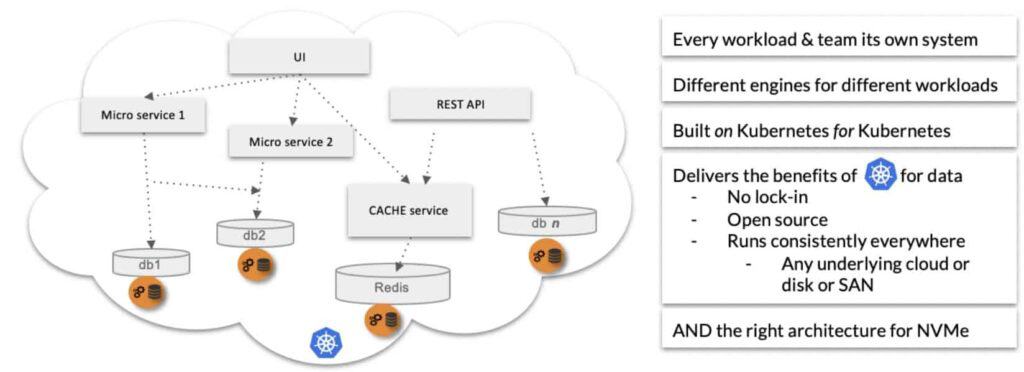
CAS means that devs can work without worrying about the underlying requirements of their org’s storage architecture. To CAS, a cloud disk is the same as a SAN which is the same as bare metal or virtualized hosts. We don’t have meetings to select the next storage vendor or to argue for settings to support our use case, we spin up our own CAS containers with whatever storage or localPV management we need, and just keep moving.
OK, ^^ that’s CAS, but what’s not cloud-native about the cloud?
One overlooked aspect of Kubernetes is that it was originally created to ensure we can run clouds in a cloud native way. Let me try to explain.
Before Kubernetes it was extremely difficult to declare an intent and know that it would be executed irrespective of the underlying operating environment, whether on-premise or cloud A, B or C. Instead enterprises were counseled to pick one of the major clouds – and to double down on their expertise and relationship with that cloud.[1]
As such the entire organization and all of the software they were writing implicitly depended on that cloud and therefore were coupled to that cloud. This tight coupling generally didn’t matter, until it did. Only organizations such as Netflix that had both architected their systems to work around the vulnerabilities of AWS and that proactively and relentlessly validated their resilience via chaos engineering were able to survive various AWS outages[2]. Presumably their ability to move at least some of their workloads such as their Spinnaker based CI/CD also helps them negotiate better pricing with AWS.
In short, if you take the definition of cloud native as being able to survive outages from the underlying cloud, being tightly coupled to the cloud is itself an anti-pattern.
Awareness of the risks and impedance challenges of this tight coupling is part of why Kubernetes has become one of the most important open-source projects of our time. And, here is where things get a little sensitive for a traditional shared everything storage hardware vendor, that logic applies doubly for the systems that they sell.
If you want to build loosely coupled systems, just as you cannot simply run on one cloud and only that cloud, you also cannot assume that a storage system that claims to scale to thousands of nodes will work in all cases.
If we accept the built to fail mantra at the heart of cloud native, we must acknowledge that shared everything storage will break. It will behave in ways that are not optimal for each team’s workload. It will behave in a non-Kubernetes native way, and all these dependencies introduce risk into our environment that is beyond our control and that is opaque to our teams.
OK – so what’s new in CAS?
When CAS first emerged it was used, not surprisingly, for less mission-critical workloads. Great examples include all manner of “semi-permanent” workloads, where you want the data to be retained for the duration of a CI/CD run or for some data science work and then you want it blown away. For these examples, it is really important that CAS enables the workload to spin up and down quickly and consistently. A second and also important requirement is that CAS behaves the same way, irrespective of the underlying environment.
When Kubernetes schedules workloads, even fairly typical thirty-second EBS attach times, add up if it is a 5-minute run and you run it dozens of times a day. You can see this pattern on the early OpenEBS adopters list where earlier public references tended to skew towards relatively short duration workloads.
Longer duration workloads on Kubernetes were dealt with a couple of years ago in one of two ways.
- either via a managed service from a cloud
or - a NoSql database that adds an additional level of resilience.
At first we thought CAS wouldn’t apply in either case since traditional shared everything storage certainly does not; however, we fairly quickly realized that NoSQL databases and solutions like Kafka could use help in what we call dynamic LocalPV.
By maintaining awareness of the underlying environment, including what cloud volumes and physical disks are available, CAS solutions like OpenEBS’s LocalPV lower the operational effort of running these workloads on Kubernetes. CAS solutions do so in a way that reduces lock-in or a dependency on a given underlying cloud or storage system.
The First New CAS Requirement
So, we can update the CAS definition accordingly. We now know that CAS solutions need to include LocalPV support. So too then, do the associated Kubernetes operators that help in running Data applications using Local PV.
More recently, though, we’ve seen a rise in many workloads for which local node performance is important.
Perf issues can, again, be addressed via the use of LocalPV. One challenge is that many of these workloads now require both performance and multi-node HA. Just backing the node up via Restic or some other project or product is not enough.
Consider high performance workloads running on PostgreSQL or MySql – for example your Magento running on MySql. Just backing the data up is not enough, MySql typically expects to be able to access data on another node immediately. Perhaps not surprisingly, many of these workloads predate the cloud. Traditional SQL such as MySql, PostgreSQL, and others are almost always deployed with failovers and replicas. Sometimes these traditional workloads are even pulled together via Kafka or similar to deliver a unified data mesh as discussed in the ThoughtWorks article referenced above. The dream is to provide for the enterprise concerns such as learning from all of the data, while also allowing for autonomy and agility of small independent teams.
The Second New CAS Requirement
So, we can update the CAS definition in a second way. We now know that CAS solutions need to include multi-node HA at LocalPV speed.
The only problem with that requirement is that there are so far very few solutions that can address the requirement. The only CAS solution that I’m aware of that’s working towards meeting this requirement is OpenEBS Mayastor; which, will reach beta in 0.4 in September of 2020.
The Third and Fourth Additional CAS Requirements
A third update follows logically from these two updates. CAS solutions should be cloud native in their architecture. CAS must offer multiple approaches to storing data if we’re going to succeed in supporting all types of workloads, such as LocalPV for NoSql workloads and high performance with resilience for many performance sensitive deployments of PostgreSQL and similar.
In the case of OpenEBS, the project leverages a cloud-native architecture to deliver no fewer than 4 “data engines” (more if you count all the different flavors of LocalPV that are available). Earlier CAS solutions were much more monolithic in nature. I believe all CAS needs to be built with the idea of Kubernetes as a substrate enabling a pluggable and non monolithic architecture.
Lastly, open source seems to be table stakes. Reasonable people can disagree about this point as there are some obvious early contributors to the CAS pattern that rely on proprietary software. However, proprietary software introduces a vendor dependency that is in conflict with the “portability” ethos inherent in cloud native.
In summary, having learned from thousands of Container Attached Storage users we can confidently say that the definition of CAS should be expanded to include:
- CAS must support pass-through mode (what we call LocalPV in the Kubernetes ecosystem)
- CAS must support multi-node HA at LocalPV speed
- CAS software should be cloud native in architecture – supporting multiple data engines depending on the workload
- CAS should be open source to avoid introducing vendor dependencies.
Conclusion
Over the last few years, we’ve seen a tremendous outpouring of feedback and support from the broader cloud native community grappling with how to get the best out of Kubernetes and cloud native approaches while working with data. We had to give to get. And, I’m happier than ever that MayaData donated OpenEBS to the CNCF. It was natural for us to follow it up by donating Litmus, as well, for chaos engineering with a particular focus on stateful workloads. We’re extremely proud that MayaData is the 5th leading contributor to CNCF projects overall as of late August 2020 according to this DevStats report from the CNCF: https://all.devstats.cncf.io/d/21/prs-authors-companies-table?orgId=1.[3]
Recently we helped to start the Data on Kubernetes community as a project and vendor-neutral space in which to discuss operators, databases, use cases, and much more. Engineers from leading Kubernetes using organizations like Optoro and Arista have spoken recently, as have projects such as Kafka / Confluent and Cassandra / DataStax. All are welcome and encouraged to get in touch with the independent organizers to participate however you’d like.
CAS is now seen as a key piece of transforming Kubernetes into a data plane. CAS complements underlying cloud storage services, on-premise CSI accessible storage, or even raw disks and memory available in local nodes.
Our experience with CAS (and especially OpenEBS) has shown users have become familiar with the pattern. The new requirements for CAS reflect this growth and maturity of the model.
I am excited about where the next few years will take us. How will our requirements evolve as we explore more data-intensive workloads on Kubernetes? Whatever it is, we’re eager to find out along with you. At MayaData we are here to listen, and to continue evolving the CAS pattern to meet new demands.
[1] EP: Yes automated server munging existed and there was the idea that configuration management + virtualization could lead to cloud independence and great agility but – it didn’t quite work out.
[2] https://netflixtechblog.com/lessons-netflix-learned-from-the-aws-outage-deefe5fd0c04
[3] By the way – devstats and other workloads at the CNCF and the Linux Foundation run on OpenEBS. Please see their adopters story here: https://github.com/openebs/openebs/blob/master/adopters/cncf/README.md
[1] https://martinfowler.com/articles/data-monolith-to-mesh.html